多线程与并发6 并发容器
Posted zdcsmart
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多线程与并发6 并发容器相关的知识,希望对你有一定的参考价值。
-
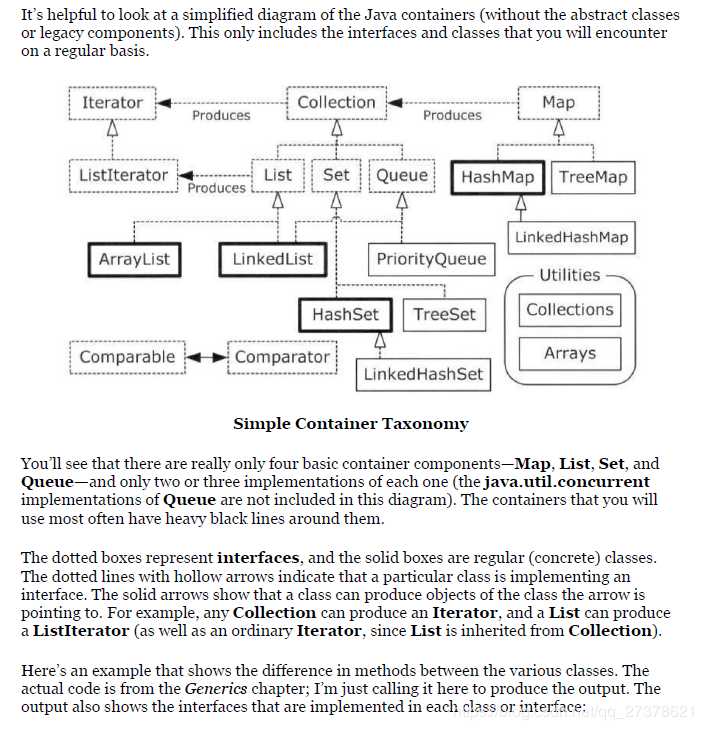
容器架构
-
Hashtable HashMap SynchronizedHashMap CurrentHashMap CurrentSkipListMap(弥补同步的TreeMap)
Hashtable所以方法默认加sychronized,
HashMap默认没有加锁,
而SynchronizedHashMap默认是Collections.synchronizedMap(Map<k,v> map)返回一个同步map。
CurrentHashMap是多线程真正用的,本来是拉链表,JDK1.8后变成红黑树.
ConcurrentHashMap相比HashMap而言,是多线程安全的,其底层数据与HashMap的数据结构相同,数据结构如下:
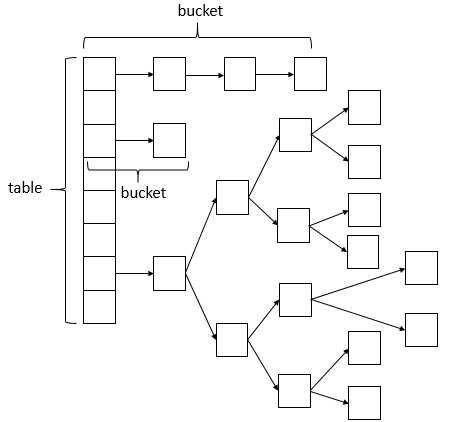
ConcurrentHashMap的数据结构(数组+链表+红黑树),桶中的结构可能是链表,也可能是红黑树,红黑树是为了提高查找效率。
ConcurrentHashMap为什么高效?
JDK1.5中的实现
ConcurrentHashMap使用的是分段锁技术,将ConcurrentHashMap将锁一段一段的存储,然后给每一段数据配一把锁(segment),当一个线程占用一把锁(segment)访问其中一段数据的时候,其他段的数据也能被其它的线程访问,默认分配16个segment。默认比Hashtable效率提高16倍。
ConcurrentHashMap的结构图如下(网友贡献的图,哈):

JDK1.8中的实现
ConcurrentHashMap取消了segment分段锁,而采用CAS和synchronized来保证并发安全。数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。
synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
JDK1.8的ConcurrentHashMap的结构图如下:

TreeBin: 红黑二叉树节点
Node: 链表节点
ConcurrentHashMap 源码分析
ConcurrentHashMap 类结构参照HashMap,这里列出HashMap没有的几个属性。
/**
* Table initialization and resizing control. When negative, the
* table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads). Otherwise,
* when table is null, holds the initial table size to use upon
* creation, or 0 for default. After initialization, holds the
* next element count value upon which to resize the table.
hash表初始化或扩容时的一个控制位标识量。
负数代表正在进行初始化或扩容操作
-1代表正在初始化
-N 表示有N-1个线程正在进行扩容操作
正数或0代表hash表还没有被初始化,这个数值表示初始化或下一次进行扩容的大小
*/
private transient volatile int sizeCtl;
// 以下两个是用来控制扩容的时候 单线程进入的变量
/**
* The number of bits used for generation stamp in sizeCtl.
* Must be at least 6 for 32bit arrays.
*/
private static int RESIZE_STAMP_BITS = 16;
/**
* The bit shift for recording size stamp in sizeCtl.
*/
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
/*
* Encodings for Node hash fields. See above for explanation.
*/
static final int MOVED = -1; // hash值是-1,表示这是一个forwardNode节点
static final int TREEBIN = -2; // hash值是-2 表示这时一个TreeBin节点
分析代码主要目的:分析是如果利用CAS和Synchronized进行高效的同步更新数据。
下面插入数据源码:
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
//ConcurrentHashMap 不允许插入null键,HashMap允许插入一个null键
if (key == null || value == null) throw new NullPointerException();
//计算key的hash值
int hash = spread(key.hashCode());
int binCount = 0;
//for循环的作用:因为更新元素是使用CAS机制更新,需要不断的失败重试,直到成功为止。
for (Node<K,V>[] tab = table;;) {
// f:链表或红黑二叉树头结点,向链表中添加元素时,需要synchronized获取f的锁。
Node<K,V> f; int n, i, fh;
//判断Node[]数组是否初始化,没有则进行初始化操作
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//通过hash定位Node[]数组的索引坐标,是否有Node节点,如果没有则使用CAS进行添加(链表的头结点),添加失败则进入下次循环。
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//检查到内部正在移动元素(Node[] 数组扩容)
else if ((fh = f.hash) == MOVED)
//帮助它扩容
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//锁住链表或红黑二叉树的头结点
synchronized (f) {
//判断f是否是链表的头结点
if (tabAt(tab, i) == f) {
//如果fh>=0 是链表节点
if (fh >= 0) {
binCount = 1;
//遍历链表所有节点
for (Node<K,V> e = f;; ++binCount) {
K ek;
//如果节点存在,则更新value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)