科普 | 强化学习技术及应用
Posted txkjai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了科普 | 强化学习技术及应用相关的知识,希望对你有一定的参考价值。
导读
从一开始的AlphaGo击败世界冠军、到今天的自然语言处理、自动驾驶等,这与机器学习之强化学习算法息息相关。这股技术热浪也在逐年上升中。本文通俗语言简洁强化学习原理,马尔科夫过程,以及深度强化学习的应用。
概论
随着近些年人工智能领域的发展,机器学习技术被分为监督学习、无监督学习和强化学习三大类。其中对监督学习的研究最为广泛,该方法旨在通过已有的数据集,根据输入输出关系,建立一个最优模型,即给数据贴上标签,教会机器按照我们的想法做事情;无监督学习是根据输入的数据,主动寻找数据、特征之间的关系,即数据无标签,机器主动去学习搜索关系;强化学习则是介于监督和无监督之间的一种学习方式,即通过一种试错的方法,目标是根据输入输出的数据让机器在某个特定的环境中能做出最佳决策方案。
强化学习(Reinforcement Learning ,RL)在人工智能领域内已有了一席之地。它被广泛的应用在博弈、决策等领域。RL主要核心思想即智能体与环境之间的交互,目标在训练前就已设定,目的就是让智能体不断地根据设定累计奖励值,找到一个最优的动作策略实现目标。
强化学习应用的浪潮里也离不开深度学习的支撑,深度学习具有较强的感知能力,提升强化学习算法里获取状态信息等能力,使得强化学习具有更强的鲁棒性。对深度学习模型研究也层出不穷——卷积神经网络(CNN),循环神经网络(RNN)等。追溯强化学习兴起源于谷歌的人工智能团队在2016年的AlphaGo事件。在一场万人瞩目的比赛中AlphaGo首次击败世界冠军李世石。由此强化学习也逐渐被众人做关注。
本文意在概述强化学习原理、以AlphaGo、自然语言处理、自动驾驶为例,提出深度强化学习在人工智能领域发展的个人观点。
强化学习简述
强化学习所解决问题归结起来,即智能体通过自身状态,决定执行动作策略,从而实现目标。
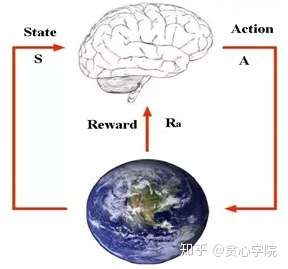


强化学习应用实例
典型深度强化学习AlphaGo
AlphaGo战胜李世石掀开了深度学习的热潮,其中战胜人类的关键技术就是深度强化学习。由10的172次方构成围棋的落子的状态空间,先是采用深度学习搜索有棋局到局部态势,最终到单个棋子这一复杂的状态空间。再利用强化学习中策略梯度搜索的方法构建策略网络和一个价值网络,策略网络用来记录棋局下一步落子状态,价值网络用来对落子这一动作进行评估,假如评估结果为胜利的概率较大,那么将加强对该棋子落子的选择,反之亦然。这种方法 大大增强的学习效率和搜索速度,最终推动了AlphaGo的成功。

强化学习在自然语言处理应用
运用计算机技术对自然语言处理一直受到广大研究人员的关注。随着人工智能的兴起,采用深度强化学习方法为自然语言处理方面注入新鲜血液,如机器翻译领域。
随着语言翻译转换需求量的大量增加,人工标记翻译耗费资源,针对面临双语互译问题遇到的瓶颈,神经机器翻译在这几年取得了很大的进步。在对偶机器翻译过程中,分别使用一种智能体代表主要任务模型,另一个智能体代表对偶的任务模型,通过强化学习的方法让两个只能体互教互学。在此过程中通过彼此之间反馈的信号更新两个翻译模型,直达迭代停止。我们把这种翻译的方式定义为对偶神经机器翻译(dual-NMT),具体描述如下:
1、 智能体A只能理解A语言,将A语言通过嘈杂的通道发送给只能理解B语言的B智能体。过程中使用翻译模型将A语言转换成B语言。
2、 当智能体B收到由模型翻译成B语言的句子。它检查句子是否存在智能体B的自然语句中(此时智能体B并不能验证译文的正确性,因为它看不懂原始信息)。然后它将收到的句子以另一翻译模型将其翻译成A语言返送给智能体A。
3、 收到来自智能体B发送的语言后,智能体A检查此信息是否和它发送的原始信息一致。整个过程构成了一个闭环,通过该反馈信号,智能体的两个模型可以相应的进行改进。
4、 这个过程也可以从智能体B发送原始信息开始执行,那么智能体翻译模型也将根据反馈信号彼此改进。
Dual-NMT有几个特征:第一,使用强化学习算法训练翻译模型的数据是未贴标签的,此项工作大大降低了对双语数据库的需求,使用从头翻译模型不断的学习训练,为翻译领域打开的新篇章。
强化学习在自动驾驶应用
近年来,自动驾驶技术已成为全世界汽车产业关注的对象,与传统汽车相比,自动驾驶在提高安全性的同时,能带来一定的舒适感。将自动驾驶的实现分为主要两部分:第一部分利用深度学习的强感知能力对车辆所处环境进行信息。第二部分即通过强化学习实现自主决策,这是自动驾驶“智能性”核心体现。自动决策难点在于复杂的环境场景与随机性的交通行人直接的博弈,强化学习就以一种“试错的方式”通过环境交互不断获得奖励值(舒适度、省油性、安全性),目的是使自身完成一种决策方案,累计奖励值最大。起初可能在实践中遇到行人、车辆偏离路线情况,根据算法先是采取随机动作,然后选取奖励值较大对应的动作,进而增强该动作的选择概率,降低不安全性、偏离轨道等选择概率,在不断训练过程中让智能体找到最适合的决策方案行驶。强化学习最大的特点是具有无师自通的能力,不依赖标签数据,也能对数据进行充分利用,因而成为了自动驾驶决策方法的研究热点。

个人观点
深度学习与强化学习相结合擦出的火花已取得了大量的研究成果,深度学习将自身感知能力的优势与强化学习具有决策能力相结合,解决了复杂环境所面临多状态多动作的问题。但是仍有很多问题亟待解决,例如在算法收敛方面高纬度马尔可夫决策面临维数灾难、学习效率不高等理论性缺点。
结语
强化学习算法已受到各个领域的广泛关注,学术和工业都在搜索与强化学习结合的可能性。特别是当传统的监督学习已经不能满足实际需要时,利用强化学习的优势可以更有效的利用数据,节约了大量的时间和资源。相信未来的一段时间内,强化学习在实际应用下会有更大的突破。
更多干货,请关注公众号:贪心科技AI
以上是关于科普 | 强化学习技术及应用的主要内容,如果未能解决你的问题,请参考以下文章