HTTPTSlHTTPS的工作原理详解
Posted -one
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HTTPTSlHTTPS的工作原理详解相关的知识,希望对你有一定的参考价值。
HTTP的工作原理
HTTP协议是什么?
HTTP我们称之为超文本传输协议,是分布式、协作式、超媒体信息系统的应用程序协议。HTTP 是互联网数据通信的基础,其中超文本文档包括指向用户可以轻松访问的其他资源的超链接。例如通过单击鼠标或在 Web 浏览器中输入网络地址URL或者点击浏览器的内容发起一个简单的请求响应协议,服务器收到请求后提供html文件和其他内容等资源或代表客户端执行其他功能,向客户端返回响应消息,响应包含有关请求的完成状态信息,并且可能还包含其消息正文中请求的内容。响应的消息内容则具有一个类似MIME的格式。
web浏览器的URL在HTTP中扮演的有事什么角色呢?
URI:又称之统一资源的标识符;是一个字符字符串,用于明确标识互联网上的特定资源。简单的来说就是身份证,用来说明人的家庭地址、姓名,以此来准确定位并查找。所以在互联网中的URL指定对资源执行或获取表示方式的,即指定其主访问机制和网络位置,以此来精确的返回web浏览器想要的资源。它的格式如下:

总结如下:
URL的组成:<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag>
格式说明
- scheme :标明访问服务器以获取资源时要使用哪种协议
- user :用户,某些方案访问资源时需要的用户名
- password :密码,用户对应的密码,中间用:分隔
- Host :主机,资源宿主服务器的主机名或IP地址
- port :端口,资源宿主服务器正在监听的端口号,很多方案有默认端口号
- path :路径,服务器资源的本地名,由一个/将其与前面的URL组件分隔
- params :参数,指定输入的参数,参数为名/值对,多个参数,用;分隔
- query :查询,传递参数给程序,如数据库,用?分隔,多个查询用&分隔
- frag :片段,一小片或一部分资源的名字,此组件在客户端使用,用#分隔
web浏览器发起的HTTP协议的请求报文、以及收到的响应报文
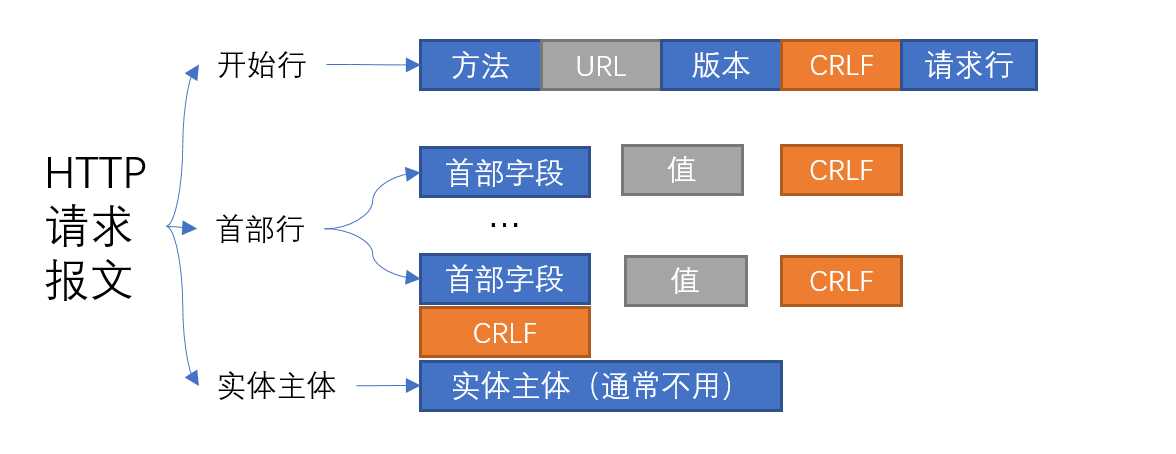
#请求报文格式
<method> <request-URL> <version>
<headers>
<entity-body>
#请求报文范例
GET / HTTP/1.1
Accept: */*
Accept-Encoding: gzip, deflate
Connection: keep-alive
Host: https://www.cnblogs.com/-one/
User-Agent: HTTPie/0.9.4
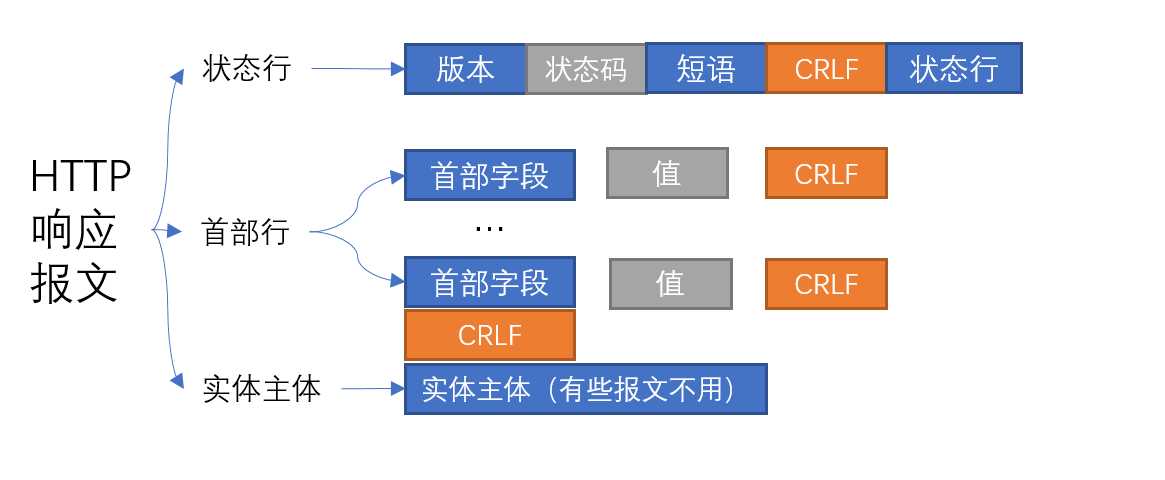
#响应报文格式
<version> <status> <reason-phrase>
<headers>
<entity-body>
#响应报文范例
HTTP/1.1 200 OK
Cache-Control: max-age=3, must-revalidate
Connection: keep-alive
Content-Encoding: gzip
Content-Type: text/html; charset=UTF-8
Date: Thu, 07 Nov 2019 03:44:14 GMT
Server: Tengine
Transfer-Encoding: chunked
Vary: Accept-Encoding
Vary: Accept-Encoding, Cookie
HTTP报文详解
headers:首部字段头
- 通用首部:请求报文和响应报文两方都会使用的首部
- 请求首部:从客户端向服务器端发送请求报文时使用的首部。补充了请求的附加内容、客户端信息、请求内容相关优先级等信息
- 响应首部:从服务器端向客户端返回响应报文时使用的首部。补充了响应的附加内容,也会要求客户端附加额外的内容信息
- 实体首部:针对请求报文和响应报文的实体部分使用的首部。补充了资源内容更新时间等与实体有关的的信息
- 扩展首部:
通用首部:
Date: 报文的创建时间
Connection:连接状态,如keep-alive, close
Via:显示报文经过的中间节点(代理,网关)
Cache-Control:控制缓存,如缓存时长
MIME-Version:发送端使用的MIME版本
Warning:错误通知
请求首部:
Accept:通知服务器自己可接受的媒体类型
Accept-Charset: 客户端可接受的字符集
Accept-Encoding:客户端可接受编码格式,如gzip
Accept-Language:客户端可接受的语言
Client-IP: 请求的客户端IP
Host: 请求的服务器名称和端口号
Referer:跳转至当前URI的前一个URL
User-Agent:客户端代理,浏览器版本
条件式请求首部:
Expect:允许客户端列出某请求所要求的服务器行为
If-Modified-Since:自从指定的时间之后,请求的资源是否发生过修改
If-Unmodified-Since:与上面相反
If-None-Match:本地缓存中存储的文档的ETag标签是否与服务器文档的Etag不匹配
If-Match:与上面相反
安全请求首部:
Authorization:向服务器发送认证信息,如账号和密码
Cookie: 客户端向服务器发送cookie
代理请求首部:
Proxy-Authorization: 向代理服务器认证
响应首部:
信息性:
Age:从最初创建开始,响应持续时长
Server:服务器程序软件名称和版本
协商首部:某资源有多种表示方法时使用
Accept-Ranges:服务器可接受的请求范围类型
Vary:服务器查看的其它首部列表
安全响应首部:
Set-Cookie:向客户端设置cookie
WWW-Authenticate:来自服务器对客户端的质询列表
实体首部:
Allow: 列出对此资源实体可使用的请求方法
Location:告诉客户端真正的实体位于何处
Content-Encoding:对主体执行的编码
Content-Language:理解主体时最适合的语言
Content-Length: 主体的长度
Content-Location: 实体真正所处位置
Content-Type:主体的对象类型,如text
缓存相关:
ETag:实体的扩展标签
Expires:实体的过期时间
Last-Modified:最后一次修改的时间
Method:方法:标明客户端希望服务器对资源执行的动作,包括以下:
- GET :从服务器获取一个资源(常用)
- HEAD :只从服务器获取文档的响应首部
- POST :向服务器输入数据,通常会再由网关程序继续处理(常用)
- PUT :将请求的主体部分存储在服务器中,如上传文件
- DELETE :请求删除服务器上指定的文档
- TRACE :追踪请求到达服务器中间经过的代理服务器
- OPTIONS :请求服务器返回对指定资源支持使用的请求方法
- CONNECT :建立一个到由目标资源标识的服务器的隧道
- PATCH :用于对资源应用部分修改
version:版本
目前的HTTP的版本的多为HTTP/1.1、HTTP/2.0,老版本HTTP/0.9、HTTP/1.0较为少见
reason-phrase:短语
状态码所标记的状态的简要描述
响应报文的状态码
- 1xx:100-101 信息提示
- 2xx:200-206 成功
- 3xx:300-307 重定向
- 4xx:400-415 错误类信息,客户端错误
- 5xx:500-505 错误类信息,服务器端错误
http协议常用的状态码
200: 成功,请求数据通过响应报文的entity-body部分发送;OK
301: 请求的URL指向的资源已经被删除;但在响应报文中通过首部Location指明了资源现在所处的新位置;Moved Permanently
302: 响应报文Location指明资源临时新位置 Moved Temporarily
304: 客户端发出了条件式请求,但服务器上的资源未曾发生改变,则通过响应此响应状态码通知客户端;Not Modified
401: 需要输入账号和密码认证方能访问资源;Unauthorized
403: 请求被禁止;Forbidden
404: 服务器无法找到客户端请求的资源;Not Found
500: 服务器内部错误;Internal Server Error
502: 代理服务器从后端服务器收到了一条伪响应,如无法连接到网关;Bad Gateway
503: 服务不可用,临时服务器维护或过载,服务器无法处理请求
504: 网关超时
更为详细的状态码说明请参考:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status
entity-body:实体
请求时附加的数据或响应时附加的数据,例如:登录网站时的用户名和密码,博客的上传文章,论坛上的发言等。
web浏览器利用HTTP访问的全过程
0、客户端将浏览器的URL地址解析成远程服务器的IP地址(DNS解析请参考上一章:https://www.cnblogs.com/-one/p/12595824.html)
1、客户端服务器建立基于socket的连接:服务器接收或拒绝连接请求
2、服务器接收请求:接收客户端请求报文中对某资源的一次请求的过程
3、处理请求:服务器对请求报文进行解析,并获取请求的资源及请求方法等相关信息,根据方法,资源,首部和可选的主体部分对请求进行处理
常用请求Method: GET、POST、HEAD、PUT、DELETE、TRACE、OPTIONS
4、访问资源:服务器获取请求报文中请求的资源web服务器,即存放了web资源的服务器,负责向请求者提供对方请求的静态资源,或动态运行后生成的资源
5、构建响应报文:一旦Web服务器识别除了资源,就执行请求方法中描述的动作,并返回响应报文。响应报文中 包含有响应状态码、响应首部,如果生成了响应主体的话,还包括响应主体
- 响应实体:如果事务处理产生了响应主体,就将内容放在响应报文中回送过去。响应报文中通常包括:
- 描述了响应主体MIME类型的Content-Type首部
- 描述了响应主体长度的Content-Length
- 实际报文的主体内容
- URL重定向:web服务构建的响应并非客户端请求的资源,而是资源另外一个访问路径
- MIME类型: Web服务器要负责确定响应主体的MIME类型。多种配置服务器的方法可将MIME类型与资源管理起来
- 魔法分类:Apache web服务器可以扫描每个资源的内容,并将其与一个已知模式表(被称为魔法文件)进行匹配,以决定每个文件的MIME类型。这样做可能比较慢,但很方便,尤其是文件没有标准扩展名时
- 显式分类:可以对Web服务器进行配置,使其不考虑文件的扩展名或内容,强制特定文件或目录内容拥有某个MIME类型
- 类型协商: 有些Web服务器经过配置,可以以多种文档格式来存储资源。在这种情况下,可以配置Web服务器,使其可以通过与用户的协商来决定使用哪种格式(及相关的MIME类型)"最好"
6、发送响应报文:Web服务器通过连接发送数据时也会面临与接收数据一样的问题。服务器可能有很多条到各个客户端的连接,有些是空闲的,有些在向服务器发送数据,还有一些在向客户端回送响应数据。服务器要记录连接的状态,还要特别注意对持久连接的处理。对非持久连接而言,服务器应该在发送了整条报文之后,关闭自己这一端的连接。对持久连接来说,连接可能仍保持打开状态,在这种情况下,服务器要正确地计算Content-Length首部,不然客户端就无法知道响应什么时候结束
7、记录日志
最后,当事务结束时,Web服务器会在日志文件中添加一个条目,来描述已执行的事务
以上是关于HTTPTSlHTTPS的工作原理详解的主要内容,如果未能解决你的问题,请参考以下文章