Protobuf编码
Posted jialin0x7c9
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Protobuf编码相关的知识,希望对你有一定的参考价值。
Varint编码规则:
在一个字节的8位里用低7位存储数字的二进制补码,第一位为标识位(most significant bit--msb)用来表示下一个字节是否还有意义,是否要继续读取下一个字节。
二进制补码的低位排在编码序列的前头(逆序是以7位一组逆序)。这个办法是为了少存0节省空间,同时也是为了方便移位运算。
举个例子:
int a = 1; 数字1的二进制补码表示为: 0000 0000 0000 0000 0000 0000 0000 0001 使用varints编码后为: 1.以7位1组为单位逆序: 000 0001 000 0000 000 0000 000 0000 0000 2.第一位高位判断是否需要拼接下一个字节来表示数字1,这里不需要,所以只需一组最高位补0 0000 0001 0000 0000 0000 0000 0000 0000 3.故数字1的vriant编码: 0000 0001 十六进制表示为: 0x01
举个复杂的例子:
int a = 251; 数字251的二进制补码表示为: 0000 0000 0000 0000 0000 0000 1111 1011 使用varint编码: 1.以7位1组单位逆序: 111 1011 000 0001 0000 0000 0000 0000 00 2.7位1组,第一位高位为msb表示是否需要下一个字节,这里第一个字节需要下一个字节,故第一个字节补高位为1。第二个字节不需要第三个字节了,故第二个字节补高位为0 1111 1011 0000 0001 0000 0000 0000 0000 00 故数字251的varint编码为: 1111 1011 0000 0001 十六进制表示为: 0xFB01
由此可见Varint编码方式通过逆序存储补码以及牺牲每一个字节的最高位用来表示是否需要读取下一个字节,可以将4字节的整数类型压缩至2个字节存储。
但是因为4个字节中每个字节都少了一个bit位,因此采用Varint编码4个字节能表示的最大数字就是228-1了而不再是232-1。
因此当数字大于228-1时,采用Varint编码将需要5个字节,编码效率反而下降。但是根据统计学的概率,大多数情况下不会用到这么大的数字,因此采用Varint整体效率还是高的。
另外还有一种是负数的情况
由于负数在计算机中天生占据最高位为1,因此假如还是采用Varint编码方式来编码-1
int a = -1; 数字-1的二进制补码表示为: 1111 1111 1111 1111 1111 1111 1111 1111 使用varint编码: 1.以7位1组单位逆序: 111 1111 111 1111 111 1111 111 1111 1111 2.7位1组,第一位高位为msb表示是否需要下一个字节。 1111 1111 1111 1111 1111 1111 1111 1111 0111 1000 故数字251的varint编码为: 1111 1111 1111 1111 1111 1111 1111 1111 0111 1000 十六进制表示为: 0xFFFFFFFF78
原本负数只需4个字节就能表示,但是采用Varint编码以后居然需要5个字节,效率不升反降。聪明的大神们为了尽可能压榨每一寸空间绝对不会这么干的。
于是针对负数类型,protobuf内指定了sint32和sint64来存储,采用的是ZigZag编码的方式。
ZigZag编码
ZigZag 编码:有符号整数映射到无符号整数,然后再使用 Varints 编码
既然负数的编码效率低,那么在ZigZag编码方式中。将负数映射为对应的正数,再采用Varints编码。解码时,解出是正数以后再根据映射关系映射回负数即可。
ZigZag编码的映射关系:
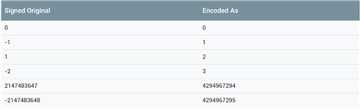
不过ZigZag的映射关系不是采用映射表来实现的,而是移位来实现。
Zigzag(n) = (n << 1) ^ (n >> 31), n为sint32时
Zigzag(n) = (n << 1) ^ (n >> 63), n为sint64时
举个例子:
uint32 a = -1; -1的二进制编码: 1111 1111 1111 1111 1111 1111 1111 1111 n << 1后为: 1111 1111 1111 1111 1111 1111 1111 1110 n >> 31后为: 1111 1111 1111 1111 1111 1111 1111 1111 故(n << 1) ^ (n >> 31)后为: 1111 1111 1111 1111 1111 1111 1111 1110 1111 1111 1111 1111 1111 1111 1111 1111----两行执行不进位的半加操作 0000 0000 0000 0000 0000 0000 0000 0001 故:Zigzag(-1) = 1;
Protobuf是如何采用Varint和ZigZag编码的:
protobuf对message的所有字段的二进制编码结构如下图所示:
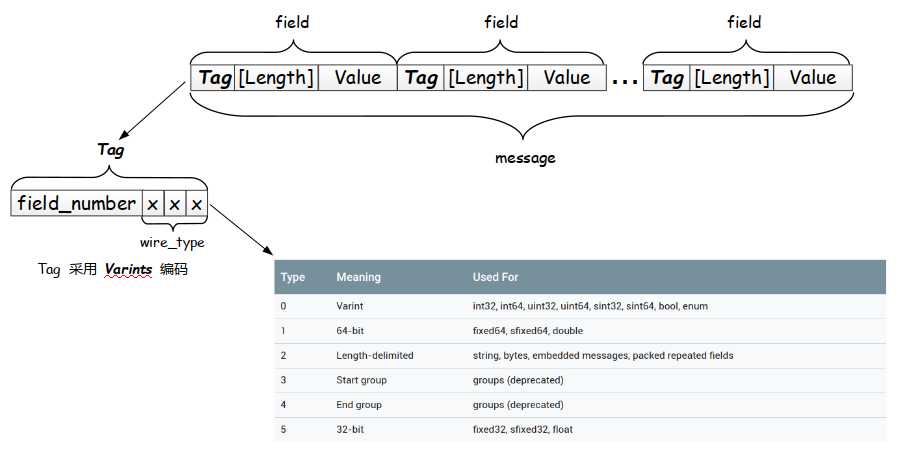
message由一个个字段组成,每一个字段(包含编号和值)在二进制编码的时候对应上图的field。
每个二进制field的结构由Tag-[Length]-Value组成。这里的[Length]是否需要是依据Tag的最后三位wire_type来决定的。
Tag的结构如下图所示:其中field_number就是字段的编号。整个Tag也是采用Varints编码的。
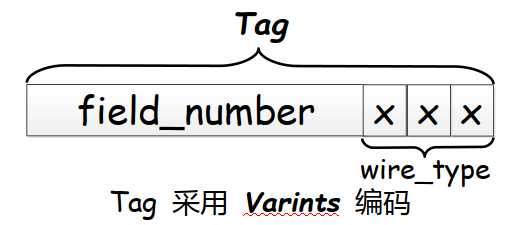
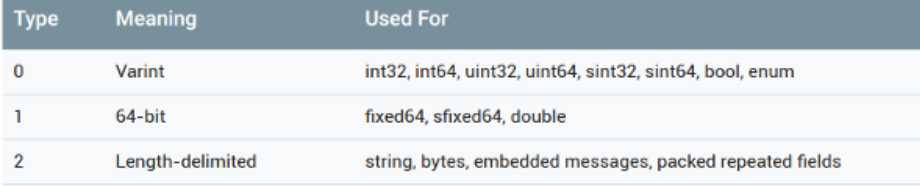
wire_type由三位bit构成,故能表示8种类型。
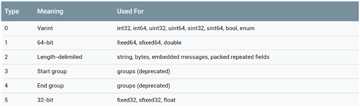
1.当wire_type等于0的时候整个二进制结构为:
Tag-Value
value的编码也采用Varints编码方式,故不需要额外的位来表示整个value的长度。因为Varint的msb位标识下一个字节是否是有效的就起到了指示长度的作用。
2.当wire_type等于1、5的时候整个二进制结构也为:
Tag-Value
因为都是取固定32位或者64位,因此也不需要额外的位来表示整个value的长度。
3.当wire_type等于2的时候整个二进制结构为:
Tag-[Length]-Value
因为表示的是可变长度的值,需要有额外的位来指示长度。
Protobuf2语法规则:
从一个简单例子开始:
message Test{ required string name = 1; optional int32 phonenum = 2;
repeated int32 other = 3; }
一、指定字段规则:
1.required:指定了该规则后必须给该字段赋值,否则执行后protobuf会报错abort

2.optional:该字段可被赋值或可不赋值;
3.repeated:该字段可出现0次或者多次;
二、指定字段的类型
double、float、uint32、uint64、bool、string、bytes、uint32、uint64、
int32、int64:如果负数指定这两个类型编码效率较低。负数应该使用下面的类型。
sint32、sint64:对负数会进行ZigZag编码提高编码效率。
fixed32、fixed64:总是4字节和8字节
sfixed32、sfixed64:总是4字节和8字节
因为采用Varint编码4个字节能表示的最大数字就是228-1了,超过这个值就需要5个字节来表示。因此对于大于228-1的数,采用固定长度fixed32或者fixed64的效率会更高。
三、protobuf编码实例
第一个例子:理解int32和fixed32的编码和解码方式
message Test { required int32 num1 = 1; required fixed32 num2 = 2; }
编写好Test.proto文件,利用protobuf编译器生成Test.pb.h和Test.pb.cc文件:
protoc -I=. --cpp_out=. ./Test.proto
编写main.cc文件:
#include <iostream> #include "Test.pb.h" #include <string> #include <fstream> using namespace std; int main() { string fileName = "BinaryResult"; Test a; a.set_num1(10); a.set_num2(1073741824); fstream output(fileName.c_str(), ios::out | ios::trunc | ios::binary); a.SerializeToOstream(&output); return 0; }
编译main.cc文件并运行:
g++ main.cc Test.pb.cc -lprotobuf
查看输出的文件
vim -b BinaryResult
以十六进制查看二进制文件
:%!xxd
二进制文件为:
十六进制表示为:
080a 1500 0000 40 二进制表示为: 0000?1000000010100001010100000000000000000000000001000000?
现在我们对这个二进制进行解码流程看是否能还原出10和1073741824这两个值。
解码的结构如图:

第一个字段的Tag解码:
由于Tag也是采用Varint编码的因此最开始依据第一个msb位读取第一个字节(00001000)为第一个字段的Tag,最后3位(000)表示wire_type=0指示了接下来Value的编码采用Varint方式。剩余5位(00001)表示field_number=1表示第一个字段的编号为1;
第一个字段的Value解码:
由wire_type=0可知Value是采用Varint编码。故读取下一个字节(00001010),该字节的第一位msb位为0。故接下来的7位(0001010)表示第一个字段的值。因为只有一个字节因此逆序还是0001010,二进制0001010表示数字为:10
第一个字段解码完成。
第二个字段的Tag和Value解码:
由同样的办法得第二个字段field_numer=2,wire_type=5。wire_type=5对应fixed32类型的编码方式。
fixed32类型的编码方式因为已经固定取32位,因此不需要msb位。但为了移位方便,还是有按字节逆序编码。因此解码的时候也要逆序回来。
fixed32的编码如下: 00000000 00000000 00000000 01000000 按字节逆序回来: 01000000? 00000000 00000000 00000000 二进制表示的值为:?1073741824?
第二个字段解码完成。
第二个例子:理解Tag-Length-Value的编码方式
message Test { required string name = 1; }
main.cc
#include <iostream> #include "Test.pb.h" #include <string> #include <fstream> using namespace std; int main() { string fileName = "BinaryResult"; Test a; a.set_name("Steven"); fstream output(fileName.c_str(), ios::out | ios::trunc | ios::binary); a.SerializeToOstream(&output); return 0; }
编译运行,输出的二进制文件为:
十六进制: 0a06 5374 6576 656e 二进制表示为: ?0000101000000110010100110111010001100101011101100110010101101110?
解码结构如下图:

Tag-Length-Value方式的结构解码:
由上图wire_type(010)=2可知接下来的解码形式应该是Length-Value:
以Varint编码的方式读取Length(00000110)=6指示接下来的Value占据6个字节。
二进制: 010100110111010001100101011101100110010101101110? 得到ASCII码: 83 116 101 118 101 110 对照ASCII码表得到的字符串为: Steven
Tag-Length-Value编码方式的解码流程如上。
第三个例子:理解Tag-Length-Value-……-Value的编码方式
message { repeated int32 num = 1 [packed=true]; }
main.cc文件:
#include <iostream> #include "Test.pb.h" #include <string> #include <fstream> using namespace std; int main() { string fileName = "BinaryResult"; Test a; a.add_num(10); a.add_num(100); a.add_num(1000); fstream output(fileName.c_str(), ios::out | ios::trunc | ios::binary); a.SerializeToOstream(&output); return 0; }
编译运行,输出的二进制文件:
十六进制查看: 0a04 0a64 e807 二进制查看: ?000010100000010000001010011001001110100000000111?
解码结构如下图:

Length(00000100)=4,指示repeated重复字段的编码都在接下来的4个字节里。区分每一个字段边界的依旧靠的是Varint编码的msb位。
第一个字段(00001010)=10
第二个字段(01100100)=100
第三个字段:
11101000 00000111 逆序后并删除每个字节的msb位的二进制为: 0000111 1101000
0001111101000=1000;
Tag-Length-Value-……-Value编码方式的解码如上所示。
以上是关于Protobuf编码的主要内容,如果未能解决你的问题,请参考以下文章