Language L语言
Posted cutepota
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Language L语言相关的知识,希望对你有一定的参考价值。
Description
标点符号的出现晚于文字的出现,所以以前的语言都是没有标点的。现在你要处理的就是一段没有标点的文章。
一段文章T是由若干小写字母构成。一个单词W也是由若干小写字母构成。一个字典D是若干个单词的集合。
我们称一段文章T在某个字典D下是可以被理解的,是指如果文章T可以被分成若干部分,且每一个部分都是字典D中的单词。
例如字典D中包括单词{‘is’, ‘name’, ‘what’, ‘your’},则文章‘whatisyourname’是在字典D下可以被理解的
因为它可以分成4个单词:‘what’, ‘is’, ‘your’, ‘name’,且每个单词都属于字典D,而文章‘whatisyouname’
在字典D下不能被理解,但可以在字典D’=D+{‘you’}下被理解。这段文章的一个前缀‘whatis’,也可以在字典D下被理解
而且是在字典D下能够被理解的最长的前缀。
给定一个字典D,你的程序需要判断若干段文章在字典D下是否能够被理解。
并给出其在字典D下能够被理解的最长前缀的位置。
Input
输入文件第一行是两个正整数n和m,表示字典D中有n个单词,且有m段文章需要被处理。
之后的n行每行描述一个单词,再之后的m行每行描述一段文章。
其中1<=n, m<=20,每个单词长度不超过10,每段文章长度不超过1M。
Output
对于输入的每一段文章,你需要输出这段文章在字典D可以被理解的最长前缀的位置。
Sample Input
4 3
is
name
what
your
whatisyourname
whatisyouname
whaisyourname
Sample Output
14
6
0
//整段文章’whatisyourname’都能被理解
前缀’whatis’能够被理解
没有任何前缀能够被理解
sol:先将字典里的单词放进Trie树,标记下单词的结束位置。
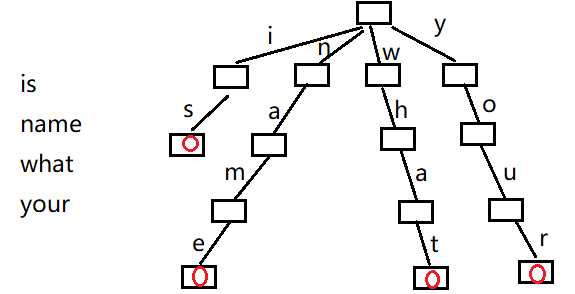
对于每一个询问,我们需要在Trie里找到可被理解的最长前缀。
定义f[i]——表示对于前i位,我们可以在Trie里找到,接下来,我们时要检查[i+1,len]是否可被找到。注意我们要使得i的值尽量大。设置边界f[0]=true,代表第0位可以找到。
如询问"whatisyourname",f[0]=1,我们检查f[1..14]是否在Trie中,先找到w-h-a-t,t为单词结束,此时给f[4]打上标记true,接着检查f[5,14],找到i-s,f[6]=1,继续检查f[7,14],找到y-o-u-r,f[10]=1,接着检查f[11,14],找到n-a-m-e,f[14]=1。因此该询问在字典中可被理解的最长前缀的位置为14.
小结:对于某个询问,我们枚举开始位置到结束位置,若f[i]=1,则检查f[i+1,len]是否为真,逐一去找出最长前缀。
再看一个样例:
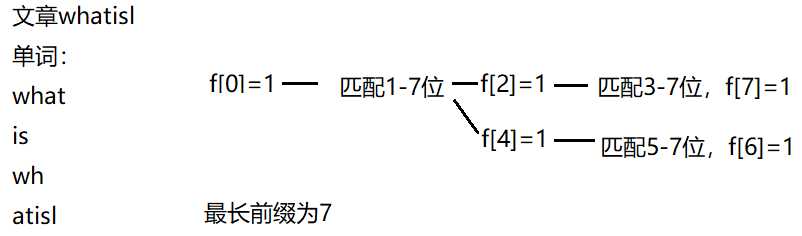
代码如下:
1 #include<cstdio> 2 #include<cstring> 3 #include<iostream> 4 #define re register 5 #define maxn 1000005 6 char S[maxn]; 7 int son[505][27],flag[505]; 8 char T[11]; 9 int cnt; 10 bool f[maxn]; 11 inline int read() 12 { 13 char c=getchar(); 14 int x=0; 15 while(c<‘0‘||c>‘9‘) c=getchar(); 16 while(c>=‘0‘&&c<=‘9‘) 17 x=(x<<3)+(x<<1)+c-48,c=getchar(); 18 return x; 19 } 20 int n,m; 21 inline void ins() 22 { 23 int len=strlen(T+1); 24 int now=0; 25 for(re int i=1;i<=len;i++) 26 { 27 if(!son[now][T[i]-‘a‘]) 28 son[now][T[i]-‘a‘]=++cnt; 29 now=son[now][T[i]-‘a‘]; 30 } 31 flag[now]=1; 32 } 33 inline void check(int x,int len) 34 { 35 int now=0; 36 for(re int i=x;i<=len;i++) 37 { 38 if(!son[now][S[i]-‘a‘]) 39 return; 40 now=son[now][S[i]-‘a‘]; 41 42 if(flag[now]) 43 //如果这一位是某个单词结束位置,则第I位可以匹配到 44 f[i]=1; 45 } 46 } 47 int main() 48 { 49 n=read();m=read(); 50 for(re int i=1;i<=n;i++) 51 { 52 scanf("%s",T+1); 53 ins(); 54 } 55 for(re int t=1;t<=m;t++) 56 { 57 scanf("%s",S+1); 58 memset(f,0,sizeof(f)); 59 f[0]=1; 60 int len=strlen(S+1); 61 int ans=0; 62 for(re int i=0;i<=len;i++) 63 //枚举开始位置 64 { 65 if(!f[i]) 66 continue; 67 ans=i;//前i位是可以匹配到的 68 check(i+1,len);//从第i+1位到第Len位到TRIE上跑一下 69 } 70 if(!ans) puts("-1"); 71 else printf("%d",ans),putchar(10); 72 } 73 return 0; 74 }
以上是关于Language L语言的主要内容,如果未能解决你的问题,请参考以下文章