Pinpoint-技术专区-全流程学习
Posted liboware
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pinpoint-技术专区-全流程学习相关的知识,希望对你有一定的参考价值。
基于pinpoint改造的一种方式的思考(1)--agent 添加代理层
1.Pinpoint简介
Pinpoint 是用 Java 编写的 APM(应用性能管理)工具,用于大规模分布式系统。在 Dapper(dapper.docx) 之后,Pinpoint 提供了一个解决方案,以帮助分析系统的总体结构以及分布式应用程序的组件之间是如何进行数据互联的。它采用java agent 的方式对 jvm应用的无侵入的改造。同时对性能的影响非常小(只增加约3%资源利用率)。 支持以下模块。
tomcat 6/7/8,Jetty 9
Spring, Spring Boot
Apache Http Client 3.x/4.x,JDK HttpConnector,GoogleHttpClinet,OkHttpClient,NingAsyncHttpClient
Thrift Cliet,Thirft Service
mysql,Oracle,MSSQL,CUBRID,DBCP,POSTGRESQL
Arcus,Memcached,Redis
IBATIS,MyBatis
Gson,Jackson,Json Lib
Log4j,Logback
2.Pinpoint架构
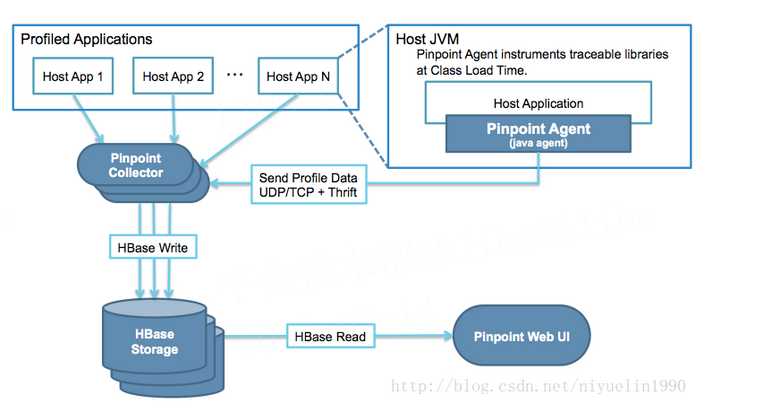
以下是pinpoint的架构图,如图所示 Profiled Applications 是 对应的注入pinpoint agent的jvm容器。 其他分为3种消息:1.tcp 9994端口的 agent配置信息、Api信息、String信息、Exception信息。 2.udp 9995 端口 发送JVM内存使用情况,线程相关信息,每隔30秒一个包,每个包为6条信息。 3.Udp 9996 端口 这个端口数据是最关键也是数据最多的,是全链路Trace 报文。
那么以上所有的消息都是通过Tcp/udp,Thrift协议发送到云端的Collector,collector收集数据并保存到hbase。 同时pinpoint web UI 读取Hbase数据展示链路等数据。
3.问题探讨
提供pinpoint的架构和内在逻辑的分析,我们发现pinpoint agent 是其精华所在。但是他包含以下问题
1. agent数据直接发送到 固定的collector地址 没有服务发现,collector挂了数据就无法收到。
2. agent数据是原始数据,直接发送到Collector未进行压缩,未进行缓存
3. Collector在 agent Jvm 高并发环境下,只能最多进行1对3的收集,对于大规模 应用服务器情况下Collector显得非常无能。
4. 改造
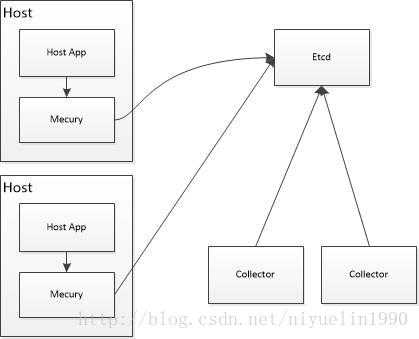
如下图所示,我们增加 Mecury 的代理层。 它的作用有
1.提供Etcd 服务发现获取Load最低的Collector
2.对Agent发送的数据进行预处理:数据解析,数据压缩,定时发送到Collector。其中数据压缩可以用Snappy。
3.采用Golang 实现数据的收集,同时mecury 还充当获取服务器 监控数据发送到Collector
4. Mecury执行部分Java Shell指令对Jvm进行外部监控
当然Collector 我们也是采用golang进行重写,自此 Collector(golang 实现) 压力下降上千倍,在生产环境下可以支持1对300+agent的服务器。
这里写图片描述
5. 总结
以上对Pinpoint agent 和pinpoint Collector的 改造方案。我所在公司已经改造完成,并在生产环境大面积使用。
当然我们还有很多事情可以做,比对如何高效的实时报警,如何存储监控数据(hbase是否还能满足需求),如何做跨语言的监控,监控Ui如何展示全面实时。
以上是关于Pinpoint-技术专区-全流程学习的主要内容,如果未能解决你的问题,请参考以下文章