集群规模计算
Posted yangxusun9
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了集群规模计算相关的知识,希望对你有一定的参考价值。
一、数据规模

二、集群处理数据的吞吐量
2.1 hdfs的读写测试
Hadoop自带一个测试用的jar包,可以运行它来得知集群处理数据的性能如何
hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
结果如下
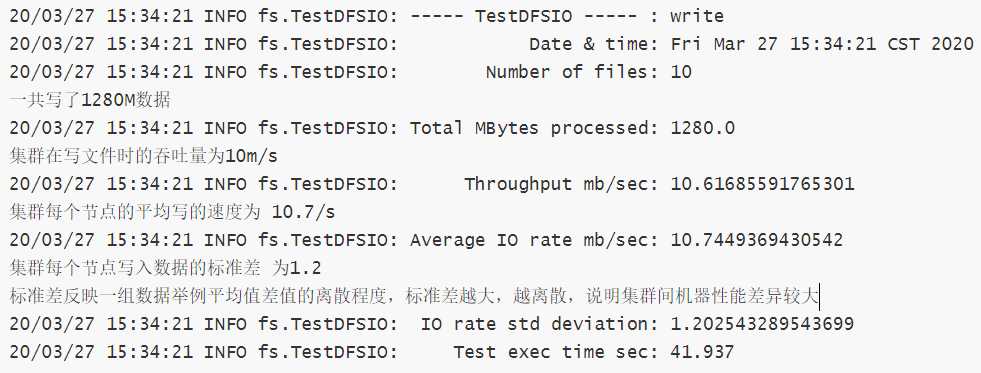
吞吐量大约为 10m/s ,一个小时大概能写36g左右的数据,能够满足项目需求
优化:
可以尝试从硬件方面升级(磁盘IO,网络IO)
集群扩容
2.2Kafka测试
2.2.1生产者压力测试
bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput -1 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
说明:
record-size是一条信息有多大,单位是字节。
num-records是总共发送多少条信息。
throughput 是每秒多少条信息,设成-1,表示不限流,可测出生产者最大吞吐量。
测试结果示例
100000 records sent, 59665.871122 records/sec (5.69 MB/sec), 463.76 ms avg latency, 626.00 ms max latency, 519 ms 50th, 608 ms 95th, 622 ms 99th, 626 ms 99.9th.
重点查看 吞吐量 5.69m/s 延迟 463.76 ms avg latency
优化
如果生产能力不足,可以对主题添加分区,或扩容集群,或设置kafka同时挂载多个磁盘目录,提高磁盘的IO能力!
2.2.2消费者压力测试
bin/kafka-consumer-perf-test.sh --zookeeper hadoop102:2181 --topic test --fetch-size 10000 --messages 10000000 --threads 1
参数说明:
--zookeeper 指定zookeeper的链接信息
--topic 指定topic的名称
--fetch-size 指定每次fetch的数据的大小
--messages 总共要消费的消息个数
重点查看:
MB.sec: 一秒消费多少M数据
nMsg.sec: 一秒消费多少数据
优化: 提高消费者的线程数;前提是一个主题有多个可用的分区!
在消费者端配置一些参数,例如offset的异步提交等!
以上是关于集群规模计算的主要内容,如果未能解决你的问题,请参考以下文章