算法分析三:分治策略
Posted dr-xsh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法分析三:分治策略相关的知识,希望对你有一定的参考价值。
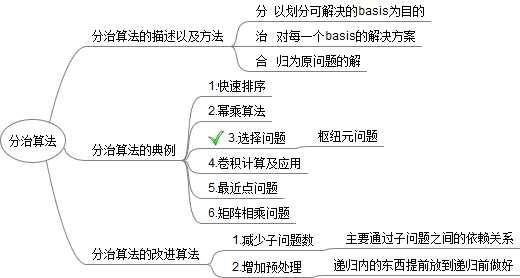
一.基本结构图
二.典例
1.以斐波那契递归为例:
Fibonacci(int n)
{
if (n==1||n==0) return 1; // basis
else
return Fibonacci(n-1)+Fibonacci(n-2);//递归进行
}
我们找到了解决斐波那契数的方法,但是通过递归树来分析这个递归的过程,我们会发现该程序大量重复调用不需要的函数如f(3)等等。违背了递归的一般原则。
add:递归的一般原则:
1.基准原则:即必须有解决basis的方案
2.不断推进原则:即可以从原问题递归的推到basis
3.设计原则:假设的所有的递归调用都能运行
4.合成效益法则:即在求解一个问题实例时,切勿在不同的递归调用中做着重复的工作。
实际上在学习动态规划后我们可以增添一个len数组来改进改算法。
2.快速排序
算法:

2.

3.

4.分治问题的改进
1.整数相乘问题:
X=61438521,Y=94736407,则X*Y=5820464730934047
若将X,Y拆成两半,即Xl=6143,Xr=8521,Yl=9473,Yr=6407;那么XY=Xl*Yl*10^8+(Xl*Yr+Xr*Yl)10^4+Xr*Yr
递归实现T(n)=4T(n/2)+O(n)
事实上该算法可以进行改进:
观察子问题之间关系可发现:Xl*Yr+Xr*Yl =(Xl-Xr)(Yr-Yl)+Xl*Yl+Xr*Yr
那么T(n)=3T(n/2)+O(n)
减少了子问题的个数。
2.矩阵乘法
//该部分引自:https://www.cnblogs.com/hdk1993/p/4552534.html
思路分析
根据wikipedia上的介绍:两个矩阵的乘法仅当第一个矩阵B的列数和另一个矩阵A的行数相等时才能定义。如A是m×n矩阵和B是n×p矩阵,它们的乘积AB是一个m×p矩阵,它的一个元素其中 1 ≤ i ≤ m, 1 ≤ j ≤ p。
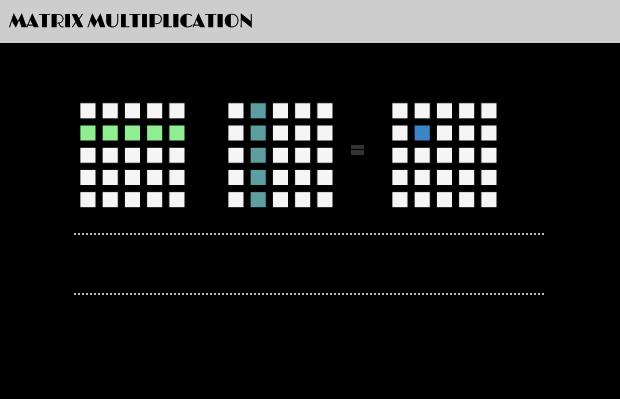
值得一提的是,矩阵乘法满足结合律和分配率,但并不满足交换律,如下图所示的这个例子,两个矩阵交换相乘后,结果变了:

下面咱们来具体解决这个矩阵相乘的问题。
解法一、暴力解法
其实,通过前面的分析,我们已经很明显的看出,两个具有相同维数的矩阵相乘,其复杂度为O(n^3),参考代码如下:
- //矩阵乘法,3个for循环搞定
- void Mul(int** matrixA, int** matrixB, int** matrixC)
- {
- for(int i = 0; i < 2; ++i)
- {
- for(int j = 0; j < 2; ++j)
- {
- matrixC[i][j] = 0;
- for(int k = 0; k < 2; ++k)
- {
- matrixC[i][j] += matrixA[i][k] * matrixB[k][j];
- }
- }
- }
- }
解法二、Strassen算法
在解法一中,我们用了3个for循环搞定矩阵乘法,但当两个矩阵的维度变得很大时,O(n^3)的时间复杂度将会变得很大,于是,我们需要找到一种更优的解法。
一般说来,当数据量一大时,我们往往会把大的数据分割成小的数据,各个分别处理。遵此思路,如果丢给我们一个很大的两个矩阵呢,是否可以考虑分治的方法循序渐进处理各个小矩阵的相乘,因为我们知道一个矩阵是可以分成更多小的矩阵的。
如下图,当给定一个两个二维矩阵A B时:
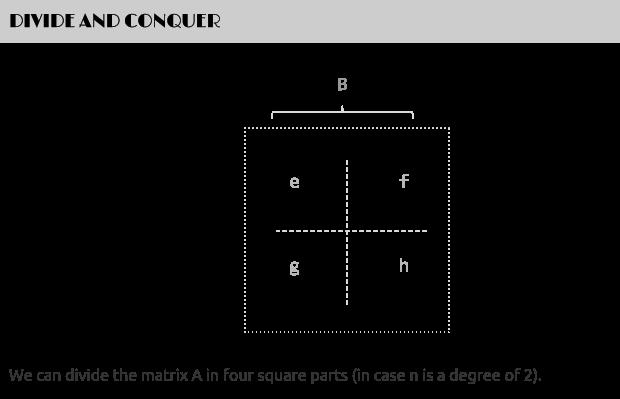
这两个矩阵A B相乘时,我们发现在相乘的过程中,有8次乘法运算,4次加法运算:

矩阵乘法的复杂度主要就是体现在相乘上,而多一两次的加法并不会让复杂度上升太多。故此,我们思考,是否可以让矩阵乘法的运算过程中乘法的运算次数减少,从而达到降低矩阵乘法的复杂度呢?答案是肯定的。
1969年,德国的一位数学家Strassen证明O(N^3)的解法并不是矩阵乘法的最优算法,他做了一系列工作使得最终的时间复杂度降低到了O(n^2.80)。
他是怎么做到的呢?还是用上文A B两个矩阵相乘的例子,他定义了7个变量:

如此,Strassen算法的流程如下:
- 两个矩阵A B相乘时,将A, B, C分成相等大小的方块矩阵:
;
- 可以看出C是这么得来的:
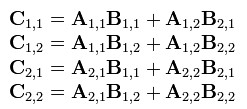
- 现在定义7个新矩阵(读者可以思考下,这7个新矩阵是如何想到的):
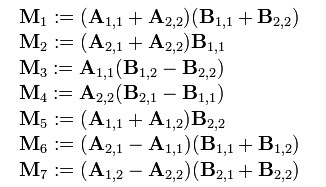
- 而最后的结果矩阵C 可以通过组合上述7个新矩阵得到:
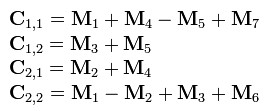
表面上看,Strassen算法仅仅比通用矩阵相乘算法好一点,因为通用矩阵相乘算法时间复杂度是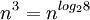 ,而Strassen算法复杂度只是
,而Strassen算法复杂度只是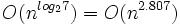 。但随着n的变大,比如当n >> 100时,Strassen算法是比通用矩阵相乘算法变得更有效率。
。但随着n的变大,比如当n >> 100时,Strassen算法是比通用矩阵相乘算法变得更有效率。
具体实现的伪代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
Strassen (N,MatrixA,MatrixB,MatrixResult) //splitting input Matrixes, into 4 submatrices each. for i <- 0 to N/2 for j <- 0 to N/2 A11[i][j] <- MatrixA[i][j]; //a矩阵块 A12[i][j] <- MatrixA[i][j + N / 2]; //b矩阵块 A21[i][j] <- MatrixA[i + N / 2][j]; //c矩阵块 A22[i][j] <- MatrixA[i + N / 2][j + N / 2];//d矩阵块 B11[i][j] <- MatrixB[i][j]; //e 矩阵块 B12[i][j] <- MatrixB[i][j + N / 2]; //f 矩阵块 B21[i][j] <- MatrixB[i + N / 2][j]; //g 矩阵块 B22[i][j] <- MatrixB[i + N / 2][j + N / 2]; //h矩阵块 //here we calculate M1..M7 matrices . //递归求M1 HalfSize <- N/2 AResult <- A11+A22 BResult <- B11+B22 Strassen( HalfSize, AResult, BResult, M1 ); //M1=(A11+A22)*(B11+B22) p5=(a+d)*(e+h) //递归求M2 AResult <- A21+A22 Strassen(HalfSize, AResult, B11, M2); //M2=(A21+A22)B11 p3=(c+d)*e //递归求M3 BResult <- B12 - B22 Strassen(HalfSize, A11, BResult, M3); //M3=A11(B12-B22) p1=a*(f-h) //递归求M4 BResult <- B21 - B11 Strassen(HalfSize, A22, BResult, M4); //M4=A22(B21-B11) p4=d*(g-e) //递归求M5 AResult <- A11+A12 Strassen(HalfSize, AResult, B22, M5); //M5=(A11+A12)B22 p2=(a+b)*h //递归求M6 AResult <- A21-A11 BResult <- B11+B12 Strassen( HalfSize, AResult, BResult, M6); //M6=(A21-A11)(B11+B12) p7=(c-a)(e+f) //递归求M7 AResult <- A12-A22 BResult <- B21+B22 Strassen(HalfSize, AResult, BResult, M7); //M7=(A12-A22)(B21+B22) p6=(b-d)*(g+h) //计算结果子矩阵 C11 <- M1 + M4 - M5 + M7; C12 <- M3 + M5; C21 <- M2 + M4; C22 <- M1 + M3 - M2 + M6; //at this point , we have calculated the c11..c22 matrices, and now we are going to //put them together and make a unit matrix which would describe our resulting Matrix. for i <- 0 to N/2 for j <- 0 to N/2 MatrixResult[i][j] <- C11[i][j]; MatrixResult[i][j + N / 2] <- C12[i][j]; MatrixResult[i + N / 2][j] <- C21[i][j]; MatrixResult[i + N / 2][j + N / 2] <- C22[i][j]; |
具体测试代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
|
// 4-2.矩阵乘法的Strassen算法.cpp : 定义控制台应用程序的入口点。//#include "stdafx.h"#include <iostream>#include <ctime>#include <Windows.h>using namespace std;template<typename T>class Strassen_class{public: void ADD(T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize ); void SUB(T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize ); void MUL( T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize );//朴素算法实现 void FillMatrix( T** MatrixA, T** MatrixB, int length);//A,B矩阵赋值 void PrintMatrix(T **MatrixA,int MatrixSize);//打印矩阵 void Strassen(int N, T **MatrixA, T **MatrixB, T **MatrixC);//Strassen算法实现};template<typename T>void Strassen_class<T>::ADD(T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize ){ for ( int i = 0; i < MatrixSize; i++) { for ( int j = 0; j < MatrixSize; j++) { MatrixResult[i][j] = MatrixA[i][j] + MatrixB[i][j]; } }}template<typename T>void Strassen_class<T>::SUB(T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize ){ for ( int i = 0; i < MatrixSize; i++) { for ( int j = 0; j < MatrixSize; j++) { MatrixResult[i][j] = MatrixA[i][j] - MatrixB[i][j]; } }}template<typename T>void Strassen_class<T>::MUL( T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize ){ for (int i=0;i<MatrixSize ;i++) { for (int j=0;j<MatrixSize ;j++) { MatrixResult[i][j]=0; for (int k=0;k<MatrixSize ;k++) { MatrixResult[i][j]=MatrixResult[i][j]+MatrixA[i][k]*MatrixB[k][j]; } } }}/*c++使用二维数组,申请动态内存方法申请int **A;A = new int *[desired_array_row];for ( int i = 0; i < desired_array_row; i++) A[i] = new int [desired_column_size];释放for ( int i = 0; i < your_array_row; i++) delete [] A[i];delete[] A;*/template<typename T>void Strassen_class<T>::Strassen(int N, T **MatrixA, T **MatrixB, T **MatrixC){ int HalfSize = N/2; int newSize = N/2; if ( N <= 64 ) //分治门槛,小于这个值时不再进行递归计算,而是采用常规矩阵计算方法 { MUL(MatrixA,MatrixB,MatrixC,N); } else { T** A11; T** A12; T** A21; T** A22; T** B11; T** B12; T** B21; T** B22; T** C11; T** C12; T** C21; T** C22; T** M1; T** M2; T** M3; T** M4; T** M5; T** M6; T** M7; T** AResult; T** BResult; //making a 1 diminsional pointer based array. A11 = new T *[newSize]; A12 = new T *[newSize]; A21 = new T *[newSize]; A22 = new T *[newSize]; B11 = new T *[newSize]; B12 = new T *[newSize]; B21 = new T *[newSize]; B22 = new T *[newSize]; C11 = new T *[newSize]; C12 = new T *[newSize]; C21 = new T *[newSize]; C22 = new T *[newSize]; M1 = new T *[newSize]; M2 = new T *[newSize]; M3 = new T *[newSize]; M4 = new T *[newSize]; M5 = new T *[newSize]; M6 = new T *[newSize]; M7 = new T *[newSize]; AResult = new T *[newSize]; BResult = new T *[newSize]; int newLength = newSize; //making that 1 diminsional pointer based array , a 2D pointer based array for ( int i = 0; i < newSize; i++) { A11[i] = new T[newLength]; A12[i] = new T[newLength]; A21[i] = new T[newLength]; A22[i] = new T[newLength]; B11[i] = new T[newLength]; B12[i] = new T[newLength]; B21[i] = new T[newLength]; B22[i] = new T[newLength]; C11[i] = new T[newLength]; C12[i] = new T[newLength]; C21[i] = new T[newLength]; C22[i] = new T[newLength]; M1[i] = new T[newLength]; M2[i] = new T[newLength]; M3[i] = new T[newLength]; M4[i] = new T[newLength]; M5[i] = new T[newLength]; M6[i] = new T[newLength]; M7[i] = new T[newLength]; AResult[i] = new T[newLength]; BResult[i] = new T[newLength]; } //splitting input Matrixes, into 4 submatrices each. for (int i = 0; i < N / 2; i++) { for (int j = 0; j < N / 2; j++) { A11[i][j] = MatrixA[i][j]; A12[i][j] = MatrixA[i][j + N / 2]; A21[i][j] = MatrixA[i + N / 2][j]; A22[i][j] = MatrixA[i + N / 2][j + N / 2]; B11[i][j] = MatrixB[i][j]; B12[i][j] = MatrixB[i][j + N / 2]; B21[i][j] = MatrixB[i + N / 2][j]; B22[i][j] = MatrixB[i + N / 2][j + N / 2]; } } //here we calculate M1..M7 matrices . //M1[][] ADD( A11,A22,AResult, HalfSize); ADD( B11,B22,BResult, HalfSize); //p5=(a+d)*(e+h) Strassen( HalfSize, AResult, BResult, M1 ); //now that we need to multiply this , we use the strassen itself . //M2[][] ADD( A21,A22,AResult, HalfSize); //M2=(A21+A22)B11 p3=(c+d)*e Strassen(HalfSize, AResult, B11, M2); //Mul(AResult,B11,M2); //M3[][] SUB( B12,B22,BResult, HalfSize); //M3=A11(B12-B22) p1=a*(f-h) Strassen(HalfSize, A11, BResult, M3); //Mul(A11,BResult,M3); //M4[][] SUB( B21, B11, BResult, HalfSize); //M4=A22(B21-B11) p4=d*(g-e) Strassen(HalfSize, A22, BResult, M4); //Mul(A22,BResult,M4); //M5[][] ADD( A11, A12, AResult, HalfSize); //M5=(A11+A12)B22 p2=(a+b)*h Strassen(HalfSize, AResult, B22, M5); //Mul(AResult,B22,M5); //M6[][] SUB( A21, A11, AResult, HalfSize); ADD( B11, B12, BResult, HalfSize); //M6=(A21-A11)(B11+B12) p7=(c-a)(e+f) Strassen( HalfSize, AResult, BResult, M6); //Mul(AResult,BResult,M6); //M7[][] SUB(A12, A22, AResult, HalfSize); ADD(B21, B22, BResult, HalfSize); //M7=(A12-A22)(B21+B22) p6=(b-d)*(g+h) Strassen(HalfSize, AResult, BResult, M7); //Mul(AResult,BResult,M7); //C11 = M1 + M4 - M5 + M7; ADD( M1, M4, AResult, HalfSize); SUB( M7, M5, BResult, HalfSize); ADD( AResult, BResult, C11, HalfSize); //C12 = M3 + M5; ADD( M3, M5, C12, HalfSize); //C21 = M2 + M4; ADD( M2, M4, C21, HalfSize); //C22 = M1 + M3 - M2 + M6; ADD( M1, M3, AResult, HalfSize); SUB( M6, M2, BResult, HalfSize); ADD( AResult, BResult, C22, HalfSize); //at this point , we have calculated the c11..c22 matrices, and now we are going to //put them together and make a unit matrix which would describe our resulting Matrix. //组合小矩阵到一个大矩阵 for (int i = 0; i < N/2 ; i++) { for (int j = 0 ; j < N/2 ; j++) { MatrixC[i][j] = C11[i][j]; MatrixC[i][j + N / 2] = C12[i][j]; MatrixC[i + N / 2][j] = C21[i][j]; MatrixC[i + N / 2][j + N / 2] = C22[i][j]; } } // 释放矩阵内存空间 for (int i = 0; i < newLength; i++) { delete[] A11[i];delete[] A12[i];delete[] A21[i]; delete[] A22[i]; delete[] B11[i];delete[] B12[i];delete[] B21[i]; delete[] B22[i]; delete[] C11[i];delete[] C12[i];delete[] C21[i]; delete[] C22[i]; delete[] M1[i];delete[] M2[i];delete[] M3[i];delete[] M4[i]; delete[] M5[i];delete[] M6[i];delete[] M7[i]; delete[] AResult[i];delete[] BResult[i] ; } delete[] A11;delete[] A12;delete[] A21;delete[] A22; delete[] B11;delete[] B12;delete[] B21;delete[] B22; delete[] C11;delete[] C12;delete[] C21;delete[] C22; delete[] M1;delete[] M2;delete[] M3;delete[] M4;delete[] M5; delete[] M6;delete[] M7; delete[] AResult; delete[] BResult ; }//end of else}template<typename T>void Strassen_class<T>::FillMatrix( T** MatrixA, T** MatrixB, int length){ for(int row = 0; row<length; row++) { for(int column = 0; column<length; column++) { MatrixB[row][column] = (MatrixA[row][column] = rand() %5); //matrix2[row][column] = rand() % 2;//ba hazfe in khat 50% afzayeshe soorat khahim dasht } }}template<typename T>void Strassen_class<T>::PrintMatrix(T **MatrixA,int MatrixSize){ cout<<endl; for(int row = 0; row<MatrixSize; row++) { for(int column = 0; column<MatrixSize; column++) { cout<<MatrixA[row][column]<<" "; if ((column+1)%((MatrixSize)) == 0) cout<<endl; } } cout<<endl;}int _tmain(int argc, _TCHAR* argv[]){ Strassen_class<int> stra;//定义Strassen_class类对象 int MatrixSize = 0; int** MatrixA; //存放矩阵A int** MatrixB; //存放矩阵B int** MatrixC; //存放结果矩阵 clock_t startTime_For_Normal_Multipilication ; clock_t endTime_For_Normal_Multipilication ; clock_t startTime_For_Strassen ; clock_t endTime_For_Strassen ; srand(time(0)); cout<<"
请输入矩阵大小(必须是2的幂指数值(例如:32,64,512,..): "; cin>>MatrixSize; int N = MatrixSize;//for readiblity. //申请内存 MatrixA = new int *[MatrixSize]; MatrixB = new int *[MatrixSize]; MatrixC = new int *[MatrixSize]; for (int i = 0; i < MatrixSize; i++) { MatrixA[i] = new int [MatrixSize]; MatrixB[i] = new int [MatrixSize]; MatrixC[i] = new int [MatrixSize]; } stra.FillMatrix(MatrixA,MatrixB,MatrixSize); //矩阵赋值 //*******************conventional multiplication test cout<<"朴素矩阵算法开始时钟: "<< (startTime_For_Normal_Multipilication = clock()); stra.MUL(MatrixA,MatrixB,MatrixC,MatrixSize);//朴素矩阵相乘算法 T(n) = O(n^3) cout<<"
朴素矩阵算法结束时钟: "<< (endTime_For_Normal_Multipilication = clock()); cout<<"
矩阵运算结果...
"; stra.PrintMatrix(MatrixC,MatrixSize); //*******************Strassen multiplication test cout<<"
Strassen算法开始时钟: "<< (startTime_For_Strassen = clock()); stra.Strassen( N, MatrixA, MatrixB, MatrixC ); //strassen矩阵相乘算法 cout<<"
Strassen算法结束时钟: "<<(endTime_For_Strassen = clock()); cout<<"
矩阵运算结果...
"; stra.PrintMatrix(MatrixC,MatrixSize); cout<<"矩阵大小 "<<MatrixSize; cout<<"
朴素矩阵算法: "<<(endTime_For_Normal_Multipilication - startTime_For_Normal_Multipilication)<<" Clocks.."<<(endTime_For_Normal_Multipilication - startTime_For_Normal_Multipilication)/CLOCKS_PER_SEC<<" Sec"; cout<<"
Strassen算法:"<<(endTime_For_Strassen - startTime_For_Strassen)<<" Clocks.."<<(endTime_For_Strassen - startTime_For_Strassen)/CLOCKS_PER_SEC<<" Sec
"; system("Pause"); return 0;} |
运行结果:

性能分析:


数据取600位上界,即超过10分钟跳出。可以看到使用Strassen算法时,耗时不但没有减少,反而剧烈增多,在n=700时计算时间就无法忍受。仔细研究后发现,采用Strassen算法作递归运算,需要创建大量的动态二维数组,其中分配堆内存空间将占用大量计算时间,从而掩盖了Strassen算法的优势。于是对Strassen算法做出改进,设定一个界限。当n<界限时,使用普通法计算矩阵,而不继续分治递归。
改进后算法优势明显,就算时间大幅下降。之后,针对不同大小的界限进行试验。在初步试验中发现,当数据规模小于1000时,下界S法的差别不大,规模大于1000以后,n取值越大,消耗时间下降。最优的界限值在32~128之间。
因为计算机每次运算时的系统环境不同(CPU占用、内存占用等),所以计算出的时间会有一定浮动。虽然这样,试验结果已经能得出结论Strassen算法比常规法优势明显。使用下界法改进后,在分治效率和动态分配内存间取舍,针对不同的数据规模稍加试验可以得到一个最优的界限。
小结:
1)采用Strassen算法作递归运算,需要创建大量的动态二维数组,其中分配堆内存空间将占用大量计算时间,从而掩盖了Strassen算法的优势
2)于是对Strassen算法做出改进,设定一个界限。当n<界限时,使用普通法计算矩阵,而不继续分治递归。需要合理设置界限,不同环境(硬件配置)下界限不同
3)矩阵乘法一般意义上还是选择的是朴素的方法,只有当矩阵变稠密,而且矩阵的阶数很大时,才会考虑使用Strassen算法。
以上是关于算法分析三:分治策略的主要内容,如果未能解决你的问题,请参考以下文章