一文说清文本编码那些事
Posted softidea
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文说清文本编码那些事相关的知识,希望对你有一定的参考价值。
一直以来,编码问题像幽灵一般,不少开发人员都受过它的困扰。
试想你请求一个数据,却得到一堆乱码,丈二和尚摸不着头脑。有同事质疑你的数据是乱码,虽然你很确定传了 UTF-8 ,却也无法自证清白,更别说帮同事 debug 了。
有时,靠着百度和一手瞎调的手艺,乱码也能解决。尽管如此,还是很羡慕那些骨灰级程序员。为什么他们每次都能犀利地指出问题,并快速修复呢?原因在于,他们早就把编码问题背后的各种来龙去脉搞清楚了。
本文从 ASCII 码说起,带你扒一扒编码背后那些事。相信搞清编码的原理后,你将不再畏惧任何编码问题。
从 ASCII 码说起
现代计算机技术从英文国家兴起,最先遇到的也是英文文本。英文文本一般由 26 个字母、 10 个数字以及若干符号组成,总数也不过 100 左右。
计算机中最基本的存储单位为 字节 ( byte ),由 8 个比特位( bit )组成,也叫做 八位字节 ( octet )。8 个比特位可以表示 $ 2^8 = 256 $ 个字符,看上去用字节来存储英文字符即可?
计算机先驱们也是这么想的。他们为每个英文字符编号,再加上一些控制符,形成了我们所熟知的 ASCII 码表。实际上,由于英文字符不多,他们只用了字节的后 7 位而已。
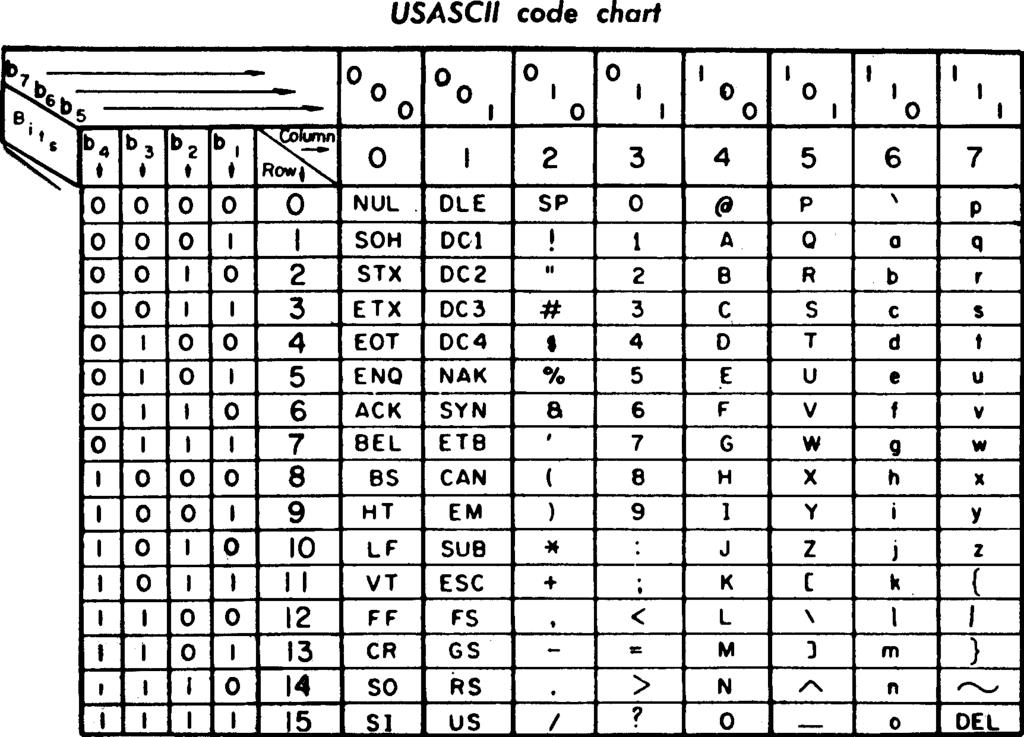
根据 ASCII 码表,由 01000001 这 8 个比特位组成的八位字节,代表字母 A 。

顺便提一下,比特本身没有意义,比特 在 上下文 ( context )中才构成信息。举个例子,对于内存中一个字节 01000001 ,你将它看做一个整数,它就是 65 ;将它作为一个英文字符,它就是字母 A ;你看待比特的方式,就是所谓的上下文。
所以,猜猜下面这个程序输出啥?
#include <stdio.h>
int main(int argc, char *argv[])
{
char value = 0x41;
// as a number, value is 65 or 0x41 in hexadecimal
printf("%d
", value);
// as a ASCII character, value is alphabet A
printf("%c
", value);
return 0;
}latin1
西欧人民来了,他们主要使用拉丁字母语言。与英语类似,拉丁字母数量并不大,大概也就是几十个。于是,西欧人民打起 ASCII 码表那个未用的比特位( b8 )的主意。
还记得吗?ASCII 码表总共定义了 128 个字符,范围在 0~127 之间,字节最高位 b8 暂未使用。于是,西欧人民将拉丁字母和一些辅助符号(如欧元符号)定义在 128~255 之间。这就构成了 latin1 ,它是一个 8 位字符集,定义了以下字符:

图中绿色部分是不可打印的( unprintable )控制字符,左半部分是 ASCII 码。因此,latin1 字符集是 ASCII 码的超集:

一个字节掰成两半,欧美两兄弟各用一半。至此,欧美人民都玩嗨了,东亚人民呢?
GB2312、GBK和GB18030
由于受到汉文化的影响,东亚地区主要是汉字圈,我们便以中文为例展开介绍。
汉字有什么特点呢?—— 光常用汉字就有几千个,这可不是一个字节能胜任的。一个字节不够就两个呗。道理虽然如此,操作起来却未必这么简单。
首先,将需要编码的汉字和 ASCII 码整理成一个字符集,例如 GB2312 。为什么需要 ASCII 码呢?因为,在计算机世界,不可避免要跟数字、英文字母打交道。至于拉丁字母,重要性就没那么大,也就无所谓了。

GB2312 字符集总共收录了 6 千多个汉字,用两个字节来表示足矣,但事情远没有这么简单。同样的数字字符,在 GB2312 中占用 2 个字节,在 ASCII 码中占用 1 个字节,这不就不兼容了吗?计算机里太多东西涉及 ASCII 码了,看看一个 http 请求:
GET / HTTP/1.1
Host: www.example.com 那么,怎么兼容 GB2312 和 ASCII 码呢?天无绝人之路, 变长 编码方案应运而生。
变长编码方案,字符由长度不一的字节表示,有些字符只需 1 字节,有些需要 2 字节,甚至有些需要更多字节。GB2312 中的 ASCII 码与原来保持一致,还是用一个字节来表示,这样便解决了兼容问题。
在 GB2312 中,如果一个字节最高位 b8 为 0 ,该字节便是单字节编码,即 ASCII 码。如果字节最高位 b8 为 1 ,它就是双字节编码的首字节,与其后字节一起表示一个字符。

变长编码方案目的在于兼容 ASCII 码,但也带来一个问题:由于字节编码长度不一,定位第 N 个字符只能通过遍历实现,时间复杂度从 $ O(1) $ 退化到 $ O(N) $ 。好在这种操作场景并不多见,因此影响可以忽略。
GB2312 收录的汉字个数只有常用的 6 千多个,遇到生僻字还是无能为力。因此,后来又推出了 GBK 和 GB18030 字符集。GBK 是 GB2312 的超集,完全兼容 GB2312 ;而 GB18030 又是 GBK 的超集,完全兼容 GBK 。

因此,对中文编码文本进行解码,指定 GB18030 最为健壮:
>>> raw = b‘xfdx88xb5xc4xb4xabxc8xcb‘
>>> raw.decode(‘gb18030‘)
‘龍的传人‘指定 GBK 或 GB2312 就只好看运气了,GBK 多半还没事:
>>> raw.decode(‘gbk‘)
‘龍的传人‘GB2312 经常直接抛锚不商量:
>>> raw.decode(‘gb2312‘)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: ‘gb2312‘ codec can‘t decode byte 0xfd in position 0: illegal multibyte sequencechardet 是一个不错的文本编码检测库,用起来很方便,但对中文编码支持不是很好。经常中文编码的文本进去,检测出来的结果是 GB2312 ,但一用 GB2312 解码就跪:
>>> import chardet
>>> raw = b‘xd6xd0xb9xfaxc8xcbxcaxc7xfdx88xb5xc4xb4xabxc8xcb‘
>>> chardet.detect(raw)
{‘encoding‘: ‘GB2312‘, ‘confidence‘: 0.99, ‘language‘: ‘Chinese‘}
>>> raw.decode(‘GB2312‘)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: ‘gb2312‘ codec can‘t decode byte 0xfd in position 8: illegal multibyte sequence掌握 GB2312 、 GBK 、 GB18030 三者的关系后,我们可以略施小计。如果 chardet 检测出来结果是 GB2312 ,就用 GB18030 去解码,大概率可以成功!
>>> raw.decode(‘GB18030‘)
‘中国人是龍的传人‘Unicode
GB2312 、 GBK 与 GB18030 都是中文编码字符集。虽然 GB18030 也包含日韩表意文字,算是国际字符集,但毕竟是以中文为主,无法适应全球化应用。
在计算机发展早期,不同国家都推出了自己的字符集和编码方案,互不兼容。中文编码的文本在使用日文编码的系统上是无法显示的,这就给国际交往带来障碍。
这时,英雄出现了。统一码联盟 站出来说要发展一个通用的字符集,收录世界上所有字符,这就是 Unicode 。经过多年发展, Unicode 已经成为世界上最通用的字符集,也是计算机科学领域的业界标准。
Unicode 已经收录的字符数量已经超过 13 万个,每个字符需占用超过 2 字节。由于常用编程语言一般没有 24 位数字类型,因此一般用 32 位数字表示一个字符。这样一来,同样的一个英文字母,在 ASCII 中只需占用 1 字节,在 Unicode 则需要占用 4 字节!英美人民都要哭了,试想你磁盘中的文件大小都增大了 4 倍是什么感受!
UTF-8
为了兼容 ASCII 并优化文本空间占用,我们需要一种变长字节编码方案,这就是著名的 UTF-8 。与 GB2312 等中文编码一样,UTF-8 用不固定的字节数来表示字符:
- ASCII 字符 Unicode 码位由 U+0000 至 U+007F ,用 1 个字节编码,最高位为 0 ;
- 码位由 U+0080 至 U+07FF 的字符,用 2 个字节编码,首字节以 110 开头,其余字节以 10 开头;
- 码位由 U+0800 至 U+FFFF 的字符,用 3 个字节编码,首字节以 1110 开头,其余字节同样以 10 开头;
- 4 至 6 字节编码的情况以此类推;

如图,以 0 开头的字节为 单字节 编码,总共 7 个有效编码位,编码范围为 U+0000 至 U+007F ,刚好对应 ASCII 码所有字符。以 110 开头的字节为 双字节 编码,总共 11 个有效编码位,最大值是 0x7FF ,因此编码范围为 U+0080 至 U+07FF ;以 1110 开头的字节为 三字节 编码,总共 16 个有效编码位,最大值是 0xFFFF 因此编码范围为 U+0800 至 U+FFFF 。
根据开头不同, UTF-8 流中的字节,可以分为以下几类:
| 字节最高位 | 类别 | 有效位 |
|---|---|---|
| 0 | 单字节编码 | 7 |
| 10 | 多字节编码非首字节 | |
| 110 | 双字节编码首字节 | 11 |
| 1110 | 三字节编码首字节 | 16 |
| 11110 | 四字节编码首字节 | 21 |
| 111110 | 五字节编码首字节 | 26 |
| 1111110 | 六字节编码首字节 | 31 |
至此,我们已经具备了读懂 UTF-8 编码字节流的能力,不信来看一个例子:

概念回顾
一直以来,字符集 和 编码 这两个词一直是混着用的。现在,我们总算有能力厘清这两者间的关系了。
字符集 顾名思义,就是由一定数量字符组成的集合,每个字符在集合中有唯一编号。前文提及的 ASCII 、 latin1 、 GB2312 、GBK 、GB18030 以及 Unicode 等,无一例外,都是字符集。
计算机存储和网络通讯的基本单位都是 字节 ,因此文本必须以 字节序列 的形式进行存储或传输。那么,字符编号如何转化成字节呢?这就是 编码 要回答的问题。
在 ASCII 码和 latin 中,字符编号与字节一一对应,这是一种编码方式。GB2312 则采用变长字节,这是另一种编码方式。而 Unicode 则存在多种编码方式,除了 最常用的 UTF-8 编码,还有 UTF-16 等。实际上,UTF-16 编码效率比 UTF-8 更高,但由于无法兼容 ASCII ,应用范围受到很大制约。
最佳实践
认识文本编码的前世今生之后,应该如何规避编码问题呢?是否存在一些最佳实践呢?答案是肯定的。
编码选择
项目开始前,需要选择一种适应性广的编码方案,UTF-8 是首选,好处多多:
- Unicode 是业界标准,编码字符数量最多,天然支持国际化;
- UTF-8 完全兼容 ASCII 码,这是硬性指标;
- UTF-8 目前应用最广;
如因历史原因,不得不使用中文编码方案,则优先选择 GB18030 。这个标准最新,涵盖字符最多,适应性最强。尽量避免采用 GBK ,特别是 GB2312 等老旧编码标准。
编程习惯
如果你使用的编程语言,字符串类型支持 Unicode ,那问题就简单了。由于 Unicode 字符串肯定不会导致诸如乱码等编码问题,你只需在输入和输出环节稍加留意。
举个例子,Python 从 3 以后, str 就是 Unicode 字符串了,而 bytes 则是 字节序列 。因此,在 Python 3 程序中,核心逻辑应该统一用 str 类型,避免使用 bytes 。文本编码、解码操作则统一在程序的输入、输出层中进行。
假如你正在开发一个 API 服务,数据库数据编码是 GBK ,而用户却使用 UTF-8 编码。那么,在程序 输入层 , GBK 数据从数据库读出后,解码转换成 Unicode 数据,再进入核心层处理。在程序 核心层 ,数据以 Unicode 形式进行加工处理。由于核心层处理逻辑可能很复杂,统一采用 Unicode 可以减少问题的发生。最后,在程序的 输出层 将数据以 UTF-8 编码,再返回给客户端。
整个过程伪代码大概如下:
# input
# read gbk data from database and decode it to unicode
data = read_from_database().decode(‘gbk‘)
# core
# process unicode data only
result = process(data)
# output
# encoding unicode data into utf8
response_to_user(result.encode(‘utf8‘))这样的程序结构看起来跟个三明治一样,非常形象:
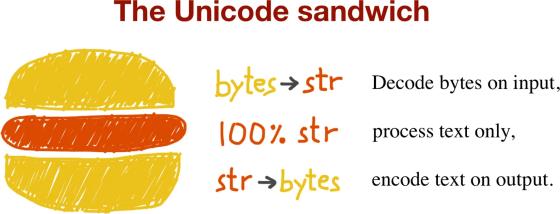
当然了,还有很多编程语言字符串还不支持 Unicode 。Python 2 中的 str 对象,跟 Python 3 中的 bytes 比较像,只是字节序列;C 语言中的字符串甚至更原始。
这都无关紧要,好的编程习惯是相通的:程序核心层统一使用某种编码,输入输出层则负责编码转换。至于核心层使用何种编码,主要看程序中哪种编码使用最多,一般是跟数据库编码保持一致即可。
附录
更多 Python 技术文章,请查看:Python语言小册 ,转至 原文 可获得最佳阅读体验。
https://www.cnblogs.com/fasionchan/p/coding.html
以上是关于一文说清文本编码那些事的主要内容,如果未能解决你的问题,请参考以下文章