NLP知识点汇总
Posted dhname
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP知识点汇总相关的知识,希望对你有一定的参考价值。
开篇:
从事NLP方向的工作也有一年了,前前后后也学到了很多东西,但是就是没有整理过,现在从原理和应用的方面将所有知识总结方便复习管理。
一、word2vec
word2vec可以说得上是NLP的一个里程碑。将每个单词离散表示,既解决了one-hot的巨大维度,也解决了one-hot的部分语义问题。论文只是说明了有cbow和skim两个原理,分别对应着窗口大小内,环境词对中间词的预测与中间词对环境词的预测。算法角度说明的比较少,想从论文彻底了解比较困难。现有一位大神研究gensim的word2vec源码,从数学原理,有一篇博客解释的很好。现转载如下:
转载: https://www.cnblogs.com/peghoty/p/3857839.html



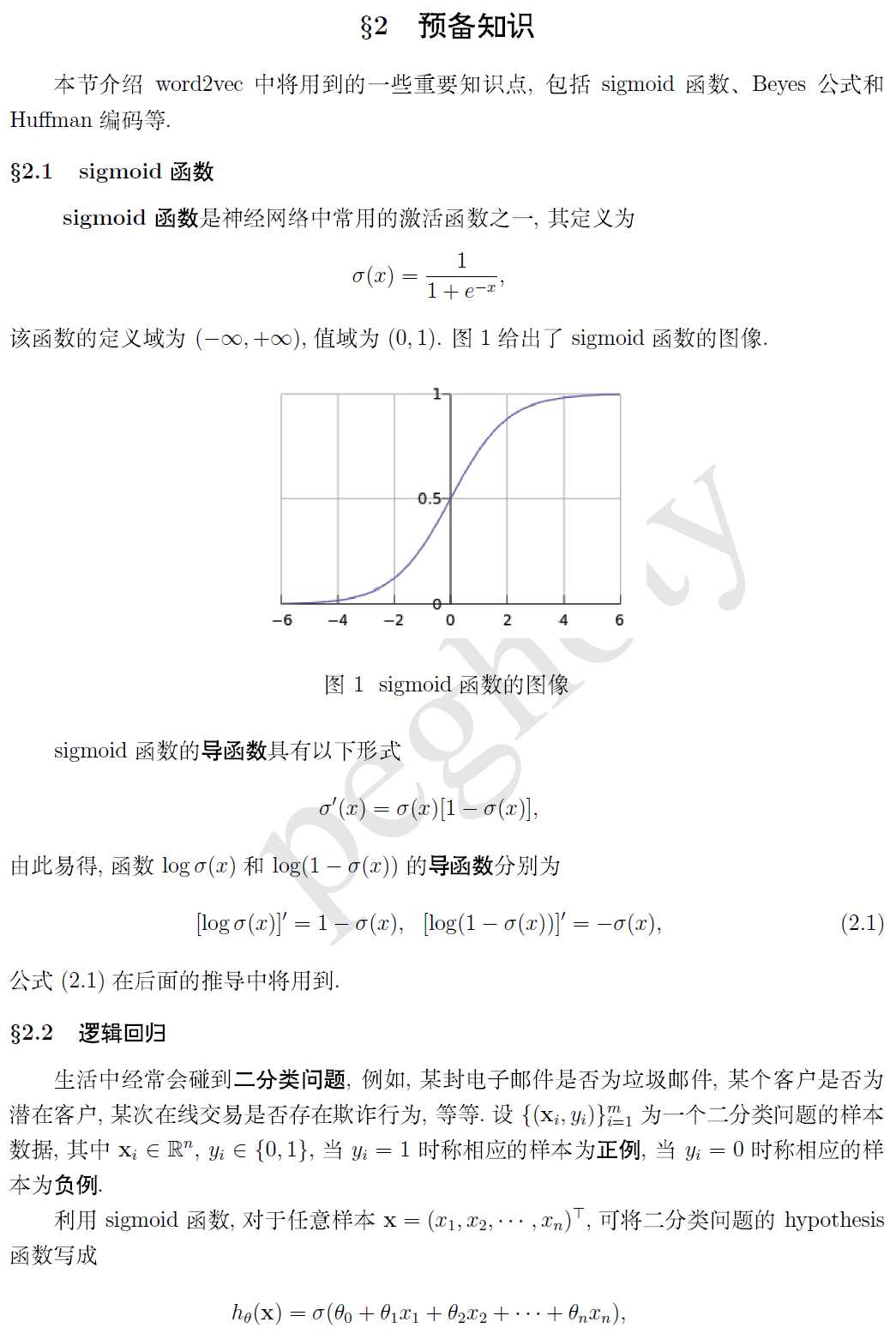


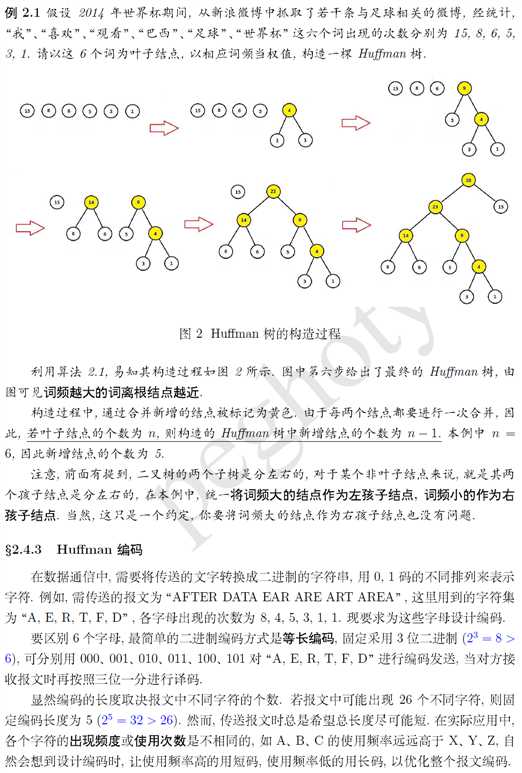
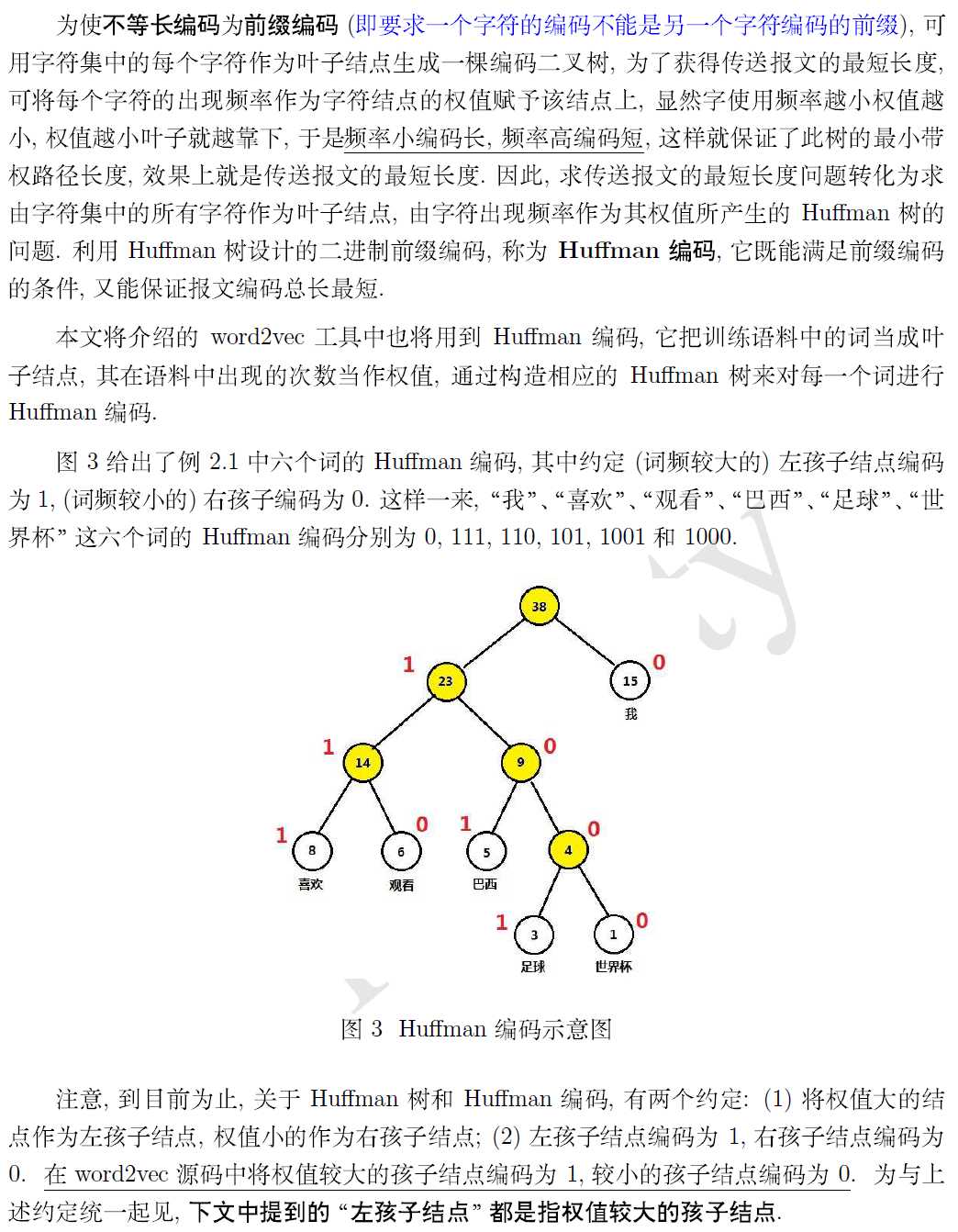








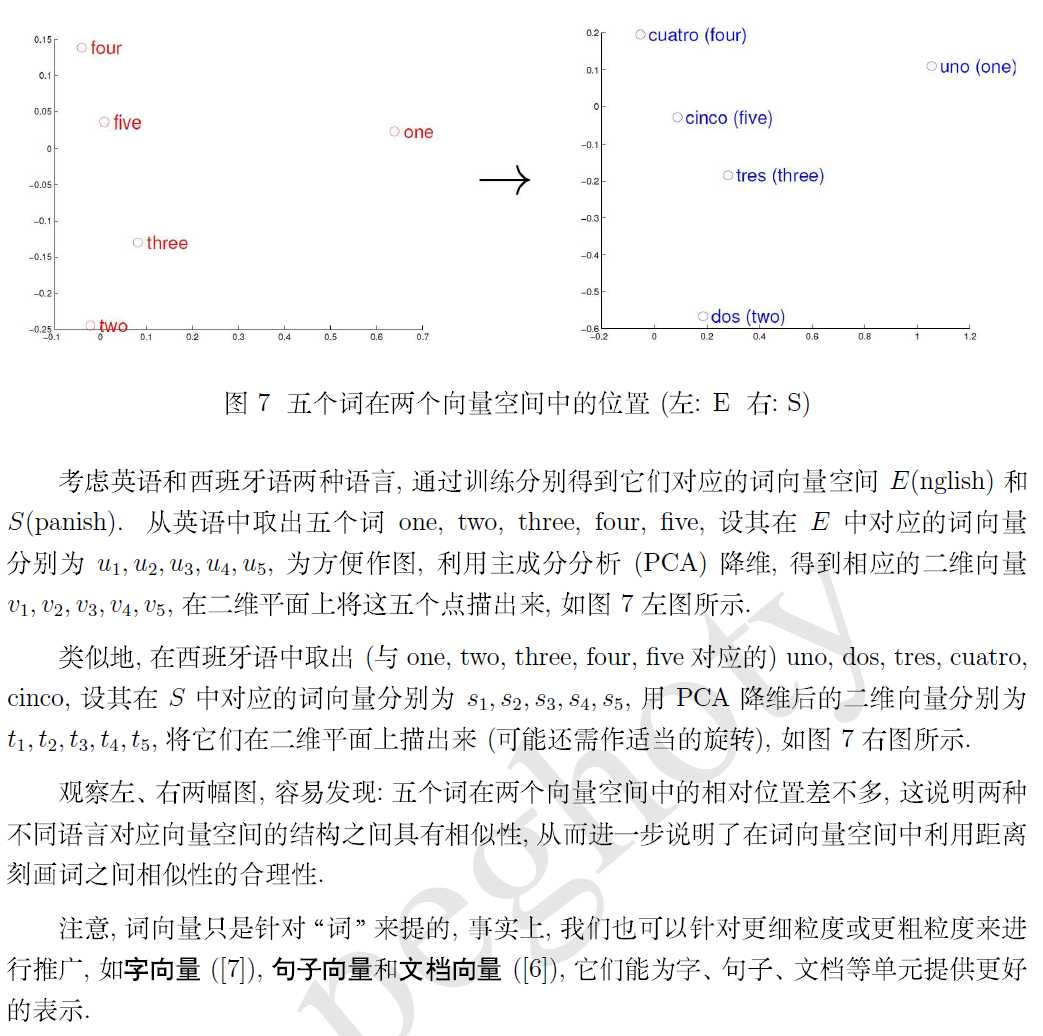

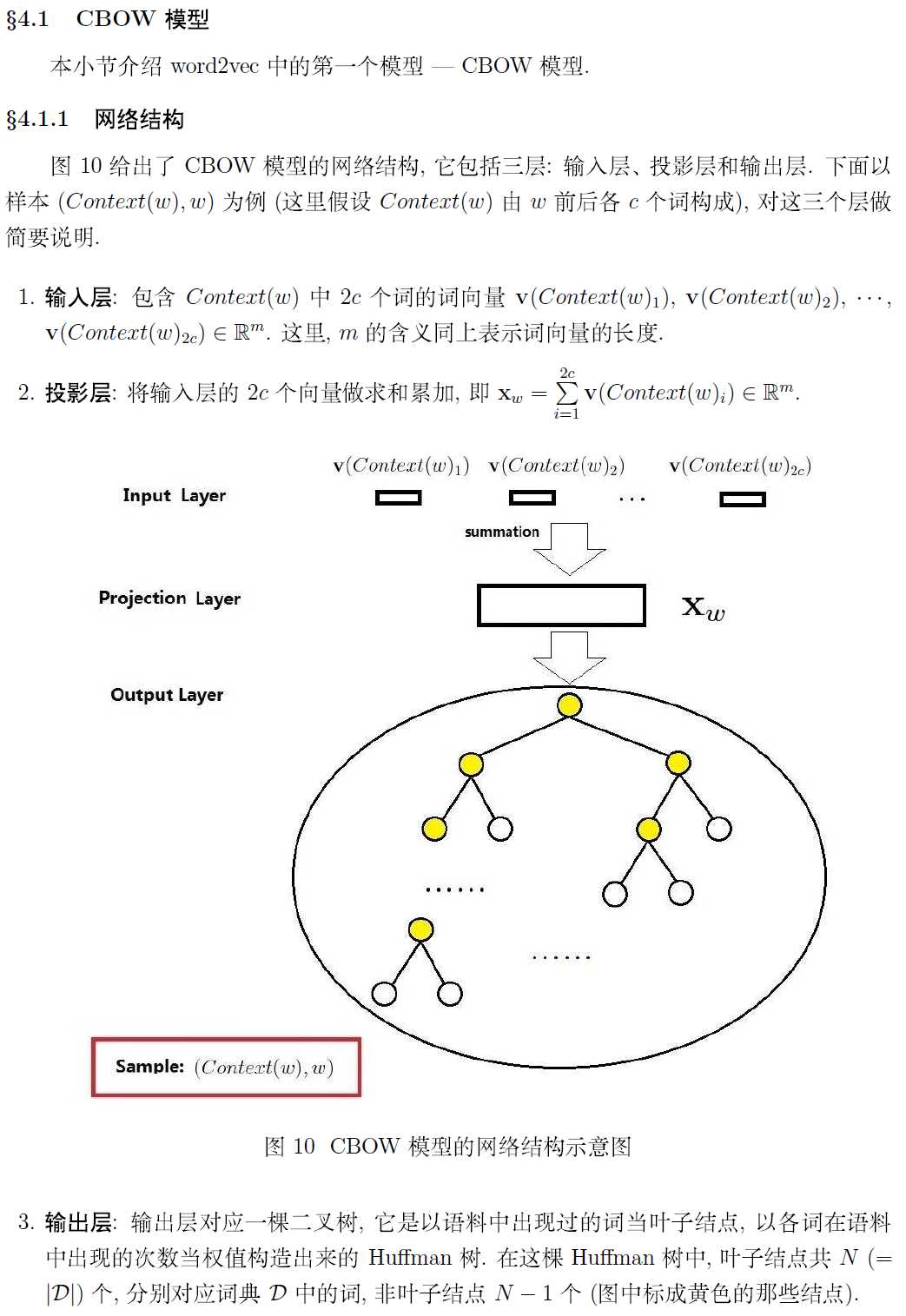

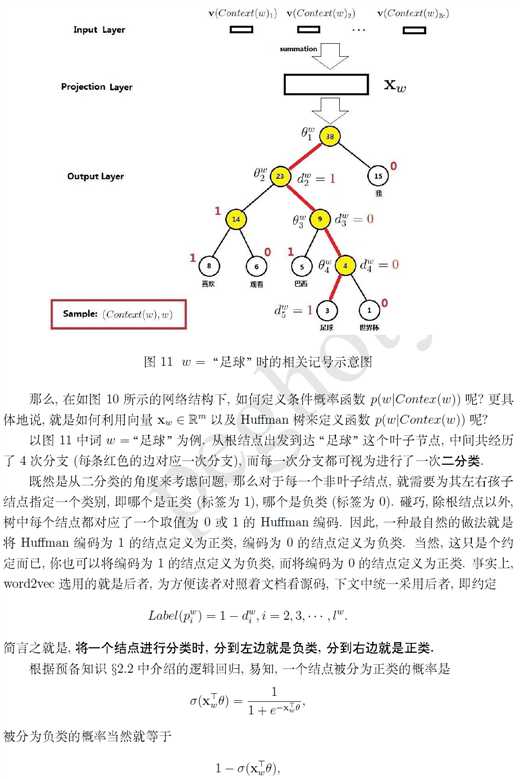



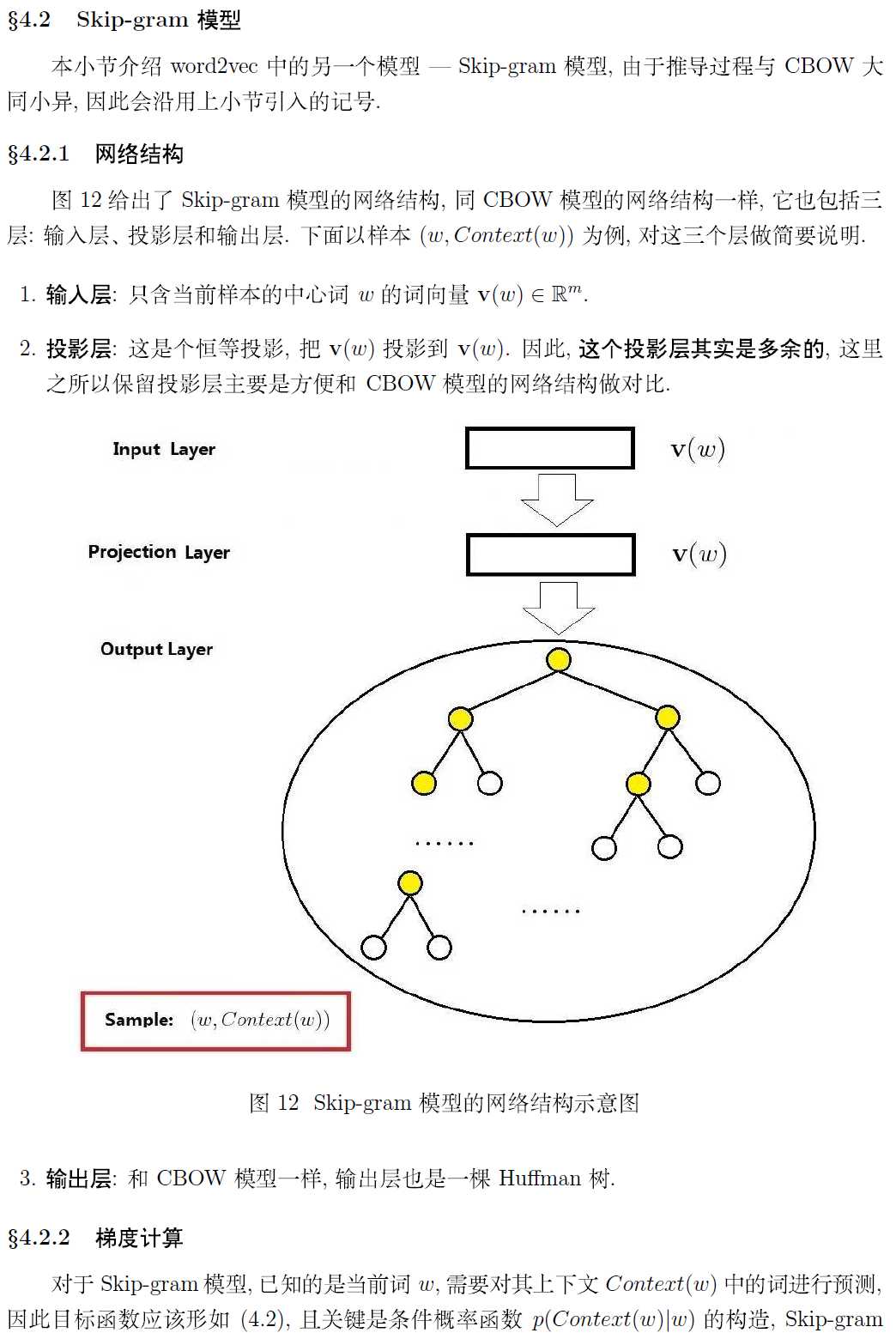



















如何使用?
from gensim.models.word2vec import Word2Vec sentences = [[‘A1‘,‘A2‘],[],[],....] model= Word2Vec() model.build_vocab(sentences) model.train(sentences,total_examples = model.corpus_count,epochs = model.iter) 保存: model.save(‘/tmp/MyModel‘) 追加加训练: model = gensim.models.Word2Vec.load(‘/tmp/mymodel‘) model.train(more_sentences) 加载: model = gensim.models.Word2Vec.load(‘/tmp/mymodel‘) 获取词向量 print(model [‘man‘]) print(type(model [‘man‘])) 输出: [0.14116223 0.05663395 0.01500377 -0.03592452 ...] numpy.ndarray
计算一个词的最近似的词,倒排序 model.most_similar([‘男人‘]) 输出:[(‘女‘,0.7664012908935547), ( ‘男孩‘,0.6824870109558105), ( ‘青少年‘,0.6586930155754089), ( ‘女孩‘,0.5921714305877686), ( ‘强盗‘,0.5585119128227234), ( ‘男‘,0.5489763021469116), (‘人‘,0.5420035719871521), ( ‘人‘,0.5342026352882385), ( ‘绅士‘,0.5337990522384644), ( ‘摩托车手‘,0.5336882472038269)] 计算两词之间的余弦相似度 word2vec一个很大的亮点:支持词语的加减运算(实际中可能只有少数例子比较符合) model.most_similar(positive = [‘woman‘,‘king‘],negative = [‘man‘],topn = 2) 输出:[(‘王后‘,0.7118192911148071),(‘君主‘,0.6189675331115723)] --- model.similarity(‘女人‘, ‘男人‘) 输出:0.7664012234410319 计算两个集合之间的余弦似度 当出现某个词语不在这个训练集合中的时候,会报错! list1 = [‘我‘,‘走‘,‘我‘,‘学校‘] list2 = [‘我‘,‘去‘,‘家‘] list_sim1 = model.n_similarity(list1,list2) print(list_sim1) 输出:0.772446878519
以上是关于NLP知识点汇总的主要内容,如果未能解决你的问题,请参考以下文章