磁盘IO网络IOzero copy
Posted pluto-yang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了磁盘IO网络IOzero copy相关的知识,希望对你有一定的参考价值。
IO访问方式
磁盘IO
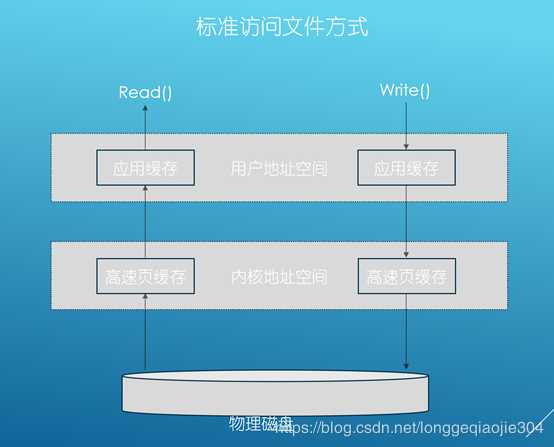
具体步骤:
当应用程序调用read接口时,操作系统检查内核缓冲区中是否存在需要的数据,如果存在,就直接从内核缓存中直接返回,否则从磁盘中读取,然后缓存至操作系统的缓存中。
当应用程序调用write接口时,将数据直接从用户地址空间复制到内核地址空间的缓存中,这时对用户程序来说,写操作已经完成了,至于什么时候写入磁盘中,由操作系统决定,除非显示调用sync同步命令。
网络IO
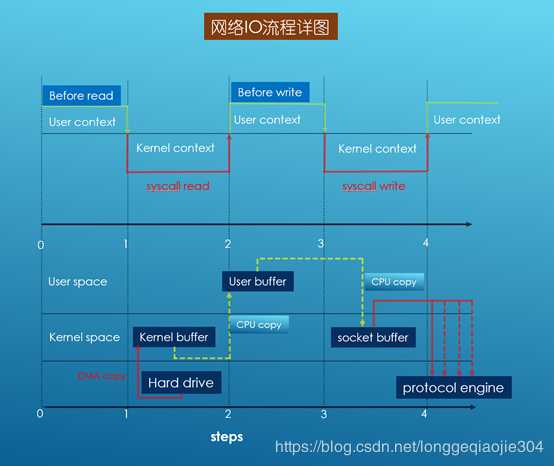
1、当调用系统read接口时,通过DMA(Direct Memory Access)将数据拷贝到内核缓冲区;
2、然后由CPU控制,将内核缓冲区的数据拷贝到用户模式的buffer中;
3、当调用系统write接口时,会把用户模式下buffer数据拷贝到内核缓冲区的Socket Buffer中;
4、最后通过DMA copy将内核模式下的socket buffer中数据拷贝到网卡设备中传输。
从上面整个read、write过程来看,数据白白从内核模式到用户模式走了一圈,浪费了两次copy,而这两次有需要CPU copy,即占用CPU资源。
DMA(直接存储器访问):
直接存储器存取(DMA)用来提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。 你只要使能并配置好了DMA,DMA就可以将一批数据从源地址搬运到目的地址去而不经过CPU的干预
要进行数据传输就必须有两个条件:数据从哪传(源地址),数据传到哪里去(目的地址)。是的DMA的确有这两项设置,通过软件设置,设置好源地址和目的地址。
磁盘IO与网络IO对比
磁盘IO主要延迟是由(以15000rpm硬盘为例):机械转动延时(机械硬盘为主要性能瓶颈,平均2ms)+寻址延时*(2-3ms)+块传输延时(一般4k每块,40m/s的传输速度,延时一般为0.1ms)决定。(平均为5ms)
网络IO主要延时是由:服务器响应延时+带宽限制+网络延时+跳转路由延时+本地接收延时 决定。(一般为几十到几千毫秒,受环境影响较大)
所以,一般来说,网络IO延时要大于磁盘IO延时。
用户缓冲区:
IO,其实意味着:数据不停地搬入搬出缓冲区而已(使用了缓冲区)。比如,用户程序发起读操作,导致“ syscall read ”系统调用,就会把数据搬入到 一个buffer中;用户发起写操作,导致 “syscall write ”系统调用,将会把一个 buffer 中的数据 搬出去(发送到网络中 or 写入到磁盘文件)。
DMA(Direct Memory Access,直接内存存取,不需要CPU参与,下面有解释) 是所有现代电脑的重要特色,它允许不同速度的硬件装置来沟通,而不需要依赖于 CPU 的大量中断负载。
整个IO过程的流程如下:
1)程序员写代码创建一个缓冲区(这个缓冲区是用户缓冲区):哈哈。然后在一个while循环里面调用read()方法读数据(触发"syscall read"系统调用)
byte[] b = new byte[4096]; while((read = inputStream.read(b))>=0) { total = total + read; // other code.... }
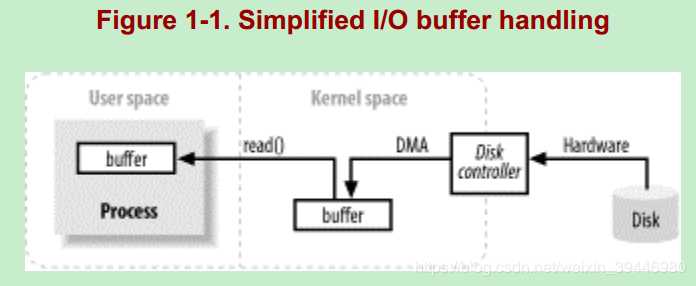
2)当执行到read()方法时,其实底层是发生了很多操作的: ①内核给磁盘控制器发命令说:我要读磁盘上的某某块磁盘块上的数据。②在DMA的控制下,把磁盘上的数据读入到内核缓冲区。③内核把数据从内核缓冲区复制到用户缓冲区。这里的用户缓冲区应该就是我们写的代码中 new 的 byte[] 数组。
内核缓冲区(kernel space):
操心系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核,保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。每个进程可以通过系统调用进入内核,因此,Linux内核由系统内的所有进程共享。
对于操作系统而言,JVM只是一个用户进程,处于用户态空间中。而处于用户态空间的进程是不能直接操作底层的硬件的。而IO操作就需要操作底层的硬件,比如磁盘。因此,IO操作必须得借助内核的帮助才能完成(中断,trap),即:会有用户态到内核态的切换。
我们写代码 new byte[] 数组时,一般是都是“随意” 创建一个“任意大小”的数组。比如,new byte[128]、new byte[1024]、new byte[4096]....,即用户缓冲区,但是,对于磁盘块的读取而言,每次访问磁盘读数据时,并不是读任意大小的数据的,而是:每次读一个磁盘块或者若干个磁盘块(这是因为访问磁盘操作代价是很大的,而且我们也相信局部性原理) 因此,就需要有一个“中间缓冲区”--即内核缓冲区。先把数据从磁盘读到内核缓冲区中,然后再把数据从内核缓冲区搬到用户缓冲区。这也是为什么我们总感觉到第一次read操作很慢,而后续的read操作却很快的原因吧。因为,对于后续的read操作而言,它所需要读的数据很可能已经在内核缓冲区了,此时只需将内核缓冲区中的数据拷贝到用户缓冲区即可,并未涉及到底层的读取磁盘操作,当然就快了。
NIO中的内存映射:
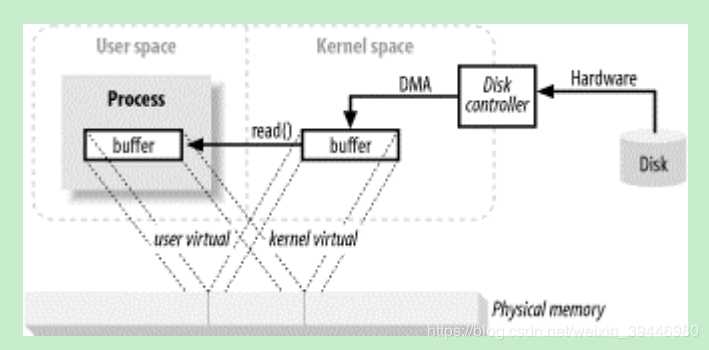
内核空间的 buffer 与 用户空间的 buffer 都映射到同一块 物理内存区域。当用户进程访问“内存映射文件”(即用户缓存)地址时,自动产生缺页错误,然后由底层的OS负责将磁盘上的数据送到物理内存区域,用户访问用户空间的 buffer时,直接转到物理内存区域,这就是直接内存映射IO,也即JAVA NIO中提到的内存映射文件,或者说 直接内存....总之,它们表达的意思都差不多。
传统的IO读写有两种方式:IO中断和DMA。他们各自的原理如下。
1、IO中断原理

整个流程如下:
- 1.用户进程调用read等系统调用向操作系统发出IO请求,请求读取数据到自己的内存缓冲区中。自己进入阻塞状态。
- 2.操作系统收到请求后,进一步将IO请求发送磁盘。
- 3.磁盘驱动器收到内核的IO请求,把数据从磁盘读取到驱动器的缓冲中。此时不占用CPU。当驱动器的缓冲区被读满后,向内核发起中断信号告知自己缓冲区已满。
- 4.内核收到中断,使用CPU时间将磁盘驱动器的缓存中的数据拷贝到内核缓冲区中。
- 5.如果内核缓冲区的数据少于用户申请的读的数据,重复步骤3跟步骤4,直到内核缓冲区的数据足够多为止。
- 6.CPU将数据从内核缓冲区拷贝到用户缓冲区,同时从系统调用中返回。完成任务。
缺点:用户的每次IO请求,都需要CPU多次参与。
2、DMA原理

- 1.用户进程调用read等系统调用向操作系统发出IO请求,请求读取数据到自己的内存缓冲区中。自己进入阻塞状态。
- 2.操作系统收到请求后,进一步将IO请求发送DMA。然后让CPU干别的活去。
- 3.DMA进一步将IO请求发送给磁盘。
- 4.磁盘驱动器收到DMA的IO请求,把数据从磁盘读取到驱动器的缓冲中。当驱动器的缓冲区被读满后,向DMA发起中断信号告知自己缓冲区已满。
- 4.DMA收到磁盘驱动器的信号,将磁盘驱动器的缓存中的数据拷贝到内核缓冲区中。此时不占用CPU(IO中断这里是占用CPU的)。这个时候只要内核缓冲区的数据少于用户申请的读的数据,内核就会一直重复步骤3跟步骤4,直到内核缓冲区的数据足够多为止。
- 5.当DMA读取了足够多的数据,就会发送中断信号给CPU。
- 6.CPU收到DMA的信号,知道数据已经准备好,于是将数据从内核拷贝到用户空间,系统调用返回。
跟IO中断模式相比,DMA模式下,DMA就是CPU的一个代理,它负责了一部分的拷贝工作,从而减轻了CPU的负担。
DMA的优点就是:中断少,CPU负担低。
文件到网络场景的zero copy技术
1、传统IO读写方式的问题
在读取文件数据然后发送到网络这个场景中,传统IO读写方式的过程如下。

由图可知,整个过程总共发生了四次拷贝和四次的用户态和内核态的切换。
用户态和内核态的切换如下。借个网上的图。

2、zero copy技术

zero copy技术就是减少不必要的内核缓冲区跟用户缓冲区间的拷贝,从而减少CPU的开销和内核态切换开销,达到性能的提升。
zero copy下,同样的读取文件然后通过网络发送出去,只需要拷贝三次,只发生两次内核态和用户态的切换。
再次盗用一下别人的图。

linux下的zero copy技术
linux下的用来实现zero copy的常见接口由如下几个:
- ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count)
- long splice(int fdin, int fdout, size_t len, unsigned int flags);
这两个接口都可以用来在两个文件描述符之间传输数据,实现所谓的zero copy。
splice接口则要求两个文件描述符中至少要有一个是pipe。
sendfile跟splice的局限性
上面提到的用来实现零拷贝的sendfile和splice接口,仅限于文件跟文件,文件跟sock之间传输数据,但是没法直接在两个socket之间传输数据的。这就是sendfile和splice接口的局限性。
如果要实现socket跟socket之间的数据直接拷贝,需要开辟一个pipe,然后调用两次splice。这样还是带来跟传统IO读写一样的问题。系能其实并没有什么大的提升。
以上是关于磁盘IO网络IOzero copy的主要内容,如果未能解决你的问题,请参考以下文章
Java 两种zero-copy零拷贝技术mmap和sendfile的介绍