CVPR2019论文看点:自学习Anchor原理
Posted wujianming-110117
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CVPR2019论文看点:自学习Anchor原理相关的知识,希望对你有一定的参考价值。
CVPR2019论文看点:自学习Anchor原理
原论文链接:https://arxiv.org/pdf/1901.03278.pdf

CVPR2019的一篇对anchor进行优化的论文,主要将原来需要预先定义的anchor改成直接end2end学习anchor位置和size。首先anchor的定义通常为(x, y, w, h) (x, y为中心点),formulate一下:
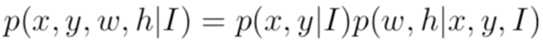
本文所提的guided anchoring利用两个branch分别预测anchor的位置和w、h:
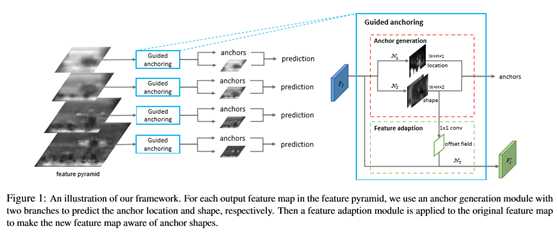
guided anchoring的主要内容有如下几点:
Anchor
Location Prediction
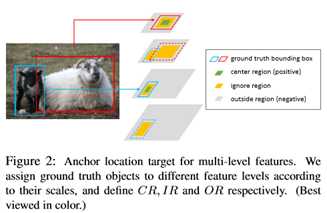
逻辑很简单,利用一个1x1的conv将输入的feature map转换成 W x H x 1的heatmap,通过卡阈值t来得到anchor可能出现的位置,在训练的时候可以通过gt的框来生成heatmap的groudtruth,negtive、positive、ignore的pixel定义论文中有比较详细的介绍。
Anchor Shape Prediction
这一部分逻辑和上一部分一样,也是通过一个1x1的conv将输入的feature map转换成W x H x 2的heatmap,只是考虑到如果直接回归w和h范围太广会比较不稳定,作者做了一定的转化将预测值约束到[-1,1],实际使用的时候再映射回去,s为feature map的stride,sigma为8:
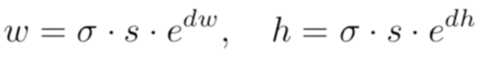
需要注意的是和传统的anchor设置不一样的是,guider anchoring在某一个pixel下只会设置一个anchor。
这一部分的训练其实会是比较需要特别注意的地方,论文中使用来IoU
loss来监督,但是这样存在一个问题,因为这个分支本身是预测w,h的,所以IoU Loss的计算无法知道match的具体gt,作者提出的方法是sample 9组常见的w、h,这样就可以利用这9组w、h构建9个不同的anchor去和gt匹配,IoU最大的匹配gt就是当前需要去计算IoU Loss的gt,然后直接用heatmap的w、h和这个gt计算IoU Loss即可:
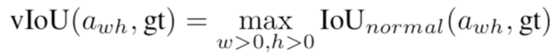
Anchor-Guided
Feature Adaptation
这一个模块主要是针对feature有可能和anchor不一致而提出的,因为对于原先预定义的anchor而言,每一个pixel对应位置的anchor其实都是一样的,所以也就无所谓feature的异同,但是guided
anchoring逻辑下不同的pixel有可能anchor的size差别很大,仍然像之前那样直接出cls和reg很显然是不合适的,所以作者就提出了adaptation的模块,利用deformable
conv来处理不同形状的anchor对应的feature。
论文的最后作者也提了一下因为GA-RPN可以得到很多高质量的porposal,通过提高阈值可以进一步优化检测的效果。
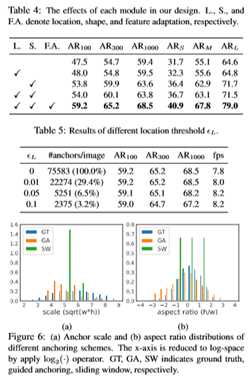
实验结果:
高质量 proposal 的正确打开方式
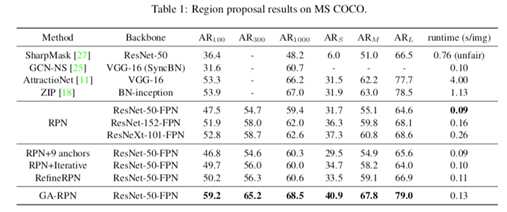
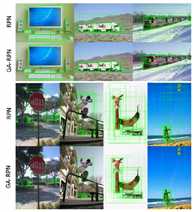
故事到这里其实也可以结束了,但是我们遇到了和之前一些改进 proposal 的 paper 里相同的问题,那就是 proposal 质量提升很多(如下图),但是在 detector 上性能提升比较有限。在不同的检测模型上,使用 Guided Anchoring 可以提升 1 个点左右。明明有很好的 proposal,但是 mAP 却没有涨很多,让人十分难受。
经过一番探究,我们发现了以下两点:1. 减少 proposal 数量,2. 增大训练时正样本的 IoU 阈值(这个更重要)。既然在 top300 里面已经有了很多高 IoU 的 proposal,那么何必用 1000 个框来训练和测试,既然 proposal 们都这么优秀,那么让 IoU 标准严格一些也未尝不可。
这个正确的打开方式基本是 独立调出来的,让 performance 一下好看了很多。通过这两个改进,在 Faster R-CNN 上的涨点瞬间提升到了 2.7 个点(没有加任何 trick),其他方法上也有大幅提升。
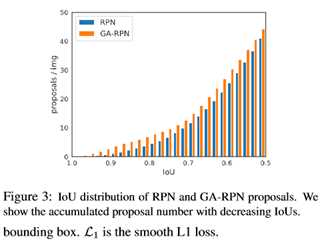
生成 anchor
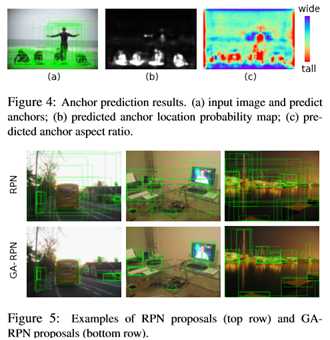
在得到 anchor 位置和中心点的预测之后,我们便可以生成 anchor 了,如下图所示。这时的 anchor 是稀疏而且每个位置不一样的。采用生成的 anchor 取代 sliding window,AR (Average Recall) 已经可以超过普通 RPN 4 个点了,代价仅仅是增加两个 1x1 conv。
实验结结果




以上是关于CVPR2019论文看点:自学习Anchor原理的主要内容,如果未能解决你的问题,请参考以下文章