Hbase总结
Posted bitbitbyte
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase总结相关的知识,希望对你有一定的参考价值。
HBase表的核心概念
总结
HBase的架构
Master
RegionServer
结构
功能
HBase的安装与shell操作
安装
启动与关闭
ddl与dml操作
ddl(表操作)
dml(数据操作)
HBase进阶
HBase的高性能原理
架构细节
读写流程
MemStore Flush
MemStore 刷写时机
合并与切分
JAVA API
HBase概述
Hbase是一张大表(十亿行 * 百万列), 可以支持十亿级数据量的秒级查询.
Hbase依赖于hadoop
Hbase实现了更高的性能, 但在一定程度上牺牲了数据的一致性,(部分一致性).
Hbase数据就是有版本, 一条数据可以有多个版本.
HBase与hive: HBase相当于一个数据库, 往hdfs中写入数据; 而hive为一个数据仓库, 支持表的关联操作 , 可以用作数据分析.
随机读写
hbase依赖于hdfs!hdfs本身不支持随机写!只支持追加写!
随机写: 追加写+时间戳
在查询时,只返回时间戳最大的数据!
HBase表的核心概念
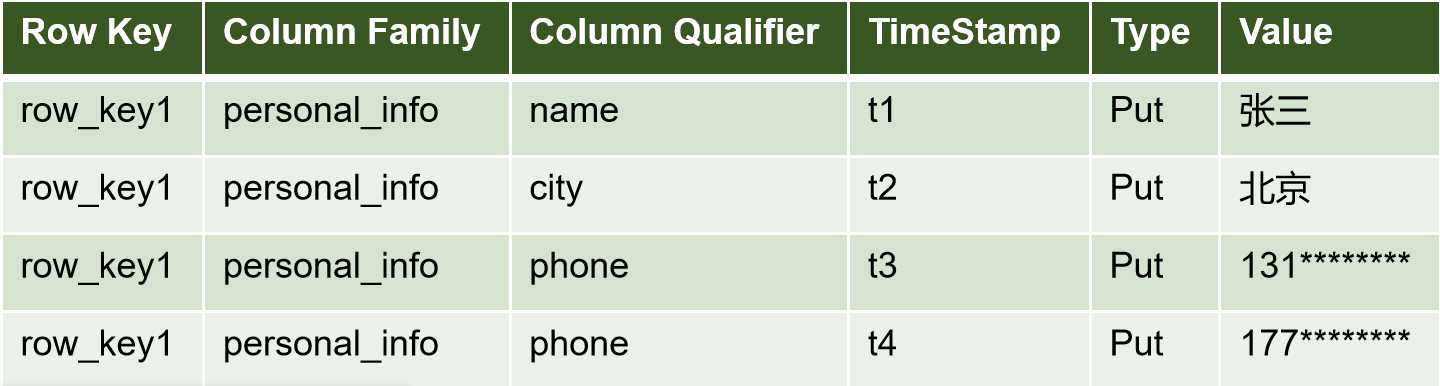
- namespace: 名称空间; 存放表的库
- table:表
- region: 区域(行组)。 一个表的若干行,组成一个region. region是服务端在处理请求时的最小单位, 由regionsServer管理.
- rowkey: 行键。 rowkey是一行唯一标识. 通过rowkey可以快速地检索到数据属于哪个region.
rowkey会在region中进行字典排序. - column family: 列族。由多个列组成. 一个列族在hdfs上为一个文件夹, 文件夹中由多个hfile文件组成. 列族是在建表时指定. 一个表的列族越少越好.
- column quliafier:
列名。列名是在插入数据时随意指定,不限类型,不限名称.
唯一限定的是列族名. - TimeStamp 标识数据的不同版本(version)。 时间戳默认由系统指定, 也可由用户指定。
在读取单元格的数据时,如果不指定, 默认会获取最新版本数据返回. - cell
最小的数据单位(即一个单元格). 确定了rowkey, 列名, 时间搓, 就确定了一个cell.
总结
确定一个指所需概念
库:表名, 行键, 列族名:列名, 时间搓, 值HBase的架构

Master
master负责表的管理 (DDL)
Table: create, delete, alterRegionServer
结构
Region server -> Region -> store(逻辑上的列族) -> StoreFile -> cell(数据的最小单元)
region :表的一个切片, 包含一整行所有字段
StoreFile由Mem Store刷写到磁盘, 保存为HFile格式的文件
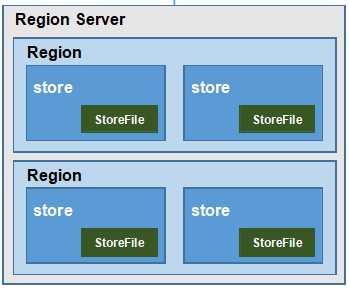
功能
- 表的数据的读写(DML).
- 分配region到RegionServer, 监控RegionSever的状态.
- region的合并(splitRegion)与拆分(compactRegion).
HBase的安装与shell操作
安装
- 环境要求
? HADOOP_HOME,JAVA_HOME,安装了zookeeper集群
- HBase的安装
? 解压即可!在环境变量中配置 HBASE_HOME
- 配置
? 修改 conf/hbase-env.sh
? 修改 conf/hbase-site.xml
启动与关闭
- 单节点启动
bin/hbase-daemon.sh start master
bin/hbase-daemon.sh start regionserver
- 群起/关闭
bin/start-hbase.sh
bin/stop-hbase.sh
ddl与dml操作
? HADOOP_HOME,JAVA_HOME,安装了zookeeper集群
? 解压即可!在环境变量中配置 HBASE_HOME
? 修改 conf/hbase-env.sh
? 修改 conf/hbase-site.xml
bin/hbase-daemon.sh start master
bin/hbase-daemon.sh start regionserverbin/start-hbase.sh
bin/stop-hbase.shhbase shell进入hbase的交互界面
ddl(表操作)
表操作有mater负责
- list
- create
create‘表名‘,‘列族名 1‘ ,‘列族名 2‘,创建列族, 而不是列.
- desc
- alter
alter 命令可以修改表的属性, 通常是修改某个列族的属性。
alter ‘表名’, ‘delete’ => ‘列族名hbase(main):050:0> alter ‘myns:t1‘,{NAME => ‘info‘,VERSIONS => ‘5‘}myns为表的命名空间
- disable
停用表后, 可以防止在对表做一些维护时, 客户端依然可以持续写入数据到表。
一般在删除表前, 必须停用表。
在对表中的列族进行修改时, 也需要停用表。disable_all ‘正则表达式’ 可以使用正则来匹配表名。
is_disabled 可以用来判断表是否被停用。 - enable
和停用表类似。 enable ‘表名’用来启用表, is_enabled ‘表名’ 用来判断一个表是否被启用。
enable_all ‘正则表达式’可以通过正则来过滤表, 启用复合条件的表。
- exists
- count
- drop
删除表前,需要先停用
- truncate
- get_split
获取表所对应的 Region 个数。 每个表在一开始只有一个 region, 之后记录增多后, region 会被自动拆分。
dml(数据操作)
数据的读写操作有RegionServer负责
- scan
scan 相当与select, 可以按照 rowkey 的字典顺序来遍历指定的表的数据。
- scan ‘表名‘:当前表的所有列族。
- scan ‘表名‘, {COLUMNS=> [‘列族:列名’ ],…}: 遍历表的指定列
- scan ‘表名‘, { STARTROW => ‘起始行键‘, ENDROW => ‘结束行键‘ }: 指定 rowkey 范围(区间为左闭右开)。
- scan ‘表名‘, { LIMIT => 行数量}: 指定返回的行的数量
- scan ‘表名‘, {VERSIONS => 版本数}: 返回 cell 的多个版本(cell是数据的最小单元)
- scan ‘表名‘, { TIMERANGE => [最小时间戳, 最大时间戳]}: 指定时间戳范围
注意: 此区间是一个左闭右开的区间, 因此返回的结果包含最小时间戳的记录, 但是不包含最大时间戳记录 - scan ‘表名‘, { RAW => true, VERSIONS => 版本数}
显示原始单元格记录, 在 Hbase 中, 被删掉的记录在 HBase 被删除掉的记录并不会立即从磁盘上清除, 而是先被打上墓碑标记, 然后等待下次 major compaction 的时候再被删除掉。 注意 RAW 参数必须和 VERSIONS 一起使用,但是不能和 COLUMNS 参数一起使用。 - scan ‘表名‘, { FILTER => "过滤器"} and|or { FILTER => "过滤器"}: 使用过滤器扫描
- put
put 可以新增记录还可以为记录设置属性。
put 库:表名, 行键, 列族名:列名, 值, [时间搓]
put ‘表名‘, ‘行键‘, ‘列名‘, ‘值‘ put ‘表名‘, ‘行键‘, ‘列名‘, ‘值‘,时间戳 put ‘表名‘, ‘行键‘, ‘列名‘, ‘值‘, { ‘属性名‘ => ‘属性值‘} put ‘表名‘, ‘行键‘, ‘列名‘, ‘值‘,时间戳, { ‘属性名‘ =>‘属性值‘}HBase(main):012:0> put ‘student‘,‘1001‘,‘info:name‘,‘Nick‘ HBase(main):003:0> put ‘student‘,‘1001‘,‘info:sex‘,‘male‘ HBase(main):004:0> put ‘student‘,‘1001‘,‘info:age‘,‘18‘ - get
get 支持 scan 所支持的大部分属性, 如
COLUMNS,TIMERANGE,VERSIONS,FILTERHBase(main):014:0> get ‘student‘,‘1001‘ HBase(main):015:0> get ‘student‘,‘1001‘,‘info:name‘ - delete
删除某
rowkey的全部数据:HBase(main):016:0> deleteall ‘student‘,‘1001‘删除某
rowkey的某一列数据:HBase(main):017:0> delete ‘student‘,‘1002‘,‘info:sex‘
HBase进阶
HBase的高性能原理
架构细节
读写流程
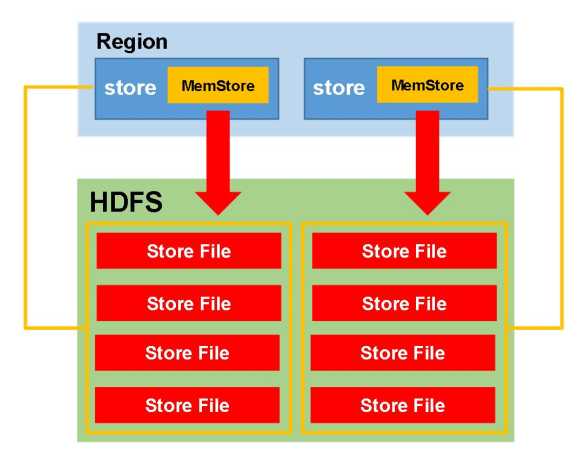
MemStore Flush
MemStore会根据一定时机向磁盘刷写, 生成StoreFile文件(即 HFile格式文件).
刷写的意义:
1.
2.
MemStore 刷写时机
- 手动刷写
由于Memstore刷写会占用大量资源, 在生产环境中一般在空闲时手动刷写.
flush ‘表名’ flush ‘region名’ - 基于内存占用
- 当某个 memstore 的大小达到了
hbase.hregion.memstore.flush.size(默认值 128M), 其所在 region 的所有memstore 都会刷写
默认128M
- 当 memstore 的大小达到了
hbase.hregion.memstore.flush.size(默认值 128M) × `hbase.hregion.memstore.block.multiplier(默认值 4)时, **会阻止继续往该 memstore 写数据。**(同时flush) > 128 * 4 3. 当 region server 中 memstore 的总大小达到java_heapsize
× hbase.regionserver.global.memstore.size(默认值 0.4)
× `hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95)region 会按照其所有 memstore 的大小顺序(由大到小) 依次进行刷写。 直到 region server 中所有 memstore的总大小减小到上述值以下。 > jvm堆内存 * 0.4 * 0.95
- 当某个 memstore 的大小达到了
- 基于时间的刷写
到 达 自 动 刷 写 的 时 间 , 也 会 触 发 memstore flush 。 自 动 刷 新 的 时 间 间 隔 由 该 属 性 进 行 配 置
hbase.regionserver.optionalcacheflushinterval(默认 1 小时)。
合并与切分
JAVA API
以上是关于Hbase总结的主要内容,如果未能解决你的问题,请参考以下文章