数据分析练习-3.13进度
Posted lover995
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析练习-3.13进度相关的知识,希望对你有一定的参考价值。
今天在昨天的基础上继续做了关键词提取的实现,将没有关键词的数据根据成果简介提取其关键词。
部分源代码:
1 import math 2 3 import jieba 4 5 import jieba.posseg as psg 6 7 from gensim import corpora, models 8 9 from jieba import analyse 10 11 import functools 12 13 14 def get_stopword_list(): 15 stop_word_path = ‘C:/Users/ASUS/Desktop/stopwords.txt‘ 16 17 stopword_list = [sw.replace(‘ ‘, ‘‘) for sw in open(stop_word_path,encoding=‘utf-8‘).readlines()] 18 19 return stopword_list 20 21 22 # 分词方法 23 24 def seg_to_list(sentence, pos=False): 25 if not pos: 26 27 # 不进行词性标注的分词方法 28 29 seg_list = jieba.cut(sentence) 30 31 else: 32 33 # 进行词性标注的分词方法 34 35 seg_list = psg.cut(sentence) 36 37 return seg_list 38 39 40 # 去除干扰词,根据pos判断是否过滤除名词外的其他词性,再判断词是否在停用词表中,长度是否大于等于2等。 41 42 def word_filter(seg_list, pos=False): 43 stopword_list = get_stopword_list() 44 45 filter_list = [] 46 47 # 根据pos参数选择是否词性过滤 48 49 # 不进行词性过滤,则将词性都标记为n,表示全部保留 50 51 for seg in seg_list: 52 53 if not pos: 54 55 word = seg 56 57 flag = ‘n‘ 58 59 else: 60 61 word = seg.word 62 63 flag = seg.flag 64 65 if not flag.startswith(‘n‘): 66 continue 67 68 # 过滤高停用词表中的词,以及长度为<2的词 69 70 if not word in stopword_list and len(word) > 1: 71 filter_list.append(word) 72 73 return filter_list 74 75 76 77 # 数据加载 78 79 80 # idf值统计方法 81 82 def train_idf(doc_list): 83 idf_dic = {} 84 85 # 总文档数 86 87 tt_count = len(doc_list) 88 89 # 每个词出现的文档数 90 91 for doc in doc_list: 92 93 for word in set(doc): 94 idf_dic[word] = idf_dic.get(word, 0.0) + 1.0 95 96 # 按公式转换为idf值,分母加1进行平滑处理 97 98 for k, v in idf_dic.items(): 99 idf_dic[k] = math.log(tt_count / (1.0 + v)) 100 101 # 对于没有在字典中的词,默认其尽在一个文档出现,得到默认idf值 102 103 default_idf = math.log(tt_count / (1.0)) 104 105 return idf_dic, default_idf 106 107 108 # topK
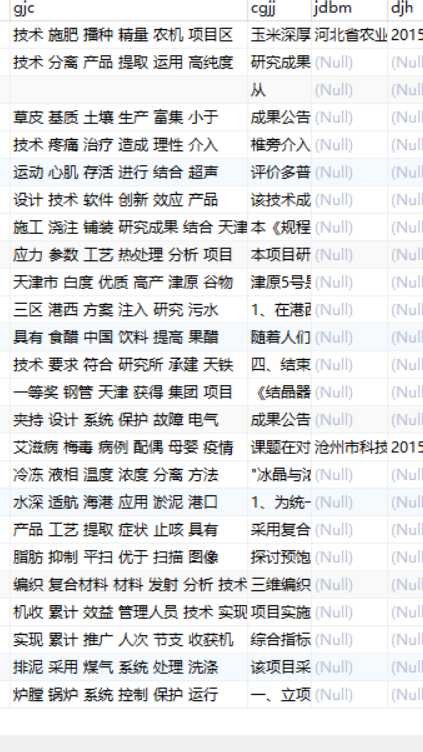
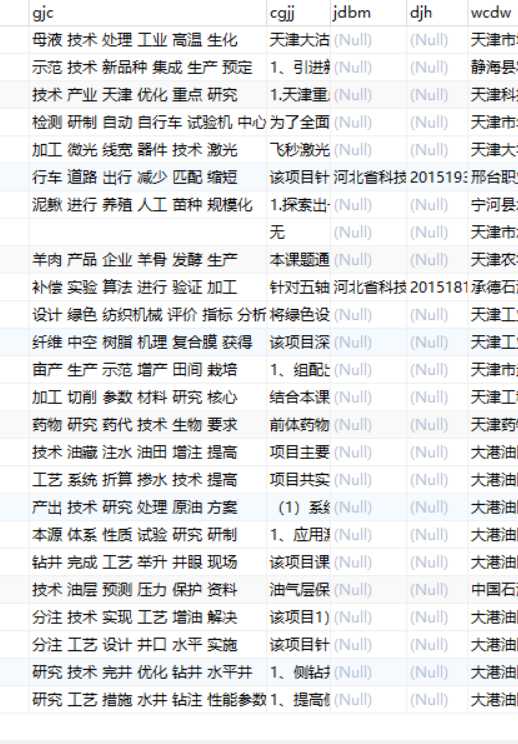
数据库结果截图:
以上是关于数据分析练习-3.13进度的主要内容,如果未能解决你的问题,请参考以下文章