KNN算法(K近邻算法)实现与剖析
Posted ss-py
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KNN算法(K近邻算法)实现与剖析相关的知识,希望对你有一定的参考价值。
KNN(K-Nearest Neighbors)算法,又称K近邻算法,单从字面意思我们就能知道,这个算法肯定是和距离有关的。
KNN算法的核心思想:
在一个特征空间中,如果某个样本身边和他最相邻的K个样本大多都属于一个类别,那么这个样本在很大程度上也属于这个类别,且该样本同样具有这个类别的特性。
其实说白了就是“近朱者赤、近墨者黑”,你身边离你最近的K个人中大多数人都属于某一个类别,那么你很有可能也属于这一个类别(当然,用人来举例子不是很恰当)
该方法在“分类决策”上只依据最近邻的k个样本的类别来判断待分样本的类别,K通常是不大于20的一个整数,具体怎么选取,这个也很有学问,后边会详细讲解。
上边说了,一个待分样本的所属的类别,很大程度上取决于和他最近的K个样本的类别,那么这个“最近”是如何计算出来的呢,比如一堆人站在一块儿,我们可以可以轻易的计算出
一个人距他身边的每个人的距离,那么数据呢?其实道理是一样的,我们可以使用欧拉距离来计算,其实我们在中学几何中学习二维平面内两点间距离、三维空间内两点间距离时已经学过了,
我们可以将二维数据看作是这两个点都只有两个特征,三维数据可以看成是有三个特征,那么当一组数据中每个数据都有多个特征时,我们也可以将其看作是多维空间中的一个点,
也同样可以使用欧拉距离来计算。

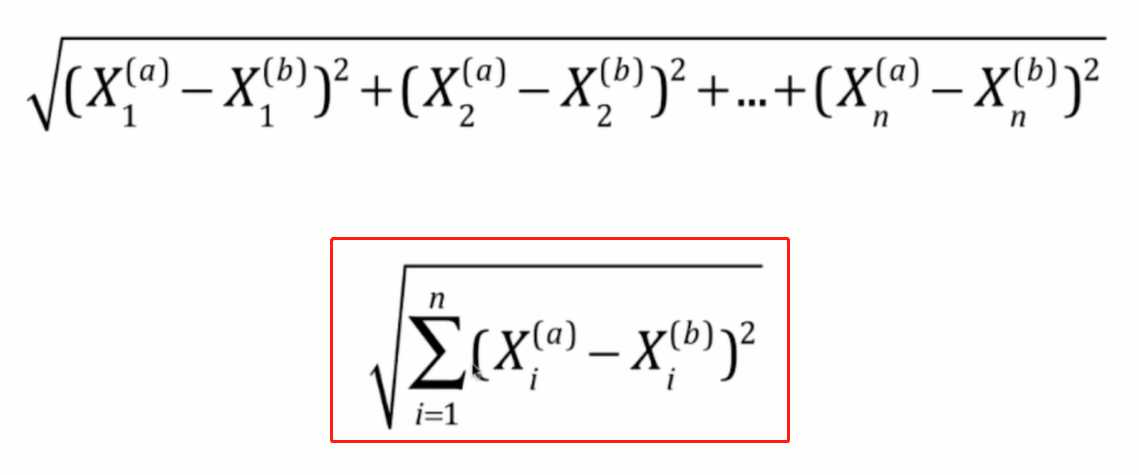
当拓展到多个特征之后,就会简写成上边红框中的公式,这在机器学习算法中较为常见。
KNN算法的计算步骤:
(1)计算待分类数据与各个样本数据之间的距离
(2)对距离进行排序
(3)选取距离最小的前K个点
(4)统计前k个点所属的类别
(5)返回前K个点出现频率最高的类别做为待分类数据的预测分类
手动封装一个KNN算法:
import math import numpy as np from collections import Counter class NKKClass(object): def __init__(self, K): # 初始化KNN类属性 assert K > 0, "常数K需为正整数" self.K = K self._X_train = None # 私有的训练特征数组 self._y_train = None # 私有的训练标签向量 def fit(self, X_train, y_train): # 根据训练特征数组X_train和标签向量y_train来训练模型(当然,KNN算法中是不需要训练模型的) self._X_train = X_train self._y_train = y_train def predict(self, X_predict): # 传入待预测的特征数据集X_predict,返回这个特征数据集所对应的标签向量 y_predict = [self._predict(i) for i in X_predict] return y_predict def _predict(self, i): # 给定单个特征数据,根据计算欧拉距离,返回预测标签 # 利用欧拉距离计算两点间距离 distances = [ math.sqrt(np.sum((x_train - i)**2)) for x_train in self._X_train] nearset = np.argsort(distances) #将数组升序排序,然后提取其所对应的索引index进行返回 # 根据索引取出标签向量中的值 topK_y = [ self._y_train[index] for index in nearset[:self.K]] # 统计array中每个元素出现频率,n=1表示取出出现频率最高的那个元素 votes = Counter.most_common(n=1)[0][0] return votes
def accuracy_score(self, y_test, y_predict): # 根据train_test_split得到的y_test和预测得到的y_predict计算分类准确度 return sum(y_true == y_predict) / len(y_true)
def score(self, X_test, y_test): # 根据 train_test_split拆分出来的X_test,y_test直接计算分类准确度 y_predict = self.predict(X_test) return self.accuracy_score(y_test, y_predict)
上边这个类其实就是模仿着 scikit-learn机器学习库中封装的的kNN算法来写的。
下边我们来加载 sklearn 库中自带的鸢尾花数据集来测试一下吧
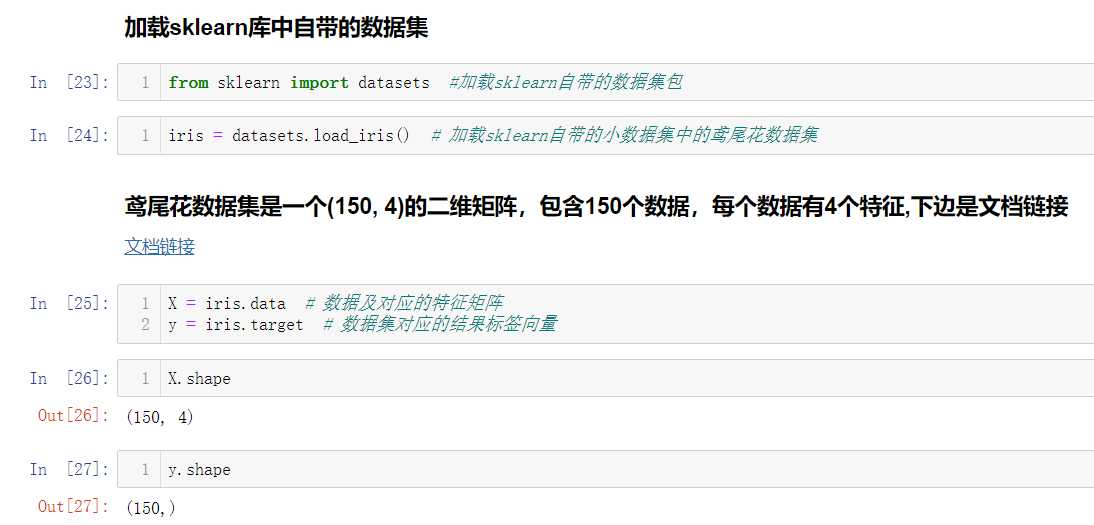
我们获取到数据集后,并不能直接将所有数据集都作为训练数据集,还是需要留下一小部分作为测试数据集的,所以又牵扯到train_test_split的问题,而且鸢尾花数据集已经默认排过序了,
所以我们在进行train_test_split之前还需要先将特征数据集和标签向量进行乱序才行的。
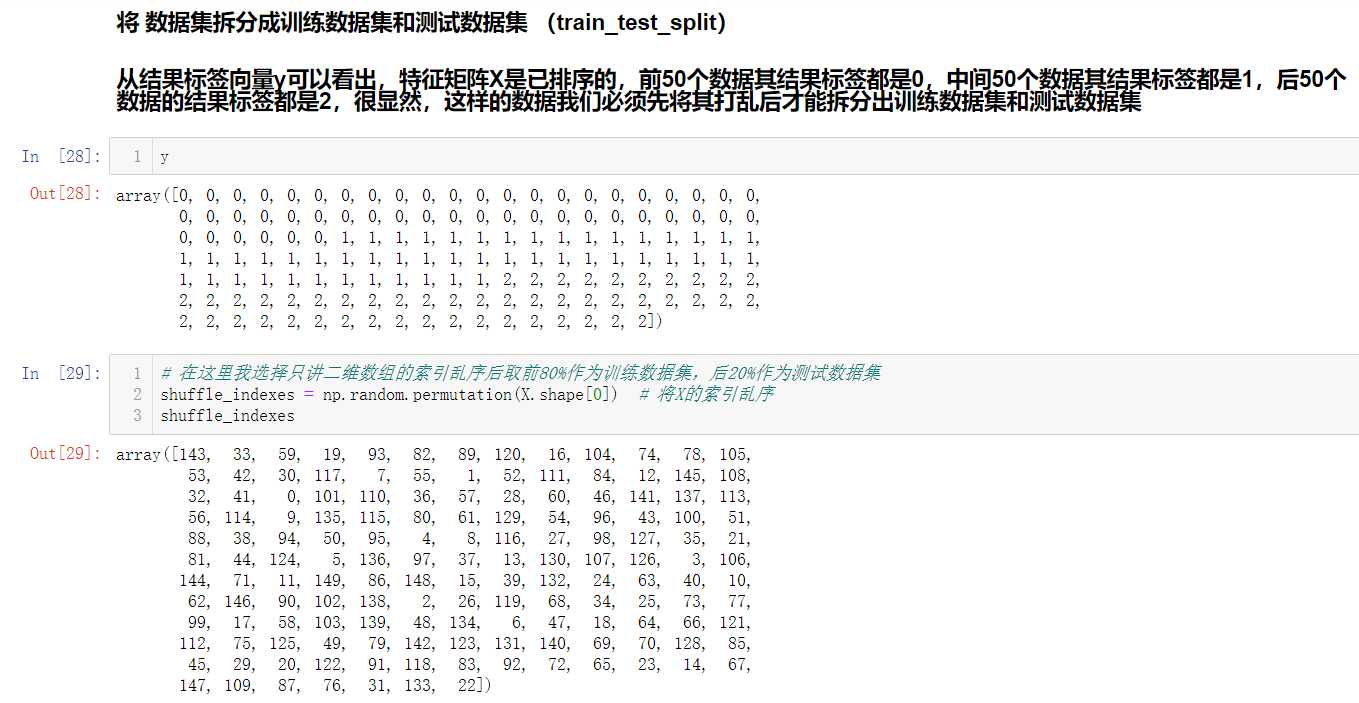
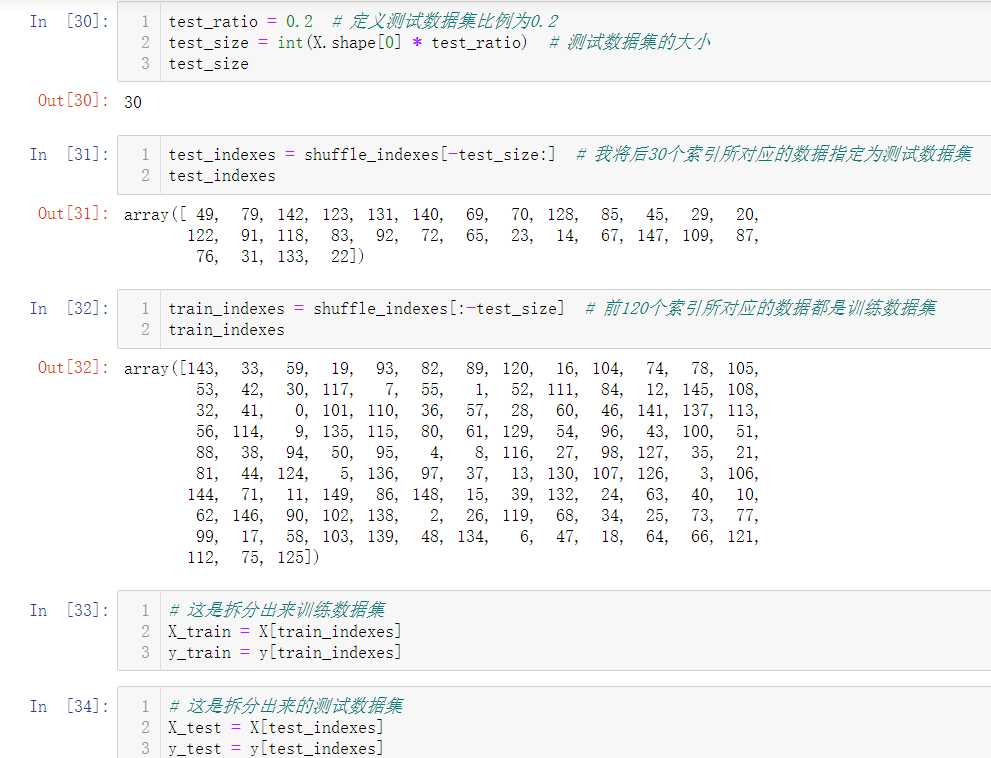
其实这个train_test_split过程,在sklearn中已经封装好了,可以直接调用。
from sklearn.model_selection import train_test_split
train_test_split函数有4个参数,并且返回四个返回值:
4个参数:
train_data:需要被拆分的特征数组
train_target:需要被拆分的标签向量
test_size:如果是浮点数,在0-1之间,表示测试数据集占总数据集的百分比,如果是整数,代表测试数据集的行数。
random_state:随机种子,默认为None
4个返回值:
X_train 训练特征数组
X_test 测试特征数组
y_train 训练标签向量
y_test 测试标签向量
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
接下来调用sklearn库,直接使用KNN算法对鸢尾花数据集进行预测,计算分类准确度:
# 加载sklearn库中KNN算法的类 from sklearn.neighbors import KNeighborsClassifier # 加载sklearn自带的数据包 from sklearn import datasets # 加载sklearn自带的train_test_split函数 from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 加载数据包中自带的小数据集(鸢尾花数据集) iris = datasets.load_iris() X = iris.data # 数据集的特征矩阵 y = iris.target # 数据集的标签向量 # 将数据集拆分,二八分 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=5) # 实例化,n_neighbors就是KNN算法中的那个K KNN_classifier = KNeighborsClassifier(n_neighbors=6) KNN_classifier.fit(X_train, y_train) # 对训练数据集进行拟合 predict_y_test = KNN_classifier.predict(X_test) # 对测试的特征数组进行预测 # 针对train_test_split得到的y_test和预测出来的标签向量进行计算分类准确度 Classification_accuracy = accuracy_score(y_test, predict_y_test) print(Classification_accuracy) # 针对train_test_split得到的测试用的特征数组和标签向量,直接计算其分类准确度(不用先计算出测试标签向量) Classification_accuracy = KNN_classifier.score(X_test, y_test) print(Classification_accuracy)

以上是关于KNN算法(K近邻算法)实现与剖析的主要内容,如果未能解决你的问题,请参考以下文章
机器学习实战☛k-近邻算法(K-Nearest Neighbor, KNN)
[机器学习与scikit-learn-18]:算法-K近邻算法KNN的原理与代码实例
机器学习实战☛k-近邻算法(K-Nearest Neighbor, KNN)