Prometheus(一)原理
Posted gaofeng-henu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Prometheus(一)原理相关的知识,希望对你有一定的参考价值。
简介
Prometheus是一个开源的监控、告警整体解决方案,最初由SoundCloud构建。从2012年开始,大量的公司开始适配Prometheus,拥有大量的开发者和非常活跃的用户社区。目前已作为独立的项目在运营,并与2016年加入CNCF,是继Kubernetes之后第二个被CNCF托管的项目。
特性
- 通过指标名称和标签(key/value对)区分的多维度、时间序列数据模型
- 灵活的查询语法 PromQL
- 不需要依赖额外的存储,一个服务节点就可以工作
- 利用http协议,通过pull模式来收集时间序列数据
- 需要push模式的应用可以通过中间件gateway来实现
- 监控目标支持服务发现和静态配置
- 支持各种各样的图表和监控面板组件
核心组件
整个Prometheus生态包含多个组件,除了Prometheus server组件其余都是可选的
- Prometheus server:主要的核心组件,用来收集和存储时间序列数据
- client libraries:提供个客户端,主要是用来帮助应用程序更容易生成满足Prometheus格式的监控数据,支持各种各样的开发语言
- push gateway:对于那些生存时间很短的job工作,采用Prometheus的pull模式可能来不及收集,可以部署这个组件,让job主动把监控指标push到getway,Prometheus再从getway中拉取
- 各种各样的exports
- alertmanager 一个告警组件
架构图
下面这张图,清晰的描绘出了Prometheus各个组件如何相互协作完成系统监控
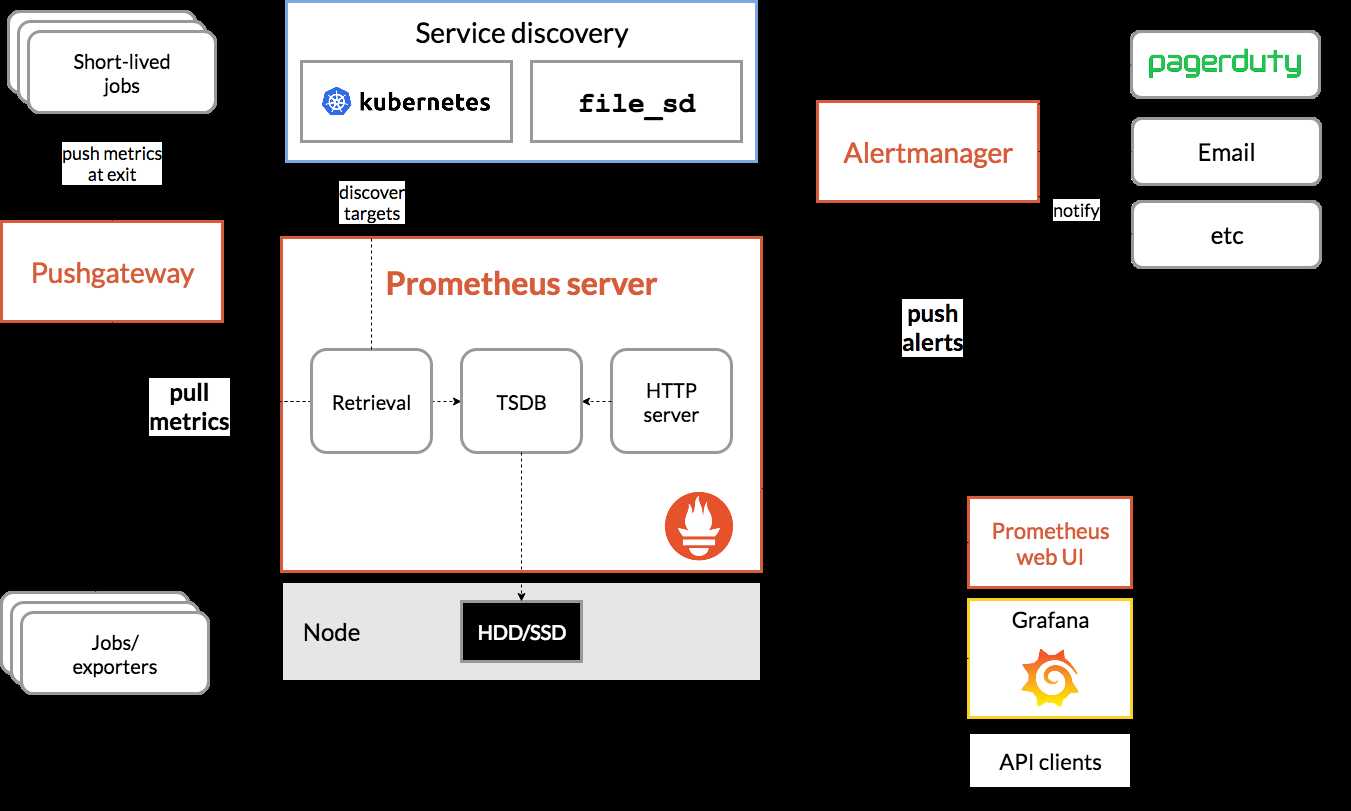
- Prometheus server利用各种各样的服务发现机制获取需要监控的target
- Prometheus server通过pull从各种各样的target处拉取指标数据
- 数据可视化组件(Grfana)通过PromQl从Prometheus server查询数据,进行展示
- Prometheus server根据自己定义的rule,可以提前对指标数据再次进行计算,触发报警的发送到alertmanager组件
- alertmanager组件根据配置的告警方式发送相应的通知
适用范围
Prometheus非常适合用来获取和存储纯粹数值型时间序列数据,如cpu使用率、系统访问量、数据更新频率等,所以多被用来对宿主机和微服务架构中的指标监控。
Prometheus非常的可靠,每个Prometheus server可以作为一个独立体进行部署,不用依赖其他服务或者是网络。所以在底层基础设施出现问题时,你还可以从Prometheus server中取出历史指标来分析问题出现的原因,并且Prometheus server运行时也不会占用很多的资源
不适用场景
因为Prometheus server是周期性pull指标信息的,所以收集的数据可能是不完整的(比如拉取间隔期间,目标服务出现故障,则这个间隔期间中的数据就获取不到),所以对于要求数据100%准确的场景如交易额统计等,Prometheus就不太适合了。对于Prometheus最好的用法就是来做监控,通过Prometheus收集的指标数据对系统的健康状态进行评判和报警处理。
以上是关于Prometheus(一)原理的主要内容,如果未能解决你的问题,请参考以下文章