如何使用Logstash
Posted chenqionghe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用Logstash相关的知识,希望对你有一定的参考价值。
一、什么是Logstash
Logstash是一个日志收集器,可以理解为一个管道,或者中间件。
功能是从定义的输入源inputs读取信息,经过filters过滤器处理,输入到定义好的outputs输出源。
输入源可以是stdin、日志文件、数据库等,输出源可以是stdout、elesticsearch、HDFS等。
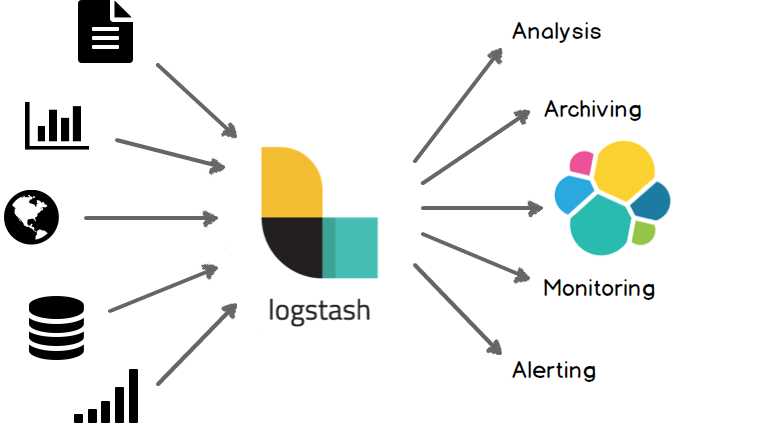
另外,Logstash不只是一个input | filter | output 的数据流,而是一个 input | decode | filter | encode | output 的数据流!有一个codec插件就是用来 decode、encode 事件的,可以解析我们经常用的json格式,非常的强大,接下来给大家演示一下Logstash的使用,一学就会。
二、如何安装
直接下载安装即可,查看下载地址,下载后解压如下
启动
bin/logstash -f logstash.conf三、快速使用
- 直接启动
./bin/logstash -e 'input { stdin { } } output { stdout {} }'
-e 代表可以从命令行读取配置,input { stdin { } } output { stdout {} }‘代表从标准stdin读取,从stdout输出,我们输入
chenqionghe
no pain, no gain.显示如下,logstash把时间等一些信息打印出来了

logstash会给事件添加一些额外的信息,最重要的就是 @timestamp,用来标记事件的发生时间。
此外,大多数时候,还可以见到host(地址)、type (类型)、tags (事件的某方面属性)。
- 使用配置启动
例如我们可以将上面的-e定义成一个chenqionghe.yml
input {
stdin { }
}
output {
stdout { }
}运行
./bin/logstash -f chenqionghe.yml更多配置查看 :configuration
四、Input输入插件
用来指定数据来源,可以是标准输入、文件、TCP数据、Syslog、Redis等
- 读取文件
例如,我要收集nginx的访问文件和错误文件,可以这样写
input {
file {
path => ["/Users/chenqionghe/web/log/nginx-access.log","/Users/chenqionghe/web/log/nginx-error.log"]
type => "nginx"
}
}
output {
stdout { codec => rubydebug }
}output指定了一个rubydebug,简单的理解就是一个调试输出的插件,后面会对output进行说明
结果运行,可以看到收集到了nignx日志

常用配置项
* discover_interval
logstash 每隔多久去检查一次被监听的 path 下是否有新文件。默认值是 15 秒。
* exclude
不想被监听的文件可以排除出去,这里跟 path 一样支持 glob 展开。
* sincedb_path
如果你不想用默认的 $HOME/.sincedb(Windows 平台上在 C:WindowsSystem32configsystemprofile.sincedb),可以通过这个配置定义 sincedb 文件到其他位置。
* sincedb_write_interval
logstash 每隔多久写一次 sincedb 文件,默认是 15 秒。
* stat_interval
logstash 每隔多久检查一次被监听文件状态(是否有更新),默认是 1 秒。
* start_position
logstash 从什么位置开始读取文件数据,默认是结束位置,也就是说 logstash 进程会以类似 tail -F 的形式运行。如果你是要导入原有数据,把这个设定改成 "beginning",logstash 进程就从头开始读取,有点类似 cat,但是读到最后一行不会终止,而是继续变成 tail -F。- 生成测试数据
例如可以使用generator来生成测试输入数据,下面的例子相当于循环了100次
input {
generator {
count => 100
message => '{"name":"chenqionghe","hello":["light","weight","baby"]}'
codec => json
}
}
output {
stdout {}
}运行如下

更多input查看:input-plugins
五、codec编码插件
事实上,我们在上面已经用过 codec 了 ,rubydebug 就是一种 codec,虽然它一般只会用在 stdout 插件中,作为配置测试或者调试的工具。
codec 使得 logstash 可以更好更方便的与其他有自定义数据格式的运维产品共存,比如 graphite、fluent、netflow、collectd,以及使用 msgpack、json、edn 等通用数据格式的其他产品等。
- SON编码
直接输入预定义好的 JSON 数据,以nginx的配置为例,添加如下配置,让nginx输出json
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"host":"$server_addr",'
'"client":"$remote_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"domain":"$host",'
'"url":"$uri",'
'"status":"$status"}';
access_log /Users/chenqionghe/web/log/nginx-access.log json;在logstash中配置
input {
file {
path => "/Users/chenqionghe/web/log/nginx-access.log"
codec => "json"
}
}
output {
stdout { codec => rubydebug }
}启动请求如下
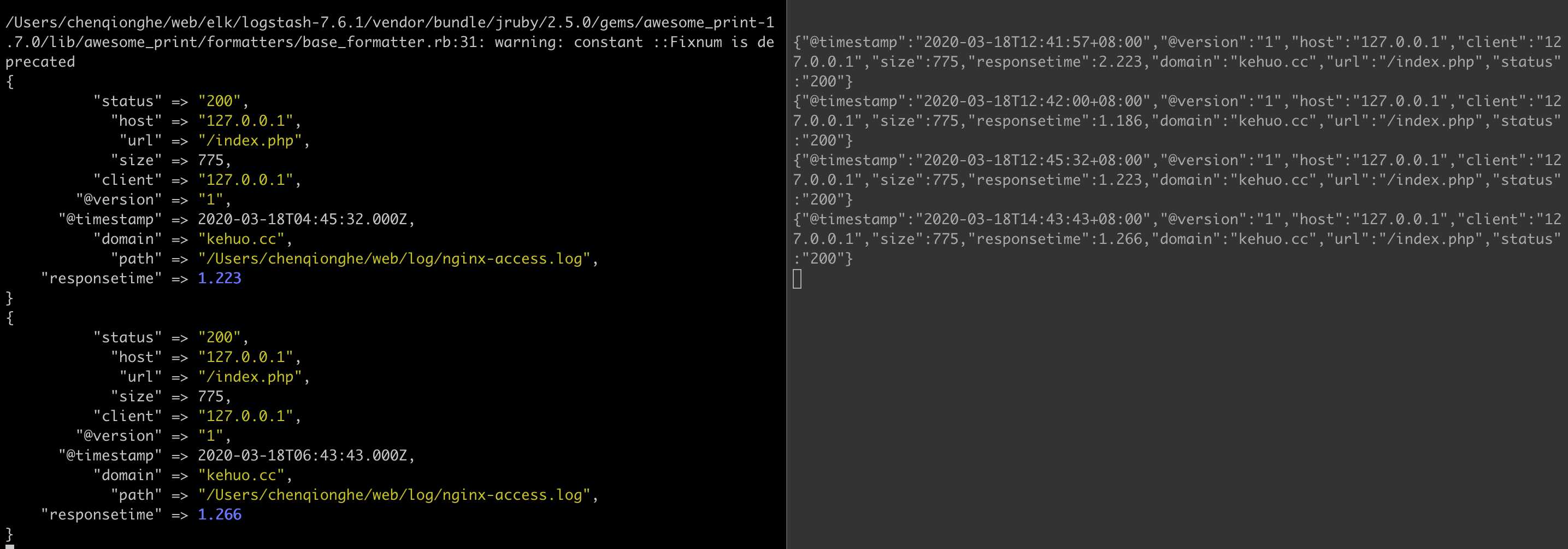
- 合并多行数据
multiline 插件可以收集多行数据,用于用于其他类似的堆栈式信息
示例如下
input {
stdin {
codec => multiline {
pattern => "^["
negate => true
what => "previous"
}
}
}输入
[2020-03-18 14:54:03] hello chenqionghe
[2020-03-18 14:54:03]hello gym
light weight baby
let's do it !
[2020-03-18 14:54:03] finished效果如下
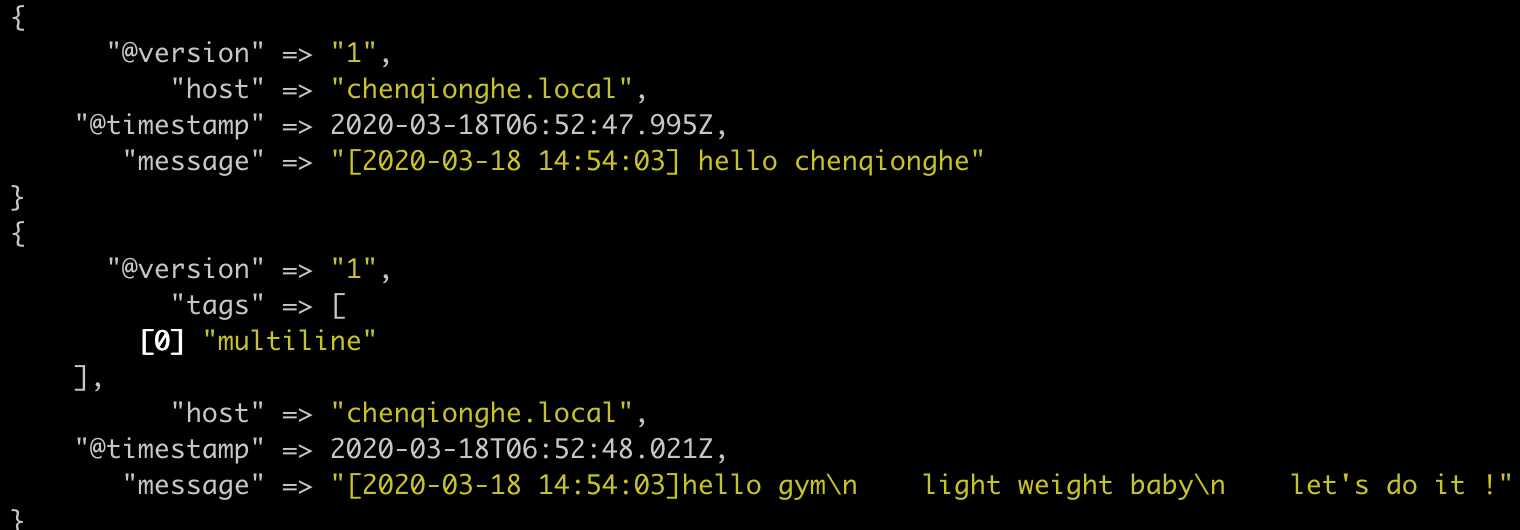
另外,codec还可以编解码protobuf、fluent、nmap等,可以参考:codec-plugins
六、filter过滤器插件
logstash 威力强大的最重要的就是因为有丰富的过滤器插件。
- Grok 正则捕获
Grok 是 Logstash 最重要的插件,可以在 grok 里预定义好命名正则表达式,在之后(grok参数或者其他正则表达式里)引用它,示例
input {stdin{}}
filter {
grok {
match => {
"message" => "s+(?<request_time>d+(?:.d+)?)s+"
}
}
}
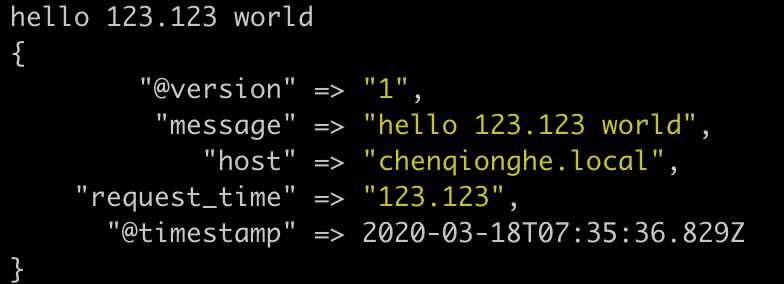
output {stdout{}}启动后输入
hello 123.123 world可以,看到配置到了我们自定义的变量request_time
- 时间处理
filters/date 插件可以用来转换你的日志记录中的时间字符串,变成 LogStash::Timestamp 对象,然后转存到 @timestamp 字段里。支持ISO8601、UNIX、UNIX_MS、TAI64N、Joda-Time 等格式
示例
input {stdin{}}
filter{
date{
match => ["message","yyyyMMdd"]
}
}
output {stdout{}}如下

- 数据修改
filters/mutate 提供了丰富的基础类型数据处理能力,包括类型转换,字符串处理和字段处理等。
转换类型,支持integer、float和string。
filter {
mutate {
convert => ["request_time", "float"]
}
}- 字符串处理
可以对字符串进行split、join、merge、strip、rename、replace等操作
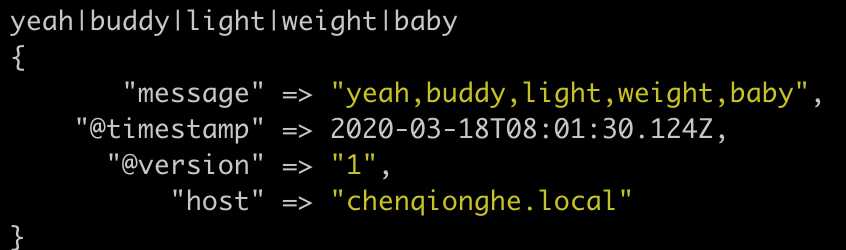
input {stdin{}}
filter {
mutate {
split => ["message", "|"]
}
mutate {
join => ["message", ","]
}
}
output {stdout{}}先用|分割成数组,再通过,合成字符串
- 拆分事件
split插件可以把一行数据,拆分成多个事件
input {stdin{}}
filter {
split {
field => "message"
terminator => "#"
}
}
output {stdout{}}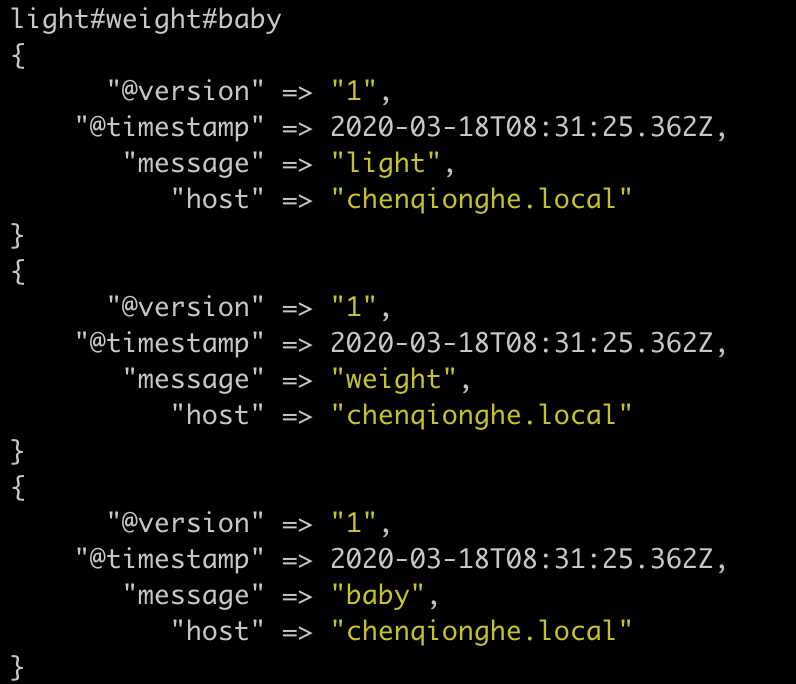
另外,还有JSON编解码、USerAgent匹配归类、Key-Value切分、自定义Ruby处理等插件,更多可以查看:filter-plugins
七、output输出插件
- 标准输出
和 inputs/stdin 插件一样,outputs/stdout 插件是最基础和简单的输出插件,如下
output {
stdout {
codec => rubydebug
}
}代表输出到stdout,使用rubydebug格式化
- 保存文件
input {stdin{}}
output {
file {
path => "/Users/chenqionghe/web/log/test.log"
}
}可以看到,已经写入test.log文件

- 输出到ElasticSearch
output {
elasticsearch {
host => "127.0.0.1"
protocol => "http"
index => "logstash-%{type}-%{+YYYY.MM.dd}"
index_type => "%{type}"
workers => 5
template_overwrite => true
}
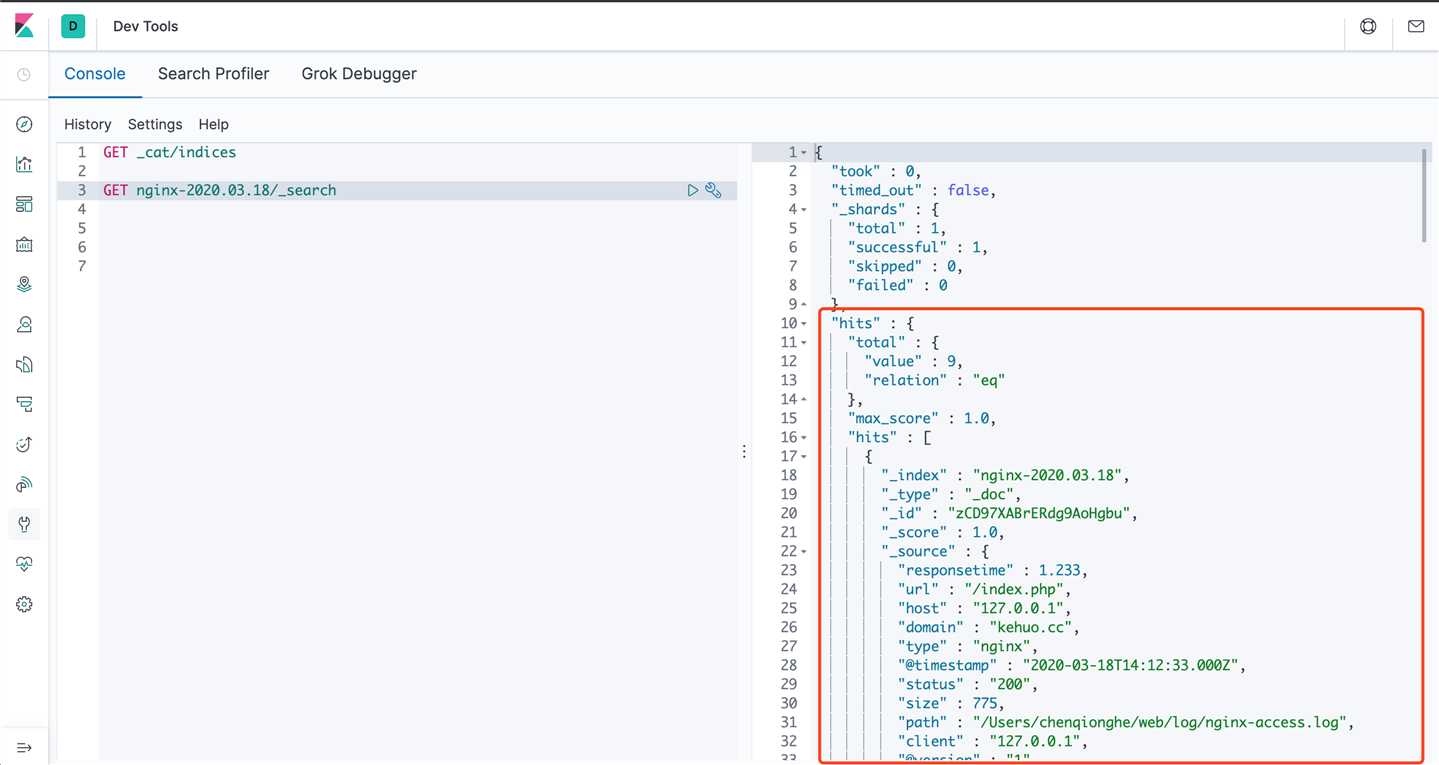
}启动后,请求nginx后日志如下

可以看到已经打印出来了,我们去使用kibana控制台查询es,可以看到索引和数据都已经有了

另外,output还可以设置输出到Redis、发送邮件、执行命令等,更多可以查看output-plugins
八、总结
简单地说,logstash最主要的功能是从input获取数据,通过filter处理,再输出到指定的地方。
一般我们收集日志都是在后台运行,建议使用nohup、screen或者supervisor这样的方式启动。
是不是觉得logstash超简单,意不意外,开不开心,yeah buddy! light weight baby!
以上是关于如何使用Logstash的主要内容,如果未能解决你的问题,请参考以下文章
kafkaThe group member needs to have a valid member id before actually entering a consumer group(代码片段
如何在 Javadoc 中使用 @ 和 符号格式化代码片段?