[笔记]GBDT理论知识总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[笔记]GBDT理论知识总结相关的知识,希望对你有一定的参考价值。
一. GBDT的经典paper:《Greedy Function Approximation:A Gradient Boosting Machine》
Abstract
Function approximation是从function space方面进行numerical optimization,其将stagewise additive expamsions和steepest-descent minimization结合起来。而由此而来的Gradient Boosting Decision Tree(GBDT)可以适用于regression和classification,都具有完整的,鲁棒性高,解释性好的优点。
1. Function estimation
在机器学习的任务中,我们一般面对的问题是构造loss function,并求解其最小值。可以写成如下形式:
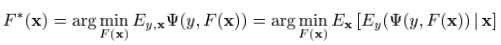
通常的loss function有:
1. regression:均方误差(y-F)2,绝对误差|y-F|
2. classification:negative binomial log-likelihood log(1+e-2yF)
一般情况下,我们会把F(x)看做是一系列带参数的函数集合 F(x;P),于是进一步将其表示为“additive”的形式:
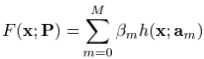
1.1 Numerical optimizatin
我们可以通过选取一个参数模型F(x;P),来将function optimization问题转化为一个parameter optimization问题:
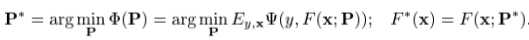
进一步,我们可以把要优化的参数也表示为“additive”的形式:
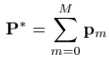
1.2 Steepest-descent
梯度下降是最简单,最常用的numerical optimization method之一。
首先,计算出当前的梯度:
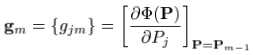
where 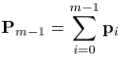
而梯度下降的步长为: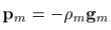
where 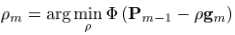 ,称为“line search”。
,称为“line search”。
2. Numerical optimization in function space
现在,我们考虑“无参数”模型,转而考虑直接在function space 进行numerical optimization。这时候,我们将在每个数据点x处的函数值F(x)看做是一个“参数”,仍然是来对loss funtion求解最小值。
在function space,为了表示一个函数F(x),理想状况下有无数个点,但在现实中,我们用有限个(N个)离散点来表示它: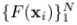 。
。
按照之前的numerical optimization的方式,我们需要求解:
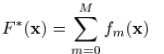
使用steepest-descent,有:
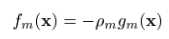
where 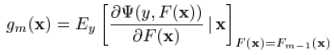 ,and
,and 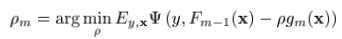
3. Finite data
当我们面对的情况为:用有限的数据集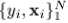 表示x,y的联合分布的时候,上述的方法就有点行不通了。我们可以试试“greedy-stagewise”的方法:
表示x,y的联合分布的时候,上述的方法就有点行不通了。我们可以试试“greedy-stagewise”的方法:
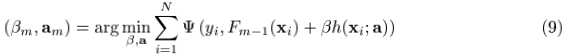
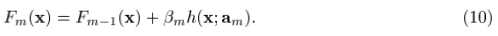
但是对于一般的loss function和base learner来说,(9)式是很难求解的。给定了m次迭代后的当前近似函数Fm-1(x),当步长的direction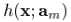 是指数函数集合
是指数函数集合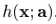 当中的一员时,
当中的一员时,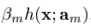 可以看做是在求解最优值上的greedy step,同样,它也可以被看做是相同限制下的steepest-descent step。作为比较,
可以看做是在求解最优值上的greedy step,同样,它也可以被看做是相同限制下的steepest-descent step。作为比较,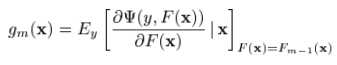 给出了在无限制条件下,在Fm-1(x)处的steepest-descent step direction。一种行之有效的方法就是在求解的时候,把它取为无限制条件下的负梯度方向
给出了在无限制条件下,在Fm-1(x)处的steepest-descent step direction。一种行之有效的方法就是在求解的时候,把它取为无限制条件下的负梯度方向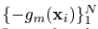 :
:
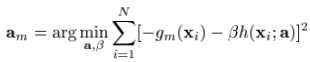
where 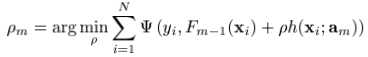
这就把(9)式中较难求解的优化问题转化为了一个基于均方误差的拟合问题。
Gradient Boosting的通用解法如下:

二. 对于GBDT的一些理解
1. Boosting
GBDT的全称是Gradient Boosting Decision Tree,Gradient Boosting和Decision Tree是两个独立的概念。因此我们先说说Boosting。Boosting的概念很好理解,意思是用一些弱分类器的组合来构造一个强分类器。因此,它不是某个具体的算法,它说的是一种理念。和这个理念相对应的是一次性构造一个强分类器。像支持向量机,逻辑回归等都属于后者。通常,我们通过相加来组合分类器,形式如下:
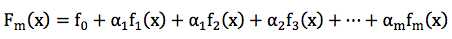
2. Gradient Boosting Modeling(GBM)
给定一个问题,我们如何构造这些弱分类器呢?Gradient Boosting Modeling (GBM) 就是构造 这些弱分类的一种方法。同样,它指的不是某个具体的算法,仍然只是一个理念。在理解 Gradient Boosting Modeling 之前,我们先看看一个典型的优化问题:
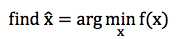
针对这种优化问题,有一个经典的算法叫 Steepest Gradient Descent,也就是最深梯度下降法。 这个算法的过程大致如下:

以上迭代过程可以这么理解:整个寻优的过程就是个小步快跑的过程,每跑一小步,都往函数当前下降最快的那个方向走一点。
这样寻优得到的结果可以表示成加和形式,即:
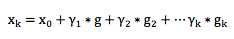
这个形式和以上Fm(x)是不是非常相似? Gradient Boosting 正是由此启发而来。 构造Fm(x)本身也是一个寻优的过程,只不过我们寻找的不是一个最优点,而是一个最优的函数。优化的目标通常都是通过一个损失函数来定义,即:
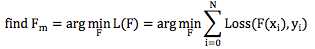
其中Loss(F(xi), yi)表示损失函数Loss在第i个样本上的损失值,xi和yi分别表示第 i 个样本的特征和目标值。常见的损失函数如平方差函数:
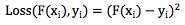
类似最深梯度下降法,我们可以通过梯度下降法来构造弱分类器f1, f2, ... , fm,只不过每次迭代时,令
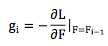
即对损失函数L,以 F 为参考求取梯度。
这里有个小问题,一个函数对函数的求导不好理解,而且通常都无法通过上述公式直接求解 到梯度函数gi。为此,采取一个近似的方法,把函数Fi?1理解成在所有样本上的离散的函数值,即:
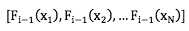
不难理解,这是一个 N 维向量,然后计算
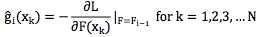
这是一个函数对向量的求导,得到的也是一个梯度向量。注意,这里求导时的变量还是函数F,不是样本xk。
严格来说 g?i(xk) for k = 1,2, ... , N 只是描述了gi在某些个别点上的值,并不足以表达gi,但我们可以通过函数拟合的方法从g?i(xk) for k = 1,2, ... , N 构造gi,这样我们就通过近似的方法得到了函数对函数的梯度求导。
因此 GBM 的过程可以总结为如下:

常量函数f0通常取样本目标值的均值,即
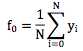
3. Gradient Boosting Decision Tree
以上 Gradient Boosting Modeling 的过程中,还没有说清楚如何通过离散值 g?i?1(xj) for j = 1,2,3,...N 构造拟合函数gi?1。函数拟合是个比较熟知的概念,有很多现成的方法,不过有一种拟合方法广为应用,那就是决策树 Decision Tree,有关决策树的概念,理解GBDT重点首先是Gradient Boosting,其次才是 Decision Tree。GBDT 是 Gradient Boosting 的一种具体实例,只不过这里的弱分类器是决策树。如果你改用其他弱分类器 XYZ,你也可以称之为 Gradient Boosting XYZ。只不过 Decision Tree 很好用,GBDT 才如此引人注目。
4. 损失函数
谈到 GBDT,常听到一种简单的描述方式:“先构造一个(决策)树,然后不断在已有模型和实际样本输出的残差上再构造一颗树,依次迭代”。其实这个说法不全面,它只是 GBDT 的一种特殊情况,为了看清这个问题,需要对损失函数的选择做一些解释。
从对GBM的描述里可以看到Gradient Boosting过程和具体用什么样的弱分类器是完全独立的,可以任意组合,因此这里不再刻意强调用决策树来构造弱分类器,转而我们来仔细看看弱分类器拟合的目标值,即梯度g?i?1(xj ),之前我们已经提到过

5. GBDT 和 AdaBoost
Boosting 是一类机器学习算法,在这个家族中还有一种非常著名的算法叫 AdaBoost,是 Adaptive Boosting 的简称,AdaBoost 在人脸检测问题上尤其出名。既然也是 Boosting,可以想象它的构造过程也是通过多个弱分类器来构造一个强分类器。那 AdaBoost 和 GBDT 有什么区别呢?
两者最大的区别在于,AdaBoost 不属于 Gradient Boosting,即它在构造弱分类器时并没有利用到梯度下降法的思想,而是用的Forward Stagewise Additive Modeling (FSAM)。为了理解 FSAM,在回过头来看看之前的优化问题。
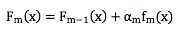
严格来说之前描述的优化问题要求我们同时找出α1, α2, ... , αm和f1, f2, f3 ... , fm,这个问题很 难。为此我们把问题简化为分阶段优化,每个阶段找出一个合适的α 和f 。假设我们已经 得到前 m-1 个弱分类器,即Fm?1(x),下一步在保证Fm?1(x)不变的前提下,寻找合适的 αmfm(x)。按照损失函数的定义,我们可以得到
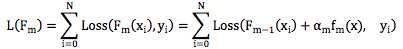
如果 Loss 是平方差函数,则我们有
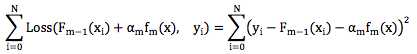
这里yi ? Fm?1(xi)就是当前模型在数据上的残差,可以看出,求解合适的αmfm(x)就是在这 当前的残差上拟合一个弱分类器,且损失函数还是平方差函数。这和 GBDT 选择平方差损失 函数时构造弱分类器的方法恰好一致。
(1)拟合的是“残差”,对应于GBDT中的梯度方向。
(2)损失函数是平方差函数,对应于GBDT中用Decision Tree来拟合“残差”。
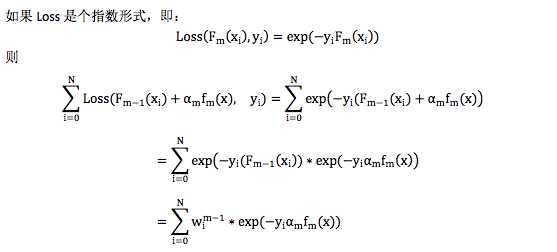
其中 wim?1= exp(?yi(Fm?1(xi))和要求解的αmfm(x)无关,可以当成样本的权重,因此在这种情况下,构造弱分类器就是在对样本设置权重后的数据上拟合,且损失函数还是指数形式。 这个就是 AdaBoost,不过 AdaBoost 最早并不是按这个思路推出来的,相反,是在 AdaBoost 提出 5 年后,人们才开始用 Forward Stagewise Additive Modeling 来解释 AdaBoost 背后的原理。
为什么要把平方差和指数形式 Loss 函数单独拿出来说呢?这是因为对这两个损失函数来说, 按照 Forward Stagewise Additive Modeling 的思路构造弱分类器时比较方便。如果是平方差损 失函数,就在残差上做平方差拟合构造弱分类器; 如果是指数形式的损失函数,就在带权 重的样本上构造弱分类器。但损失函数如果不是这两种,问题就没那么简单,比如绝对差值 函数,虽然构造弱分类器也可以表示成在残差上做绝对差值拟合,但这个子问题本身也不容 易解,因为我们是要构造多个弱分类器的,所以我们当然希望构造弱分类器这个子问题比较 好解。因此 FSAM 思路无法推广到其他一些实用的损失函数上。相比而言,Gradient Boosting Modeling (GBM) 有什么优势呢?GBM 每次迭代时,只需要计算当前的梯度,并在平方差损 失函数的基础上拟合梯度。虽然梯度的计算依赖原始问题的损失函数形式,但这不是问题, 只要损失函数是连续可微的,梯度就可以计算。至于拟合梯度这个子问题,我们总是可以选 择平方差函数作为这个子问题的损失函数,因为这个子问题是一个独立的回归问题。
因此 FSAM 和 GBM 得到的模型虽然从形式上是一样的,都是若干弱模型相加,但是他们求 解弱分类器的思路和方法有很大的差别。只有当选择平方差函数为损失函数时,这两种方法 等同。
6. 为何GBDT受人青睐
以上比较了 GBM 和 FSAM,可以看到 GBM 在损失函数的选择上有更大的灵活性,但这不足以解释GBDT的全部优势。GBDT是拿Decision Tree作为GBM里的弱分类器,GBDT的优势 首先得益于 Decision Tree 本身的一些良好特性,具体可以列举如下:
-
Decision Tree 可以很好的处理 missing feature,这是他的天然特性,因为决策树的每个节点只依赖一个 feature,如果某个 feature 不存在,这颗树依然可以拿来做决策,只是少一些路径。像逻辑回归,SVM 就没这个好处。
-
Decision Tree 可以很好的处理各种类型的 feature,也是天然特性,很好理解,同样逻辑回归和 SVM 没这样的天然特性。
-
对特征空间的 outlier 有鲁棒性,因为每个节点都是 x < ?? 的形式,至于大多少,小多少没有区别,outlier 不会有什么大的影响,同样逻辑回归和 SVM 没有这样的天然特性。
-
如果有不相关的 feature,没什么干扰,如果数据中有不相关的 feature,顶多这个 feature 不出现在树的节点里。逻辑回归和 SVM 没有这样的天然特性(但是有相应的补救措施,比如逻辑回归里的 L1 正则化)。
-
数据规模影响不大,因为我们对弱分类器的要求不高,作为弱分类器的决策树的深 度一般设的比较小,即使是大数据量,也可以方便处理。像 SVM 这种数据规模大的时候训练会比较麻烦。
当然 Decision Tree 也不是毫无缺陷,通常在给定的不带噪音的问题上,他能达到的最佳分类效果还是不如 SVM,逻辑回归之类的。但是,我们实际面对的问题中,往往有很大的噪音,使得 Decision Tree 这个弱势就不那么明显了。而且,GBDT 通过不断的叠加组合多个小的 Decision Tree,他在不带噪音的问题上也能达到很好的分类效果。换句话说,通过GBDT训练组合多个小的 Decision Tree 往往要比一次性训练一个很大的 Decision Tree 的效果好很多。因此不能把 GBDT 理解为一颗大的决策树,几颗小树经过叠加后就不再是颗大树了,它比一颗大树更强。
以上是关于[笔记]GBDT理论知识总结的主要内容,如果未能解决你的问题,请参考以下文章