自然语言处理面试问题个人总结
Posted tfknight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理面试问题个人总结相关的知识,希望对你有一定的参考价值。
1 列出几种文本特征提取算法
答:文档频率、信息增益、互信息、X^2统计、TF-IDF
(引用自:https://www.cnblogs.com/jiashun/p/CrossEntropyLoss.html)
信息:

由于概率I 是一个)0至1的值,所以当事件发生的概率越大时,信息量越小。
相对熵:
相对熵又称KL散度(Kullback-Leibler (KL) divergence),用于衡量对于同一个随机变量x的两个单独的概率分布P(x)和Q(x)之间的差异。
KL散度的值越小表示两个分布越接近.
在一定程度上面,相对熵可以度量两个随机分布的距离。也常常用相对熵来度量两个随机分布的距离。当两个随机分布相同的时候,他们的相对熵为0,当两个随机分布的差别增大的时候,他们之间的相对熵也会增大。
熵:
是表示随机变量不确定的度量,是对所有可能发生的事件产生的信息量的期望。
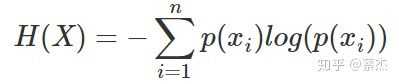
信息增益:
分类前的信息熵减去分类后的信息熵
交叉熵:
我们将KL散度公式进行变形得到:
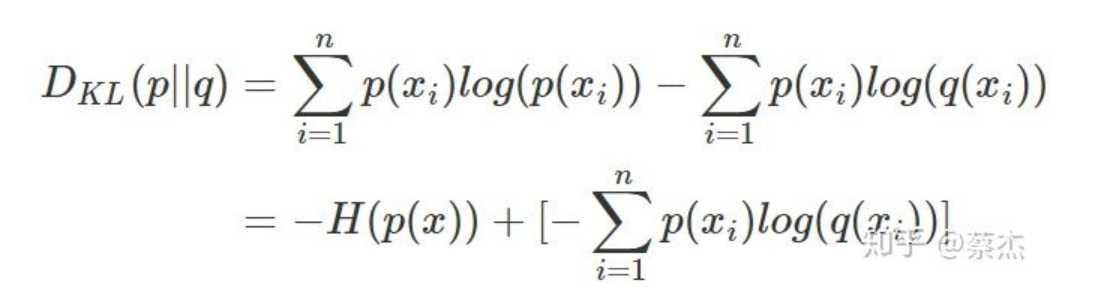
这里前半部分是事件P自己的信息熵, 后面那部分可以作为事件P和事件q的信息熵(交叉)
交叉熵广泛用于逻辑回归的Sigmoid和Softmax函数中作为损失函数使用。
二分类交叉熵误差:
模型最后需要预测的结果只有两种情况,对于每个类别我们的预测得到的概率为 和
。此时表达式为:

意思就是每个类别都做一个信息熵的计算,然后加起来,(目的最小)
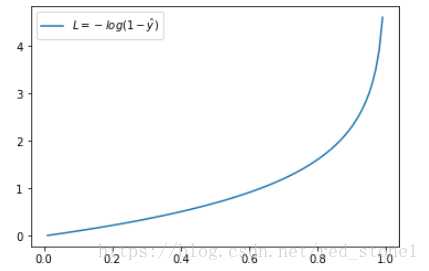
同样,预测输出越接近真实样本标签 0,损失函数 L 越小;预测函数越接近 1,L 越大。函数的变化趋势也完全符合实际需要的情况
多分类交叉熵误差:

M表示标签的种类数
交叉熵误差函数和softmax(神经网络用到的输出函数)和sigmoid函数(logistic回归用到的函数)的复合函数是凸函数,即存在全局最优解
2 RNN基本原理
(引用自:https://zhuanlan.zhihu.com/p/32755043)
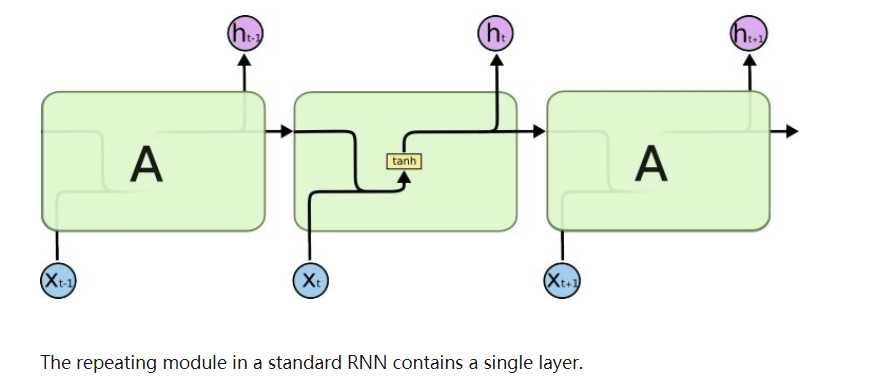
RNN循环神经元的计算过程:
- 将输入时间步提供给网络,也就是提供给网络
。
- 接下来利用输入和前一时刻的状态计算当前状态,也就是
- 当前状态变成下一步的前一状态
- 我们可以执行上面的步骤任意多次(主要取决于任务需要),然后组合从前面所有步骤中得到的信息。
- 一旦所有时间步都完成了,最后的状态用来计算输出
- 输出与真实标签进行比较并得到误差。
- 误差通过后向传播(后面将介绍如何后向传播)对权重进行升级,进而网络训练完成。
反向传播:
- 首先使用预测输出和实际输出计算交叉熵误差
- 网络按照时间步完全展开
- 对于展开的网络,对于每一个实践步计算权重的梯度
- 因为对于所有时间步来说,权重都一样,所以对于所有的时间步,可以一起得到梯度(而不是像神经网络一样对不同的隐藏层得到不同的梯度)
- 随后对循环神经元的权重进行升级
交叉熵误差:
梯度爆炸问题和消失问题:
RNN基于这样的机制,信息的结果依赖于前面的状态或前N个时间步。普通的RNN可能在学习长距离依赖性方面存在困难。例如,如果我们有这样一句话,“The man who ate my pizza has purple hair”。在这种情况下,purple hair描述的是The man,而不是pizza。所以这是一个长距离的依赖关系。
如果我们在这种情况下后向传播,我们就需要应用链式法则。在三个时间步后对第一个求梯度的公式如下:
∂E/∂W = ∂E/∂y3* ∂y3/∂h3* ∂h3/∂y2 *∂y2/∂h1 .. 这就是一个长距离的依赖关系.
在这里,我们应用了链式规则,如果任何一个梯度接近0,所有的梯度都会成指数倍的迅速变成零。这样将不再有助于网络学习任何东西。这就是所谓的消失梯度问题。
同理:
梯度爆炸就是由于单个或多个梯度值变得非常高,梯度变得非常大。
3 RNN常见的几种设计模式
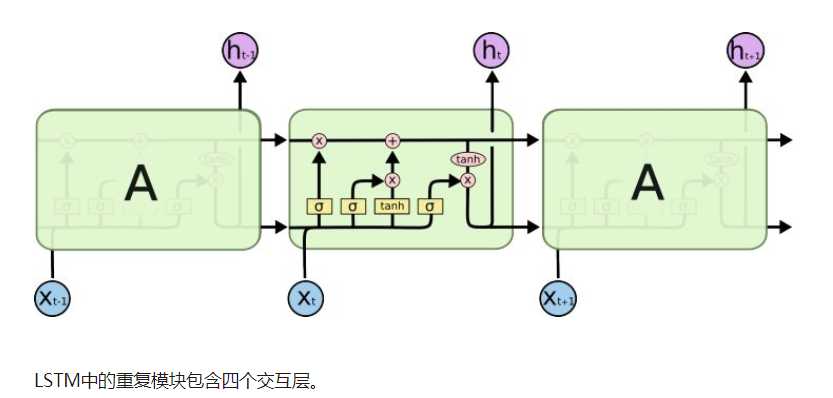
为了来处理消失梯度问题。人们提出了LSTM结构(长短期记忆网络)和GRU(门控性单位)可以用来处理消失的梯度问题。
LSTM也有这样的链式结构,但重复模块有不同的结构。不是有一个单一的神经网络层,而是有四个,他们之间以一种非常特殊的方式进行交互。
以上是关于自然语言处理面试问题个人总结的主要内容,如果未能解决你的问题,请参考以下文章