DataNode
Posted lihui001
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DataNode相关的知识,希望对你有一定的参考价值。
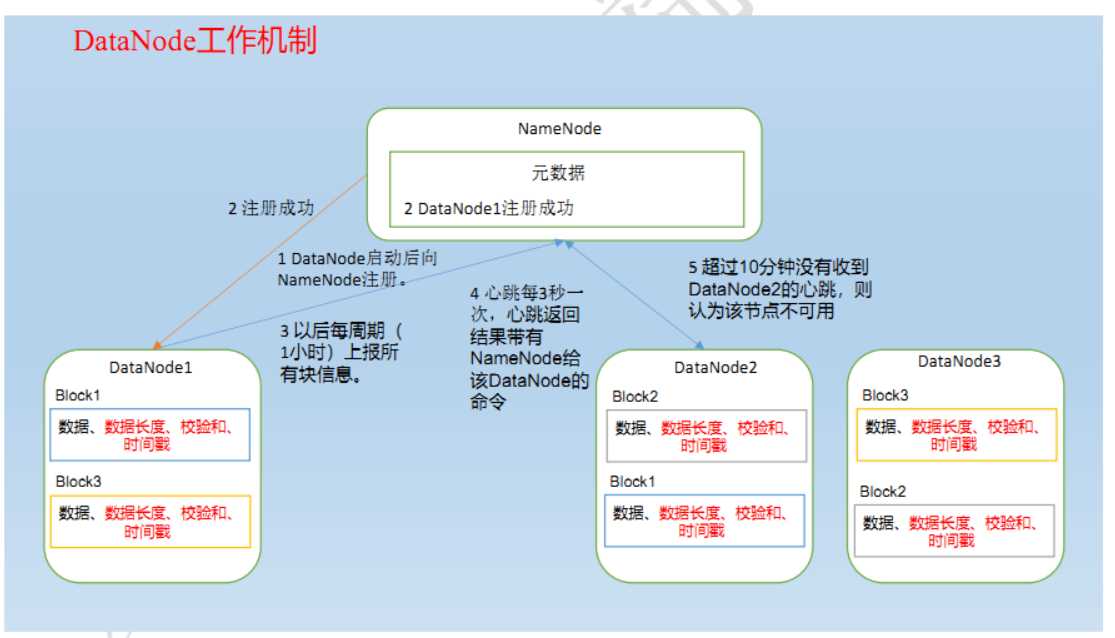
一:DataNode工作机制
(1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度、
快数据的校验和(验证数据完整性)以及时间戳
(2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息
(3)心跳是每3秒一次,心跳返回结果带有NameNode给DataNode的命令如复制块数据到另一台节点。
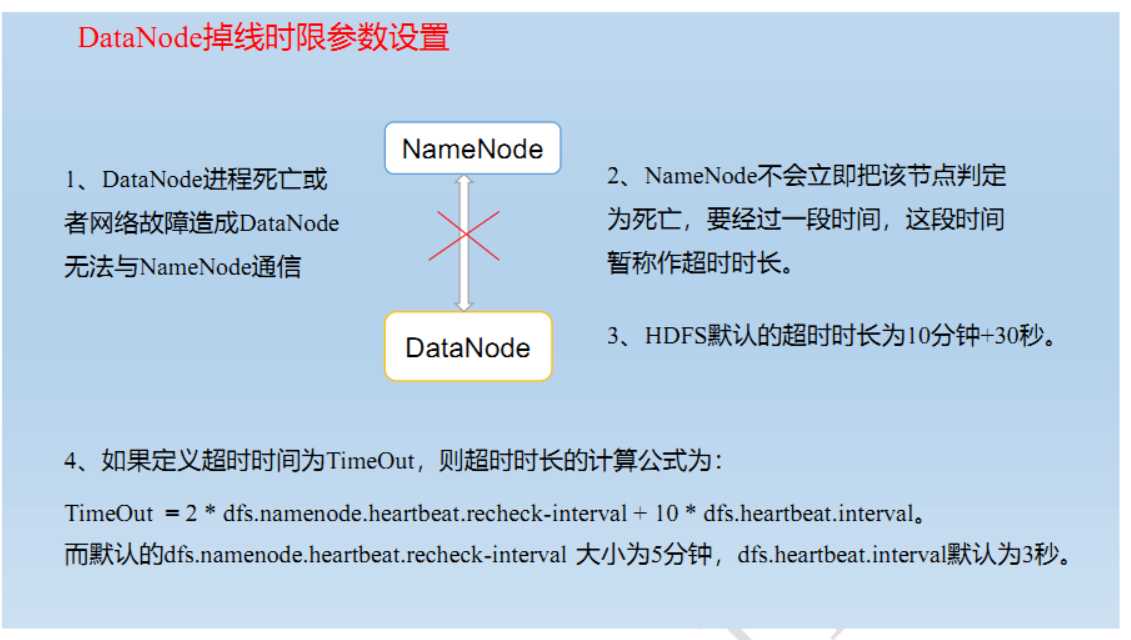
如果超过10分钟没有收到某个节点的心跳,则认为该节点已经不可用。
(4)集群运行中可以安全加入和退出节点。
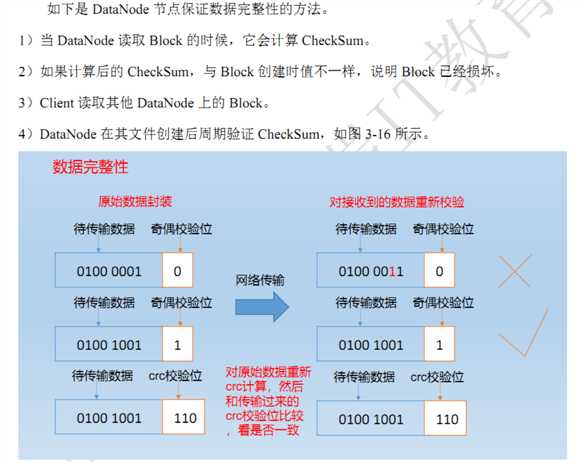
二:校验数据完整性
三:掉线时限参数设置

四:服役新数据节点(增加新数据节点)
(1)从其他数据节点再克隆一台数据节点
(2)修改ip地址和主机名
(3)删除原来HDFS文件系统留存下来的文件(data和logs)
(4)source一下配置文件
五:退役旧数据节点
白名单:添加到白名单的主机节点都可以访问NameNode,不在白名单上的主机节点不可用,在HDFS上也不会显示
黑名单:在黑名单上的数据节点不可用,但在HDFS上有显示记录
1:白名单设置步骤:
(1)在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts文件
(2)将允许访问NameNode的主机名称写在上面

(3)在NameNode的hdfs-site.xml配置文件增加dfs.hosts属性

(4)将配置文件分发到所有节点
(5)刷新NameNode
命令:hdfs dfsadmin -refreshNodes
(6)更新ResourceManager节点
命令:yarn rmadmin -refreshNodes
2:黑名单设置
(1)在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts.exclude文件
(2)添加要退役的节点的主机名称
(3)在NameNode的hdfs.site.xml配置文件中增加dfs.hosts.exclude属性
(4)刷新NameNode和ResourceManager
以上是关于DataNode的主要内容,如果未能解决你的问题,请参考以下文章