数据分析练习报告二
Posted goubb
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析练习报告二相关的知识,希望对你有一定的参考价值。
一、今天完成了行业代码匹配,还有数据没有展示
二、文本匹配,添加行业代码。
设计思路:首先,我们需要将完全相同的行业代码进行匹配,其次将相似的行业代码进行文本相似匹配,选取符合要求的前面几个行业,追加行业代码。
判断完全相同的部分就不解释了,主要解释如何使用word2vec模式进行文本相似的匹配。
需要使用的库
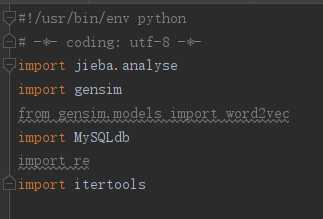
1、首先我们需要创建数据集(主要看数据集是以何种方式储存的),接收数据集(使用何种函数)。

数据集中单个元素与单个元素之间以空格隔开。接受数据集


1 sentences = word2vec.Text8Corpus("../词库/商业类别词.txt") #text8为语料库文件名
2、构建模型
1 model=gensim.models.Word2Vec(sentences, sg=1, size=100, window=5, min_count=2, negative=3, sample=0.001, hs=1, workers=4) 2 # print(model) 3 # 该步骤也可分解为以下三步(但没必要): 4 # model=gensim.model.Word2Vec() 建立一个空的模型对象 5 # # model.build_vocab(sentences) 遍历一次语料库建立词典 6 # # model.train(sentences) 第二次遍历语料库建立神经网络模型 7 8 # sg=1是skip—gram算法,对低频词敏感,默认sg=0为CBOW算法 9 # size是神经网络层数,值太大则会耗内存并使算法计算变慢,一般值取为100到200之间。 10 # window是句子中当前词与目标词之间的最大距离,3表示在目标词前看3-b个词,后面看b个词(b在0-3之间随机) 11 # min_count是对词进行过滤,频率小于min-count的单词则会被忽视,默认值为5。 12 # negative和sample可根据训练结果进行微调,sample表示更高频率的词被随机下采样到所设置的阈值,默认值为1e-3, 13 # negative: 如果>0,则会采用negativesamping,用于设置多少个noise words 14 # hs=1表示层级softmax将会被使用,默认hs=0且negative不为0,则负采样将会被选择使用。 15 # workers是线程数,此参数只有在安装了Cpython后才有效,否则只能使用单核
3、保存训练后的模型
1 model.save("model/商业类别模型") #模型会保存到该 .py文件同级目录下,该模型打开为乱码
4、加载训练后的模型
1 model = gensim.models.Word2Vec.load("model/商业类别模型")
5、获取相似度较大的几个结果
1 industry_content = model.wv.most_similar(item["willcode"], topn=3)
以上是关于数据分析练习报告二的主要内容,如果未能解决你的问题,请参考以下文章