Embedded Vision question
Posted ph-one
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Embedded Vision question相关的知识,希望对你有一定的参考价值。
01 IFQ-Net: Integrated Fixed-point Quantization Networks for Embedded Vision (1911.08076)
In this paper, we propose a fixed-point network
for embedded vision tasks through converting the floatingpoint data in a quantization network into fixed-point. Furthermore, to overcome the data loss caused by the conversion, we propose to compose floating-point data operations
across multiple layers (e.g. convolution, batch normalization and quantization layers) and convert them into fixedpoint.
量化网络层 将浮点数据转换为固定点数据;
为了减小数据丢失,转换过程跨多个层(卷积 正则化 量化);
02 DupNet: Towards Very Tiny Quantized CNN with Improved Accuracy for Face
Detection
【
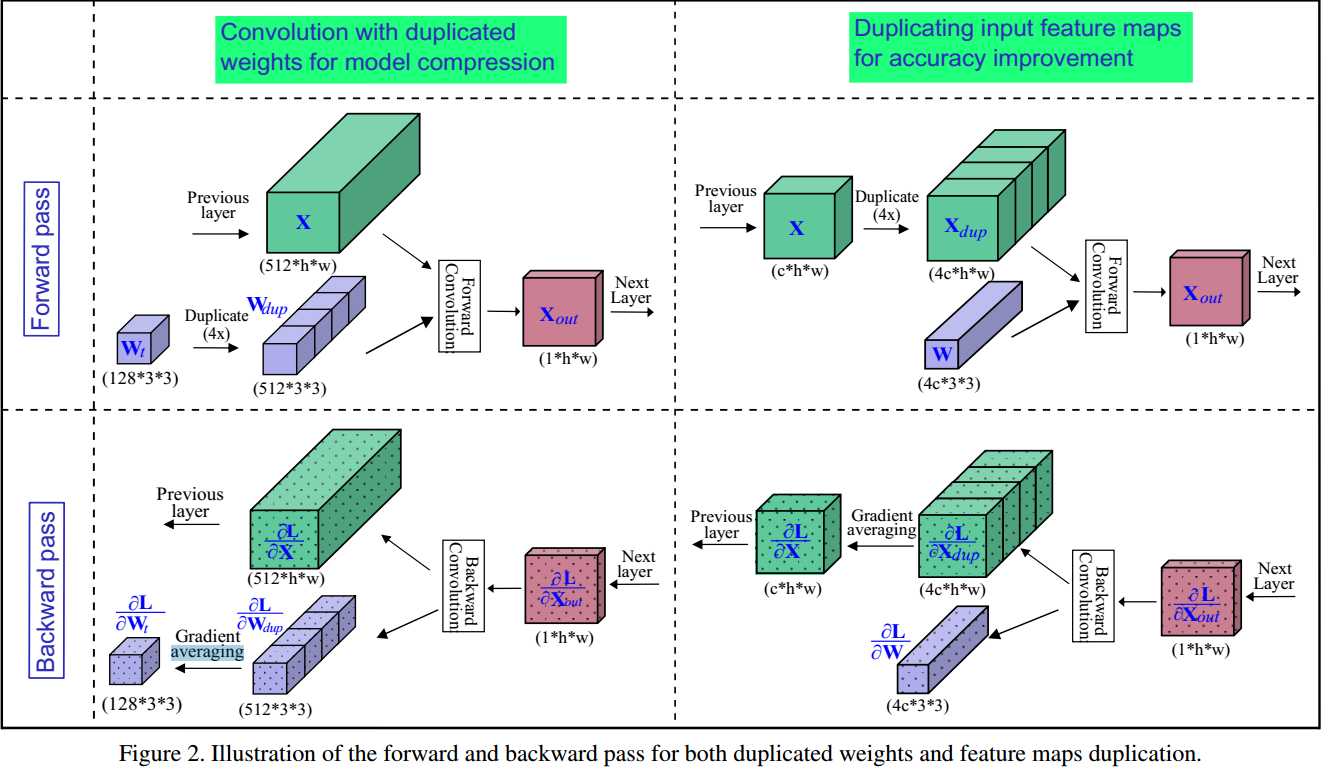
we propose DupNet which consists of two parts.
Firstly, we employ weights with duplicated channels for the
weight-intensive layers to reduce the model size. Secondly,
for the quantization-sensitive layers whose quantization
causes notable accuracy drop, we duplicate its input feature
maps. It allows us to use more weights channels for convolving more representative outputs.
】
【
1) it reduces the model size of a quantized network by duplicated weights for weight-intensive layers;
2)it increases the accuracy through duplicating the input feature maps of its quantization-sensitive layers.
】
1:权重密集层复制权重参数(使用同样的参数,减小模型尺寸)
2:量化密集层复制输入特性映射(增加准确率)
以上是关于Embedded Vision question的主要内容,如果未能解决你的问题,请参考以下文章