docker ElasticsearchRest风格的分布式开源搜索和分析引擎Elasticsearch初体验
Posted lomtom
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了docker ElasticsearchRest风格的分布式开源搜索和分析引擎Elasticsearch初体验相关的知识,希望对你有一定的参考价值。
概述:
Elasticsearch 是一个分布式、可扩展、实时的搜索与数据分析引擎。 它能从项目一开始就赋予你的数据以搜索、分析和探索的能力,这是通常没有预料到的。 它存在还因为原始数据如果只是躺在磁盘里面根本就毫无用处。
Elasticsearch 不仅仅只是全文搜索,我们还将介绍结构化搜索、数据分析、复杂的人类语言处理、地理位置和对象间关联关系等。 我们还将探讨为了充分利用 Elasticsearch 的水平伸缩性,应当如何建立数据模型,以及在生产环境中如何配置和监控你的集群。
Elasticsearch也使用Java开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。
不过,Elasticsearch 不仅仅是 Lucene 和全文搜索,我们还能这样去描述它:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
@
壹:安装软件
一:安装elasticsearch
1、安装
1、搜索镜像
docker search Elasticsearch
2、拉取镜像
docker pull elasticsearch:7.5.2
3、查看镜像
docker images
4、启动容器
docker run -d --name elaseticsearch -p 9200:9200 -p 9300:9300 -e ES_JAVA_POTS="-Xms256m -Xmx256m" -e "discovery.type=single-node" [镜像id]
5、访问
http://localhost:9200
{
"name": "ea92e317dcb0",
"cluster_name": "docker-cluster",
"cluster_uuid": "nN5sGE2FQuidchtltDxAhQ",
"version": {
"number": "7.5.2",
"build_flavor": "default",
"build_type": "docker",
"build_hash": "8bec50e1e0ad29dad5653712cf3bb580cd1afcdf",
"build_date": "2020-01-15T12:11:52.313576Z",
"build_snapshot": false,
"lucene_version": "8.3.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
2、问题
1、启动失败,docker内容器无故停止
原因:elasticsearch初始占用内存大,开始占用两G,而我给docker只分配了1G,所以造成内存不够从而造成启失败,如果你电脑内存够大,你可以给你的docker分配大一点的内存,内存不够的同学,你可以在创建容器时加参数-e ES_JAVA_POTS="-Xms256m -Xmx256m"
二:安装kibana
1、安装
1、拉取镜像
docker pull kibana:7.5.2
注:最好与你的elasticsearch版本一致,以免出现问题
2、创建容器
docker run -d --name kibana -p 5601:5601 [镜像id]
3、访问测试
访问地址:http://locahost:5601
在调试很久之后,终于来到我渴望来到的界面。
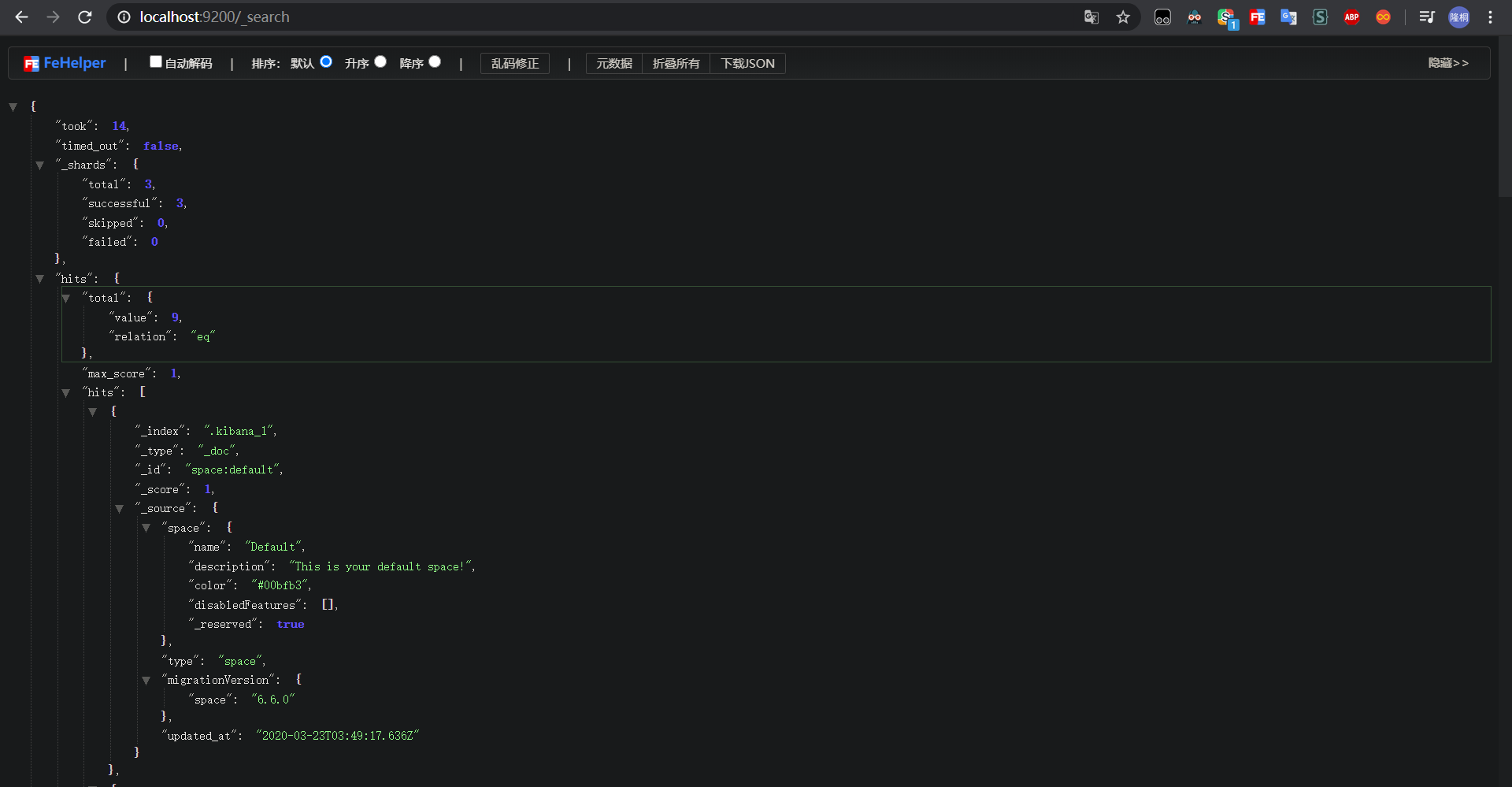
他里面有一个测试:http://localhost:9200/_search
2、问题
1、访问kibana出现问题:Kibana server is not ready yet,具体问题你需要看他的日志,使用kitematic可以查看容器的日志。
出现这个问题的可能性有很多,需要注意的是:
- 1、确认你的elasticsearch是否启动,这没什么好说的
- 2、确认你的elasticsearch版本是否与你的kibana版本是否一致,虽然我也没有测试,版本一致总归没有什么坏处。

- 3、你最好把kibana与elasticsearch两个容器之间连接起来

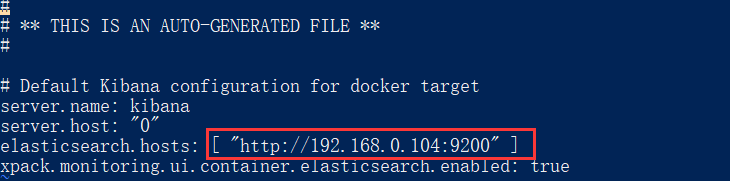
- 4、在进入容器后,你必须修改
elasticsearch.hosts参数,它里面会有默认值为http://elaseicsearch:9200,注意这里不能改为http://localhost:9200,因为这样他会映射到你的容器内部。
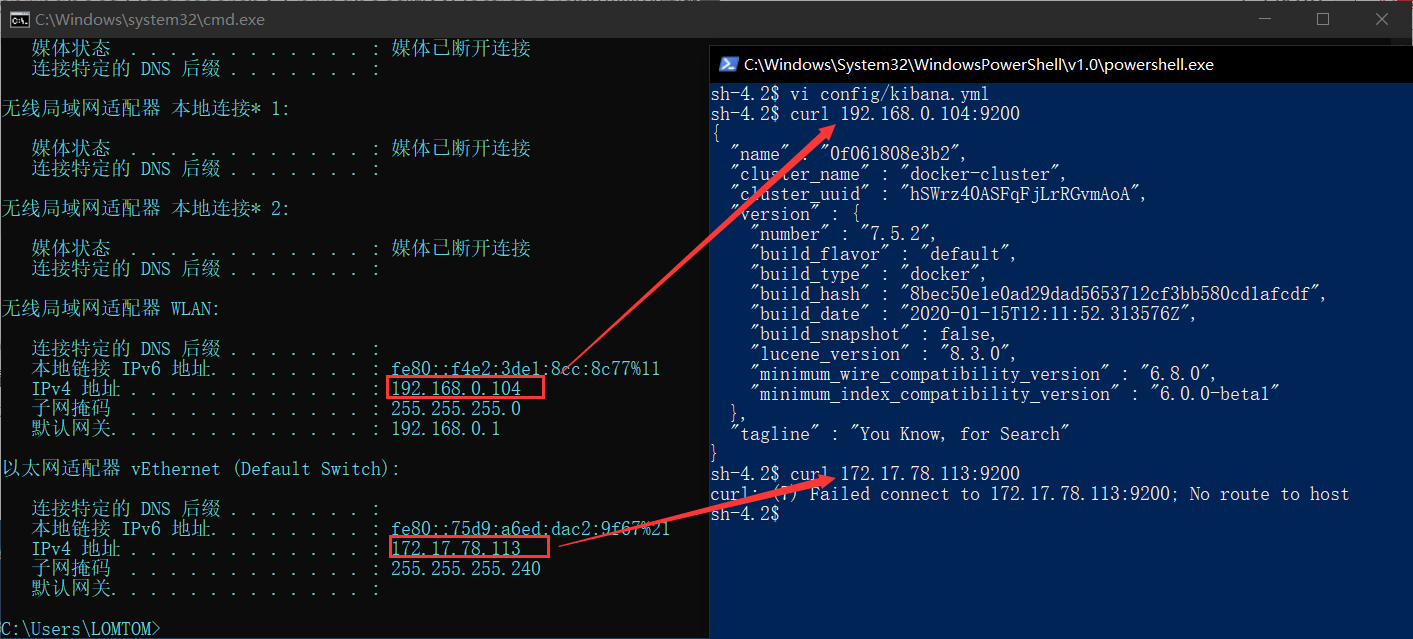
你需要在你的主机查看ip,输入ipconfig,这里会有很多ip,请注意,这里只有一个才能连接,如果你不能确认是哪一个,请在你的kibana容器内部curl一下http://ip:9200,出现elasticsearch信息的才是正确的。
贰:Elastic search初体验
数据的操作无非就是增删改查四种对吧,接下来演示怎么实现这四种方法:
一:添加数据
这时elasticsearch开发文档里的例子。
PUT /megacorp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
PUT /megacorp/employee/2
{
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}
PUT /megacorp/employee/3
{
"first_name" : "Douglas",
"last_name" : "Fir",
"age" : 35,
"about": "I like to build cabinets",
"interests": [ "forestry" ]
}
以1号员工为例:这里使用Postman工具:
我们将请求切换为PUT请求,输入Url,在请求里面加上数据,点击发送,就会看到响应,
注意,路径 /megacorp/employee/1 包含了三部分的信息:
- megacorp(索引名称)
- employee(类型名称)
- 1(特定雇员的ID)
请求体 —— JSON 文档 —— 包含了这位员工的所有详细信息,他的名字叫 John Smith ,今年 25 岁,喜欢攀岩。

二:查看数据
目前我们已经在 Elasticsearch 中存储了一些数据, 接下来就能专注于实现应用的业务需求了。第一个需求是可以检索到单个雇员的数据。
这在 Elasticsearch 中很简单。简单地执行 一个 HTTP GET 请求并指定文档的地址——索引库、类型和ID。 使用这三个信息可以返回原始的 JSON 文档:
1、查询单个数据
同样的,我们只需要将索引名、类别名、id的形式以get的请求发送,就可以实现单个数据的查询。
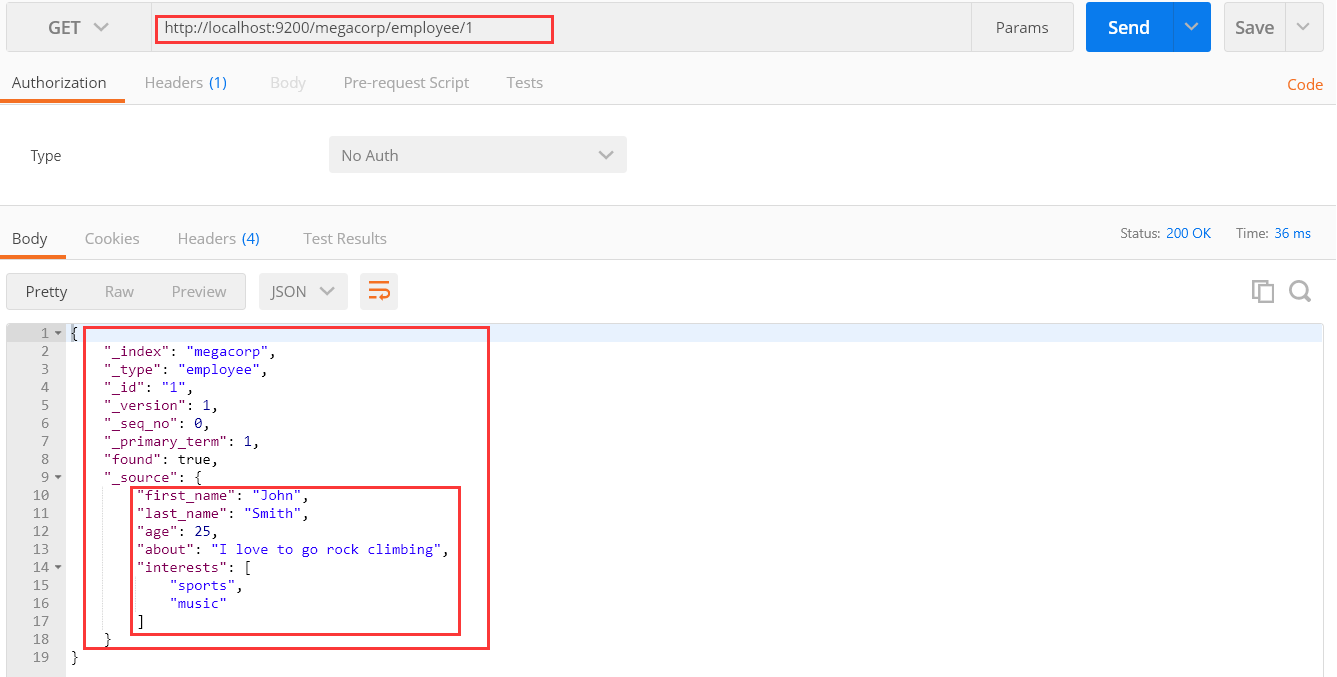
GET /megacorp/employee/1
返回结果包含了文档的一些元数据,以及 _source 属性,内容是 John Smith 雇员的原始 JSON 文档
2、查询所有的数据
一个 GET 是相当简单的,可以直接得到指定的文档。 现在尝试点儿稍微高级的功能,比如一个简单的搜索!
第一个尝试的几乎是最简单的搜索了。我们使用下列请求来搜索所有雇员:
GET /megacorp/employee/_search
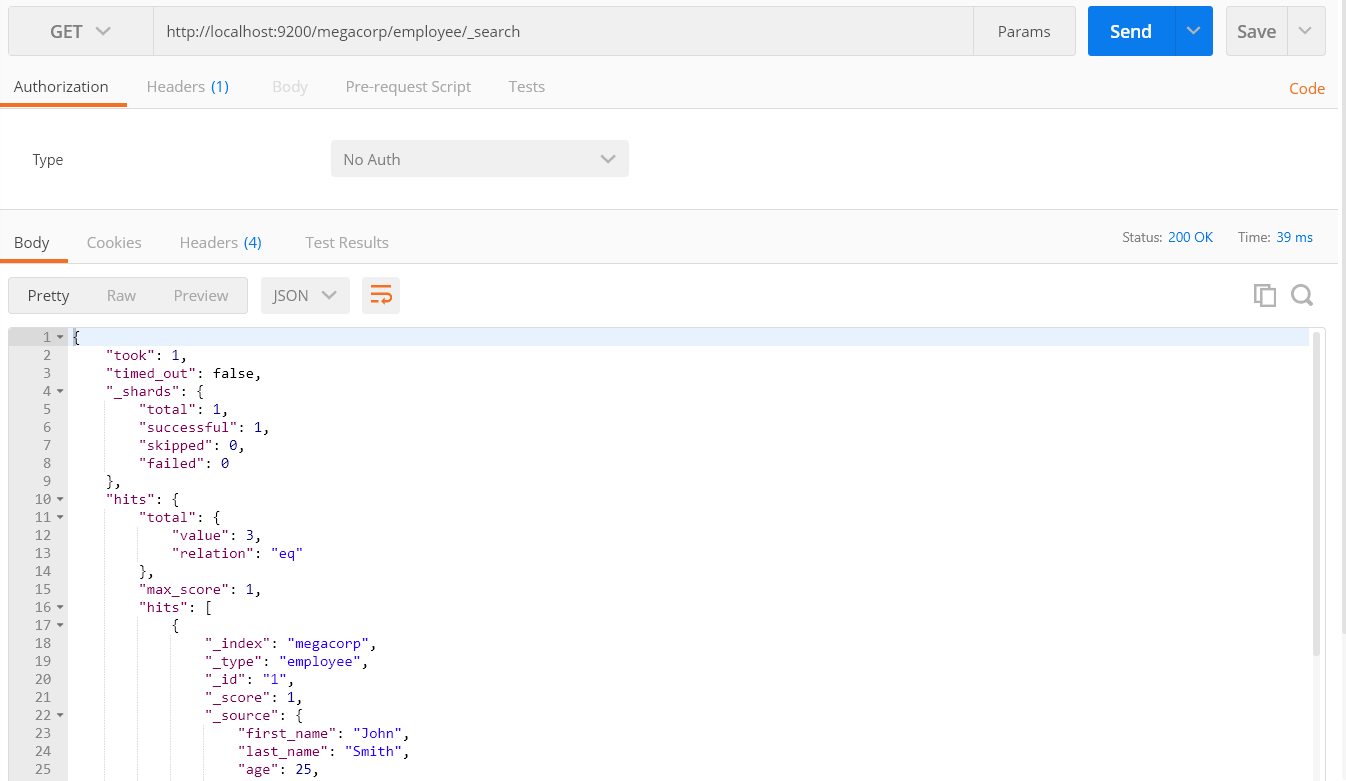
可以看到,我们仍然使用索引库 megacorp 以及类型 employee,但与指定一个文档 ID 不同,这次使用 _search 。返回结果包括了所有三个文档,放在数组 hits 中。一个搜索默认返回十条结果。
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 1,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 1,
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "3",
"_score": 1,
"_source": {
"first_name": "Douglas",
"last_name": "Fir",
"age": 35,
"about": "I like to build cabinets",
"interests": [
"forestry"
]
}
}
]
}
}
3、按条件查询
①、get
尝试下搜索姓氏为 Smith 的雇员。、这个方法一般涉及到一个 查询字符串 (query-string) 搜索,因为我们可以通过一个URL参数来传递查询信息给搜索接口:
GET /megacorp/employee/_search?q=last_name:Smith
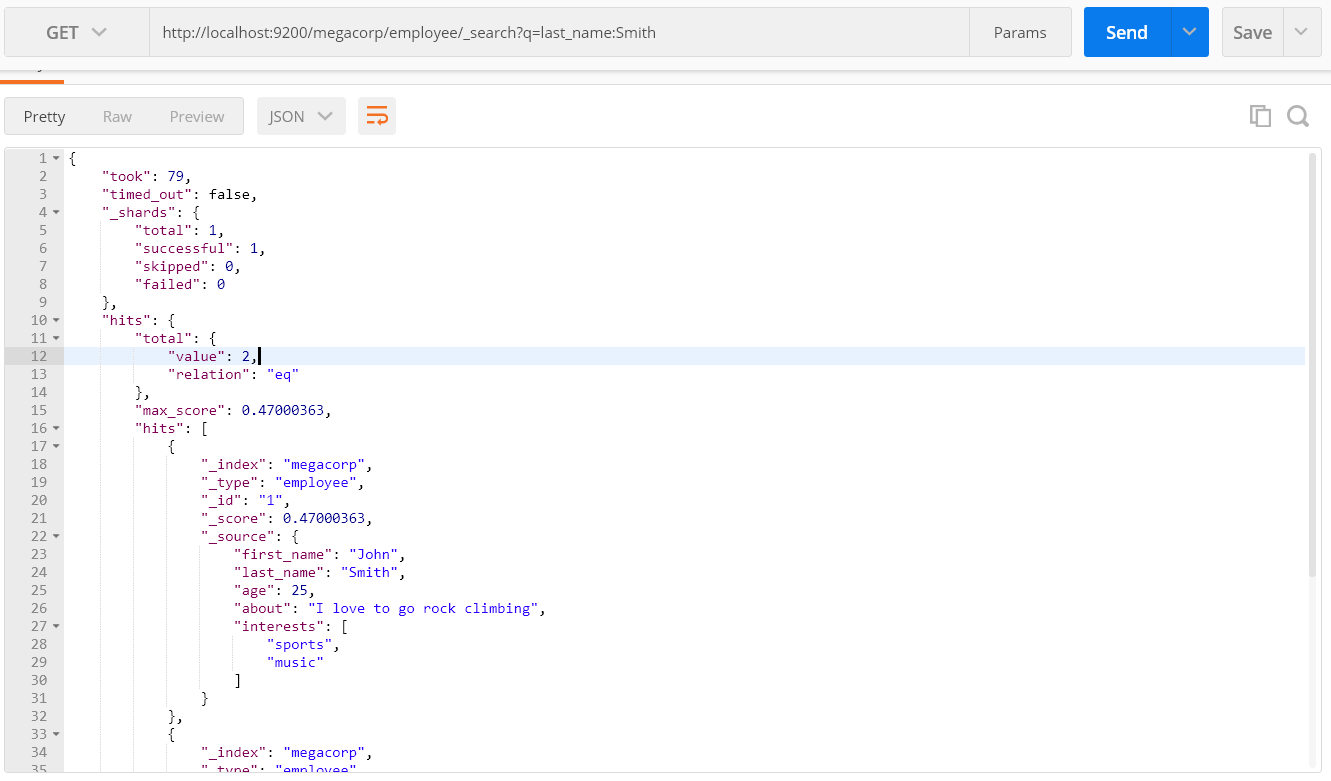
可以看到我们将查询本身赋值给参数 q= 。返回结果给出了所有的 Smith,一共两条。
{
"took": 79,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.47000363,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 0.47000363,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 0.47000363,
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
}
]
}
}
②:post请求
官方文档介绍这是使用查询表达式搜索。
Query-string 搜索通过命令非常方便地进行临时性的即席搜索 ,但它有自身的局限性(参见 轻量 搜索 )。Elasticsearch 提供一个丰富灵活的查询语言叫做 查询表达式 , 它支持构建更加复杂和健壮的查询。
领域特定语言 (DSL), 使用 JSON 构造了一个请求。我们可以像这样重写之前的查询所有名为 Smith 的搜索 :
POST /megacorp/employee/_search
{
"query" : {
"match" : {
"last_name" : "Smith"
}
}
}
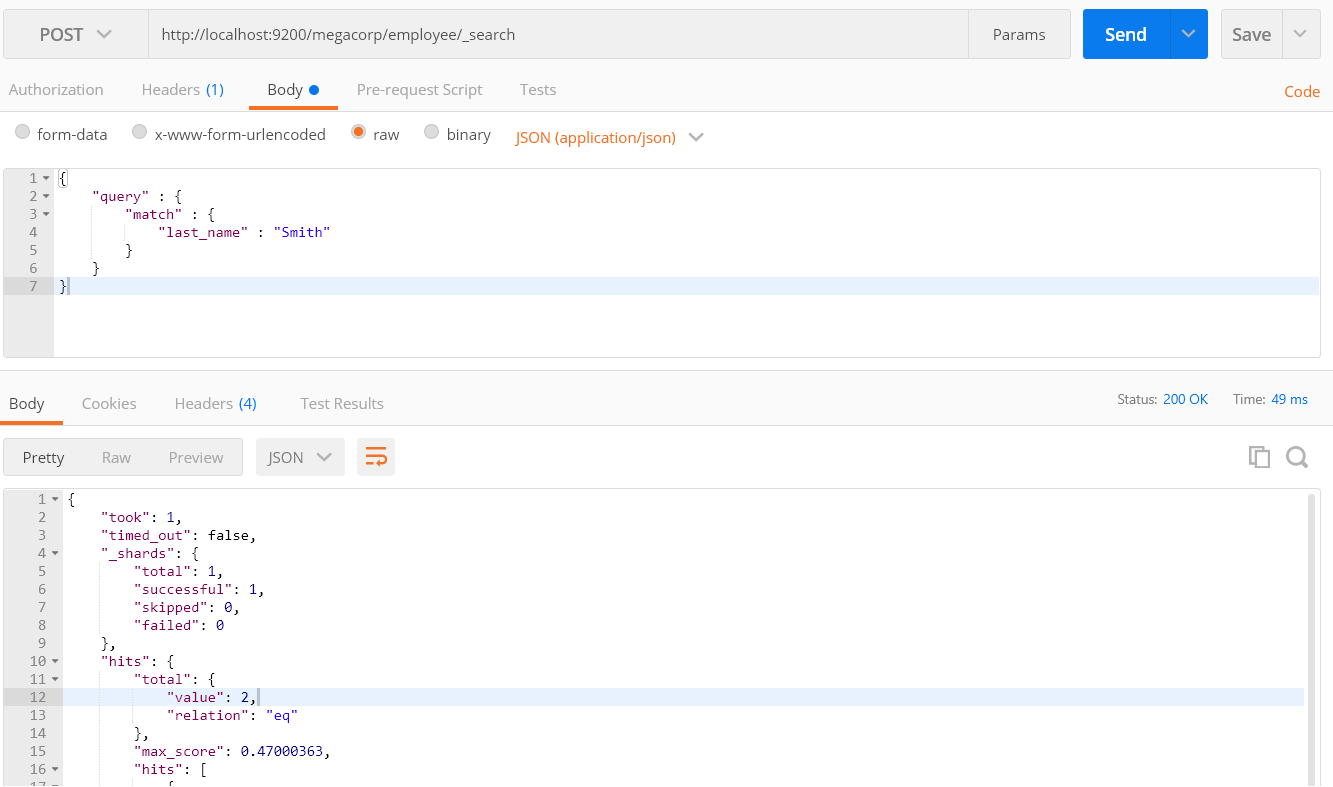
官方文档给出的是get请求,我实在是不知道参数加在哪里,加在header里,没有任何效果,于是我改成了POST请求,请求成功,值得注意的是只有在有条件的时候才能查询成功。
其中与get请求的不同是:不再使用 query-string 参数,而是一个请求体替代。这个请求使用 JSON 构造,并使用了一个 match 查询(属于查询类型之一)
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.47000363,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 0.47000363,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 0.47000363,
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
}
]
}
}
4、查看数据是否存在
相对于其他集中请求,这时一种比较少见的请求方式,如果需要查看数据是否存在,将请求方式改为head即可。
HEAD /megacorp/employee/1
发送请求后,你也许会疑问,咦,他也没有返回信息啊,那我怎么知道结果呢。别急,听我慢慢道来。
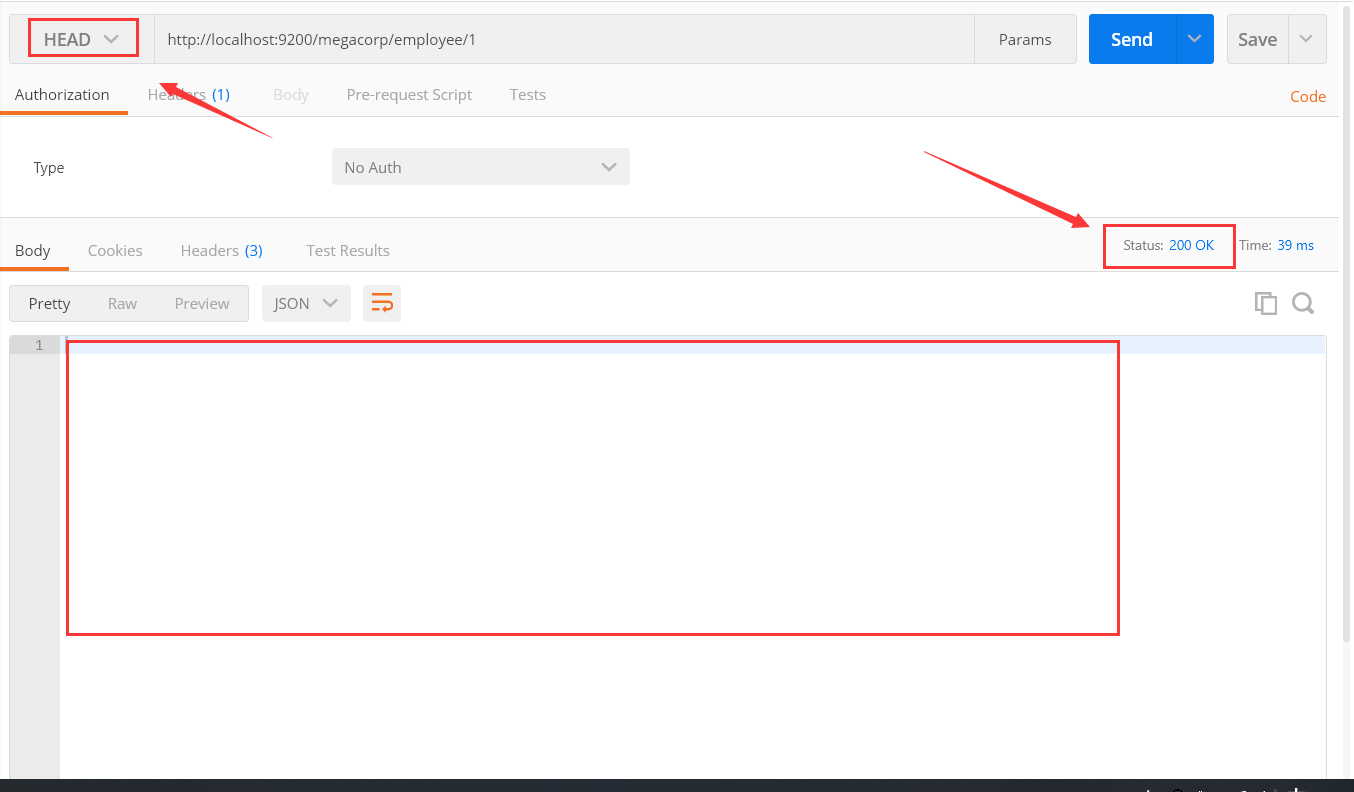
根据图,我们可以看出,他的确没有返回结果,但是可以注意到,再右上角他会有一个状态码,当有这个信息时,他的状态码就是200,没有就返回404表示找不到。
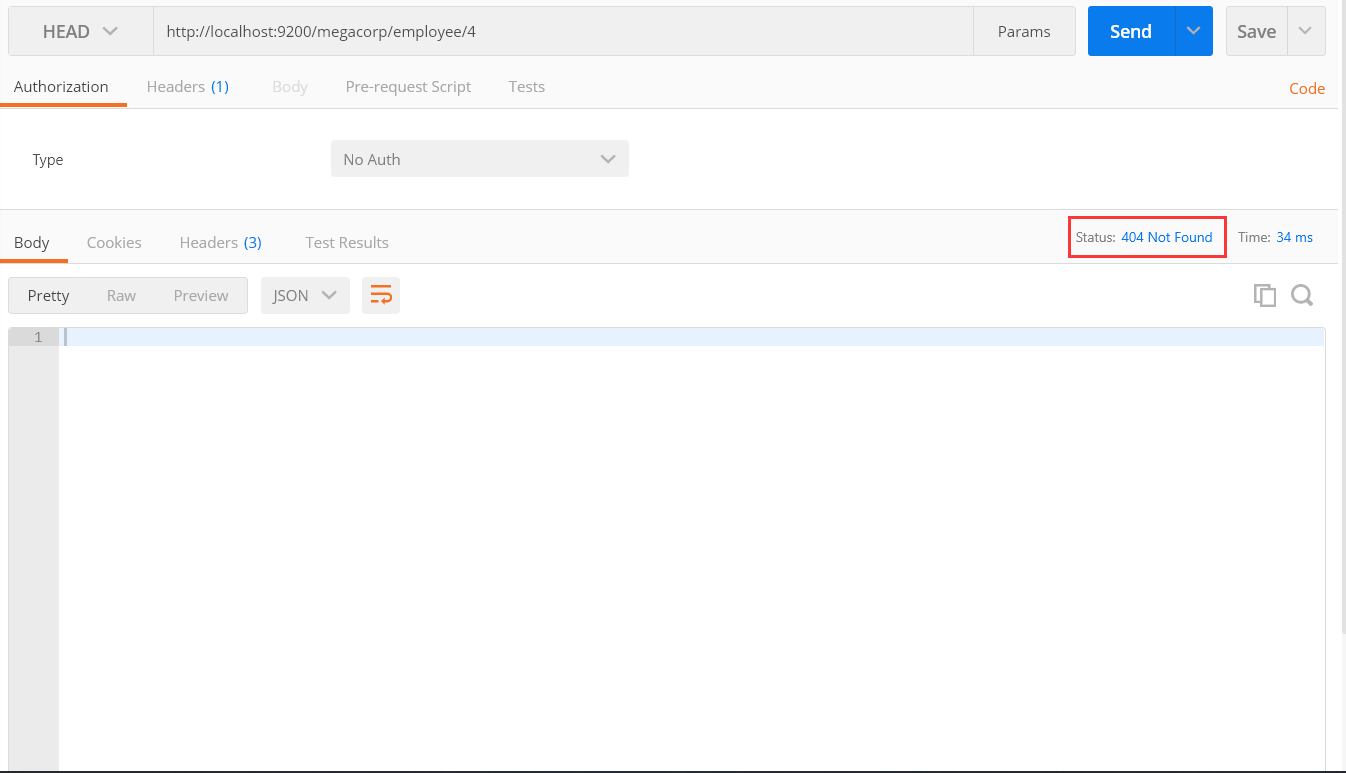
三、修改数据
我们使用了GET和POST查询数据,使用PUT新增数据,根据官方给出的是修改数据还是用PUT,如果存在数据他就会更新数据,这样的模式确实与我们常见的请求使用方法略有不同。
PUT /megacorp/employee/1
{
"first_name" : "唐",
"last_name" : "菜鸡",
"age" : 21,
"about" : "I love to go rock climbing",
"interests": [ "movie", "music" ]
}
发送该请求后,返回参数
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 3
}
我们对比可以发现,主要有两处不同,看图你就会说,呀不对呀,明明有四处,那是因为之前插入第一条的时候还只有一条参数,现在有三条了,不许抬杠,不许抬杠,不许抬杠。
不同:他的版本加一,返回状态为created变为updated。
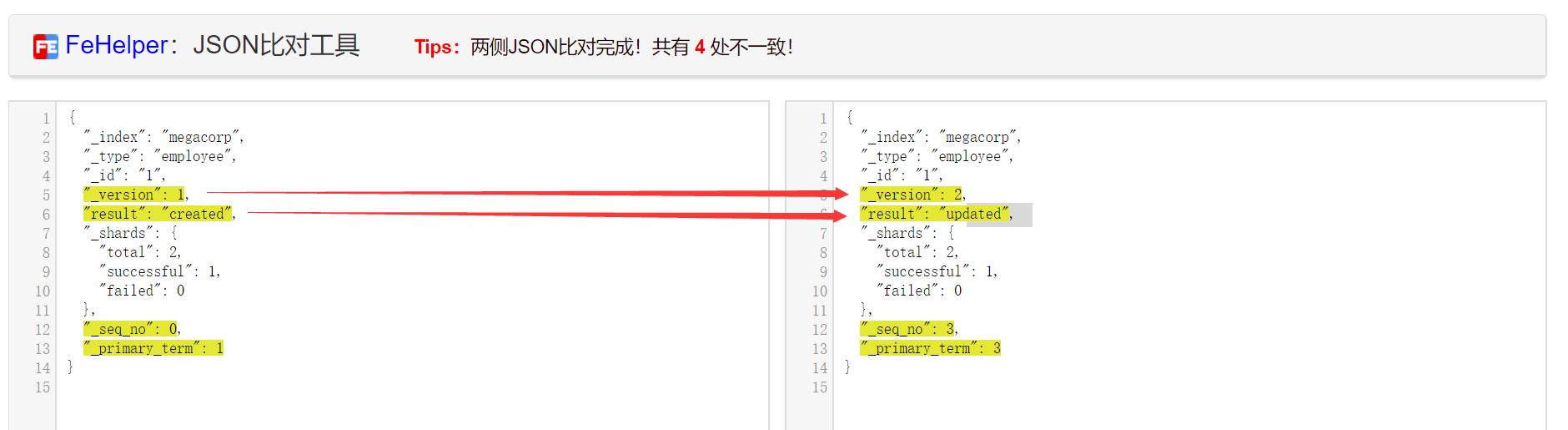
我们再查询一次就会发现他的信息已经发现改变,这就是修改。
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_version": 2,
"_seq_no": 3,
"_primary_term": 3,
"found": true,
"_source": {
"first_name": "唐",
"last_name": "菜鸡",
"age": 21,
"about": "I love to go rock climbing",
"interests": [
"movie",
"music"
]
}
}
四:删除数据
根据前面,不用想我们也知道删除数据用的就是delete请求。
DELETE /megacorp/employee/2
我们删除二号员工,返回如下信息,result变为deleted。
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 3
}
作者有话
当然,elasticsearch的功能不仅仅是如此,这些只是他的基本功能之一,更多请看他的开发文档。 传送门
以上是关于docker ElasticsearchRest风格的分布式开源搜索和分析引擎Elasticsearch初体验的主要内容,如果未能解决你的问题,请参考以下文章