k8s的架构设计和节点组成
Posted leo-chen-2014
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k8s的架构设计和节点组成相关的知识,希望对你有一定的参考价值。
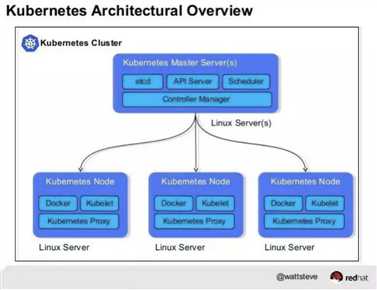
ETCd nodes:
-1 etcd用于存储Kubernetes cluster中所有的pods / nodes状态的key/value信息,同时提供高可用cluster的特性,生产环境一般提供3到5个etcd nodes以保证一致性协调服务;
etcd集群内部通过Raft一致性算法,类似于ZooKeeper,状态的更改需要超过半数的节点回复确认,因此即使出现脑裂网络分割,节点数较少的分组也无法自行修改状态,从而保证cluster nodes上的信息要么是最新的,要么是过去已经确认过的;
通过etcdctl ls /registry命令可以访问etcd中存储的资源json内容;
-2 k8s对cluster的维护是基于声明式的模式(Declarative Programming,相对于Imperative Programming),也就是维护一个期望的状态的列表(也就是每个deployment的yaml设置),以及一个当前实际状态的列表(也就是当前cluster的实际运行状态),这些状态列表会保存于etcd,其他节点通过watch / event机制获取etcd上状态的更新,并作为相关的调整;
Master nodes:
-1 kube-api-server:外部client访问k8scluster,内部pods间的相互访问都是基于该 Restful接口,另外也提供authentication,load-balance,service discover等功能;
-2 kube-scheduler:负责资源调度(待调度的pod,可用的node),如pod在cluster node上的分配, 主要分为两个阶段,predicate和priority,前者用于硬性条件的筛选,后者为适配度排序;scheduler通过调度策略决定好pod与node的mapping之后,会持久化写入etcd,然后各个node上的kubelet watcher会自动感知并更新自己node上的pod的状态;
通过PodAffinity / AntiAffinity: {TopologyKey: ‘host-name’; LabelSelector: type:redis;}设置有共同满足某些属性的pod才会被放置于同一个node上,或者某些pod不能放置于同一个node上;当部署需要支持HA特性的app instance时,这些app instance会自动被划分到不同的node上;
通过ResourceQuota / LimitRange给不同的任务组动态或者静态分配有限资源,两种控制策略的作用范围都是对于某一namespace,ResourceQuota 用来限制 namespace 中所有的 Pod 占用的总的资源 request 和 limit,而 LimitRange 是用来设置 namespace 中 Pod 的默认的资源 request 和 limit 值;
-3 kube-controller-manager:维护Kubernetes cluster的状态,保证cluster实际的状态和etcd中期望的状态一致,监听cluster中各个node上的kubelet的回传状态,并更新etcd中的状态,如扩容和缩容,版本更新,故障检测等;一共包含八个controller:replication, node, resource quota, name space, service account, token, service, endpoint;
Worker nodes:
运行pod的host, 一个pod只能运行于一个node上,但在一个node上可以由多个pod;每个pod可由多个containers组成,这些container共享同一个node上的network和disk,方便k8s进行进行统一调度和管理,Persistent Volume和Persistent Volume Claim可以pod为单位提供statefulSet的存储功能,并可以忽略具体的存储技术设备(AWS / GFS);
-1 kubelet:负责当前node上的pods、network和volume的管理和监控,处理来自master的指令,同时读取etcd中关于service的spec,并将service实际的运行状态更新到etcd中status;如监控当前node上的pod运行状态,并上报给rc;
当前node上pod的创建和销毁都是由kubelet控制的,而其他的比如ReplicaSet,Deployment,StatefulSet等都是通过修改etcd中pod template的状态,通过kubelet watcher触发各个node上的pod的状态变更;
-2 kube-proxy:充当service抽象层,为当前node上所有pods提供统一的逻辑访问接口,同时提供鉴权,routing和Load Balance功能;
-3 container-runtime:提供container运行环境,如docker,rkt或者其他容器实现标准;
Add ons:
-1 kube-dns:为cluster提供DNS服务,允许pod之间通过domain name进行相互访问,允许service之间通过service name进行相互访问;
Kube-dns以独立pod的形式运行在kube-system namespace,通过watch etcd中service,pod endpoint的变化,更新domain -> ip的映射,其他的pod的容器内/etc/reslv.conf中会缺省配置kube-dns的domain -ip映射,从而为当前node上的service提供domain -> endpoint的转换服务;
-2 ingress-controller:为service提供外网访问入口
通常情况下service和pod暴露的IP仅能在k8s cluster内部进行访问,如果client需要访问k8s cluster通常需要通过Ingress进行转发,Ingress是授权client request进入k8s cluster的一系列的规则集合;
-3 dashboard:提供cluster的GUI访问界面;
-4 fluentd-elasticsearch:提供cluster logs的采集、存储和访问接口;
-5 federation: 跨集群和跨机房网络部署(配合HAproxy实现)
以上是关于k8s的架构设计和节点组成的主要内容,如果未能解决你的问题,请参考以下文章