对于训练集,验证集,测试集的概念,很多人都搞不清楚。网上的文章也是鱼龙混杂,因此,现在来把这方面的知识梳理一遍。让我们先来看一下模型验证(评估)的几种方式。
在机器学习中,当我们把模型训练出来以后,该怎么对模型进行验证呢?(也就是说怎样知道训练出来的模型好不好?)有以下几种验证方式:
第一种方式:把数据集全部作为训练集,然后用训练集训练模型,用训练集验证模型(如果有多个模型需要进行选择,那么最后选出训练误差最小的那个模型作为最好的模型)
这种方式显然不可行,因此训练集数据已经在模型拟合时使用过了,再使用相同的数据对模型进行验证,其结果必然是过于乐观的。如果我们对多个模型进行评估和选择,那么我们可以发现,模型越复杂,其训练误差也就越小,当某个模型的训练误差看似很完美时,其实这个模型可能已经严重地过拟合了。这在《过拟合和欠拟合(Over fitting & Under fitting)》一文中已经提过。(我们把这种由训练误差选出来模型称为gm-hat)
第二种方式:把数据集随机分为训练集和测试集,然后用训练集训练模型,用测试集验证模型(如果有多个模型需要进行选择,那么最后选出测试误差最小的那个模型作为最好的模型)
什么样的模型是好的?显然泛化误差最小的模型最好,但是我们没有这样的测试集能够测出模型的泛化误差。因此,我们把一部分数据作为测试集,用它的误差来模拟泛化误差。
把数据分出一部分作为测试集意味着训练集比原来小了。由学习曲线可知,使用较少的数据训练出来的模型,其测试误差会比较大。因此,对于多个模型的评估和选择,合理的做法是:用训练集训练出各个模型后,用测试集选出其中最好的模型(我们把此模型称为gm*-),记录最好模型的各项设置(比如说使用哪个算法,迭代次数是几次,学习速率是多少,特征转换的方式是什么,正则化方式是哪种,正则化系数是多少等等),然后用整个数据集再训练出一个新模型,作为最终的模型(我们把此模型称为gm*),这样得出的模型效果会更好,其测试误差会更接近于泛化误差。
下图展示了随着测试集的增大,各个模型 -- gm*-(红线),gm*(蓝线),gm-hat(黑实线)的期望泛化误差和理想泛化误差(黑虚线)的变化趋势:
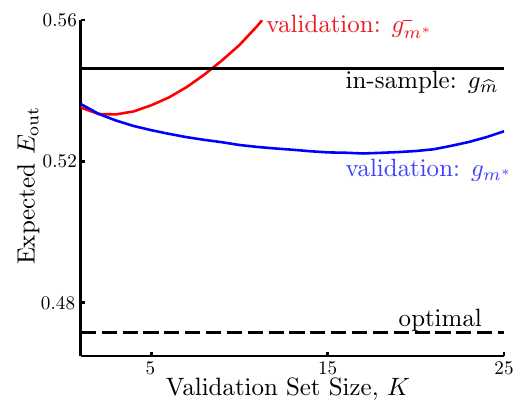
可以看到,gm*(蓝线)的表现最好,最接近于理想的泛化误差(黑虚线)。而随着测试集越来越大, gm*-(红线)的表现先是和gm*(蓝线)比较接近,然后越来越不如gm*(蓝线),最后甚至都不如gm-hat(黑实线)。这是因为测试集越大,用于训练的数据就越少,此时训练出的模型的效果肯定也就不好了。因此,在选择测试集的大小时,其实有个两难境地:如果要使gm*(蓝线)的期望泛化误差接近于理想泛化误差,就需要让测试集比较大才好,因为这样有足够多的数据模拟未知情况,但是这样一来,gm*(蓝线)和gm*-(红线)的期望泛化误差之间的差距就比较大;而要想让gm*(蓝线)和gm*-(红线)的期望泛化误差接近,就需要测试集比较小才好,因为这样有足够多的数据训练模型,但是此时gm*(蓝线)的期望泛化误差和理想泛化误差之间的差距较大。一般来说,人们通常将测试集的大小设置为所有数据的20%~30%。
很多资料都是这样把数据分为训练集(70%-80%)和测试集(20%-30%)。这样做的前提是:把模型各个可能的设置分别列出来,训练出各个不同的模型,然后用测试集选出最好的模型,接下来用全部数据按照最好模型的各项设置重新训练出一个最终的模型。这样做有两个问题。第一,模型的超参数通常很多,我们不太有可能把所有可能的设置全部罗列出来,超参数通常需要根据实际情况进行调整。如果模型的测试成绩不理想,那么我们需要返回,重新训练模型。虽然测试集不用于模型的训练,但是我们如果基于测试误差来不断调整模型,这样会把测试集的信息带入到模型中去。显然,这样是不可行的,因为测试集必须是我们从未见过的数据,否则得出的结果就会过于乐观,也就会导致过拟合的发生。第二,得出的最终的模型,其泛化误差是多少?我们还是无法评估。因为我们又把全部数据重新训练出了这个最终的模型,因此也就没有从未见过的数据来测试这个最终的模型了。
第三种方式:把数据集随机分为训练集,验证集和测试集,然后用训练集训练模型,用验证集验证模型,根据情况不断调整模型,选择出其中最好的模型,再用训练集和验证集数据训练出一个最终的模型,最后用测试集评估最终的模型
这其实已经是模型评估和模型选择的整套流程了。在第二种方式中,我们已经把数据集分为了训练集和测试集,现在我们需要再分出一个测试集,用于最终模型的评估。因为已经有一个测试集了,因此我们把其中一个用于模型选择的测试集改名叫验证集,以防止混淆。(有些资料上是先把数据集分为训练集和测试集,然后再把训练集分为训练集和验证集)
前几个步骤和第二种方式类似:首先用训练集训练出模型,然后用验证集验证模型(注意:这是一个中间过程,此时最好的模型还未选定),根据情况不断调整模型,选出其中最好的模型(验证误差用于指导我们选择哪个模型),记录最好的模型的各项设置,然后据此再用(训练集+验证集)数据训练出一个新模型,作为最终的模型,最后用测试集评估最终的模型。
由于验证集数据的信息会被带入到模型中去,因此,验证误差通常比测试误差要小。同时需要记住的是:测试误差是我们得到的最终结果,即便我们对测试得分不满意,也不应该再返回重新调整模型,因为这样会把测试集的信息带入到模型中去。
第四种方式:交叉验证 --- 具体请见《验证和交叉验证(Validation & Cross Validation)》
第五种方式:自助法 --- 具体请见《自助法(Bootstraping)》
总结一下:
训练集(Training Set):用于训练模型。
验证集(Validation Set):用于调整和选择模型。
测试集(Test Set):用于评估最终的模型。
当我们拿到数据之后,一般来说,我们把数据分成这样的三份:训练集(60%),验证集(20%),测试集(20%)。用训练集训练出模型,然后用验证集验证模型,根据情况不断调整模型,选出其中最好的模型,记录最好的模型的各项选择,然后据此再用(训练集+验证集)数据训练出一个新模型,作为最终的模型,最后用测试集评估最终的模型。