Free-Form Image Inpainting with Gated Convolution
Posted wenshinlee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Free-Form Image Inpainting with Gated Convolution相关的知识,希望对你有一定的参考价值。
摘要
-
不同于
vanilla convolution,将所有输入的像素做为有效像素(valid pixels),gated convolution,是一个基于partial convolution的,不同的是gated convolution为所有通道和每一个维度的位置(inside or outside masks, RGB channels or user-guidance channels)提供了一种可学习的,动态的特征选择机制。 -
为了稳定加速训练,提出了
patch-based GAN loss,即SN-PatchGAN。SN-patchGAN是通过应用spectral normalized discriminator on dense image patches.
Introduction
-
图像修复别名:
Image inpainting、image completion、image hole-filling。 -
图像修复定义:在缺失区域图像中,合成替代内容。
-
图像修复的用途:可以用于移除分散注意力的物体或修改照片中不需要的区域。还可以扩展到图像/视频剪切(
un-cropping)、旋转、拼接、重新定位(re-targeting)、重新组合(recompression)、超分辨率、协调(harmonization)和许多其它任务。 -
图像修复分类:
- 使用低阶图像特征的块(patch)匹配。
- 生成看似合理的平稳纹理(
stationary textures)。 - 在处理复杂的场景,例如人脸和物体时候,常出现严重给的错误。
- 生成看似合理的平稳纹理(
- 使用卷积神经网络的前馈生成模型。
- 从大规模数据集中学习到的语义,以端到端的方式合成非平稳图像中的内容。
- 但是普通卷积的深度生成模型,在图像的填充上存在严重的问题,因为普通卷积视所有输入的像素和特征,均为有效像素。对于图像填充来说,每一层的输入是由缺失外(hole 外)的有效像素/特征和缺失区域(掩码区域)的无效像素组成的。普通卷积使用了相同的卷积核,适用于所有有效、无效和混合(列如,那些空洞边界)的像素/特征,在自由形状上的掩码做测试时,导致视觉的伪影(如颜色差异,模糊和孔周围明显的边缘响应)
- 使用低阶图像特征的块(patch)匹配。
-
为了解决这一局限性,部分卷积(
PartialConv),其中卷积被掩蔽(masked)和归一化,仅以有效像素为条件。基于规则的掩码更新策略,用于更新下一层的有效位置。部分卷积将所有位置视为无效或有效,并用0或1掩码乘以所有层的输入,该掩码可以看做是一个单一的不可学习的特征门(gate)通道。 -
然而,这种假设是有个几个局限性:
- 考虑跨网络不同层的输入空间位置,他们可能包括:
- 输入图像中有有效像素
- 输入图像中有掩蔽像素
- 感受野的神经元没有覆盖到输入图像的有效像素
- 感受野的神经元覆盖了不同数量的输入图像的有效像素(这些有效的图像像素也可能有不同的相对位置)
- 深层合成的像素。
- 启发式的将所有的位置归类为无效或有效,会忽略以上这些重要信息。
- 如果我们拓展到用户指导的图像修复,用户在掩码内提供的稀疏的草图(sparse sketch),这些像素位置应该被视为有效的还是无效的?如何正确地更新下一层的掩码?
- 对于部分卷积,无效的像素将逐层逐渐消失,基于规则的掩码将在深层全部消失。然而,为了合成孔内的像素,这些深层可能还需要知道当前位置是在孔内还是孔外?全
1掩码的部分卷积不能提供这样的信息。
- 考虑跨网络不同层的输入空间位置,他们可能包括:
-
gated convolution 掩码更新过程:the input feature is firstly used to compute gating values (g = σ(w_gx)) ((σ) is sigmoid function, (w_g) is learnable parameter). The final output is a multiplication of learned feature and gating values (y = φ(wx)⊙g) where φ can be any activation function. -
与其他算法对比优势:
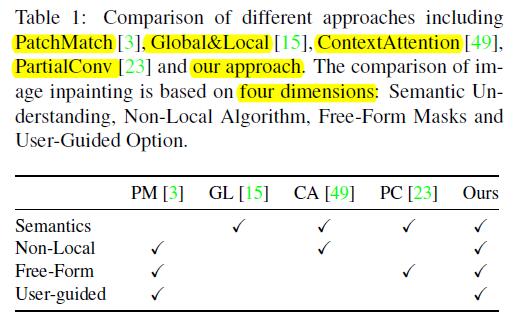
Approach
目录结构:1.Gated Convolution,SN-PatchGAN,2.inpainting network,3. our extension to allow optional user guidance.
Gated Convolution
- 证明为什么
vanilla convolutions不适合图像修复任务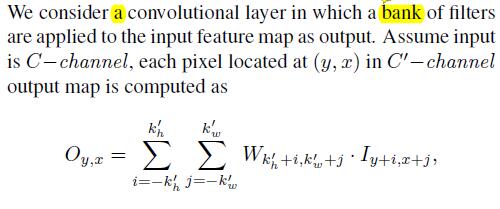
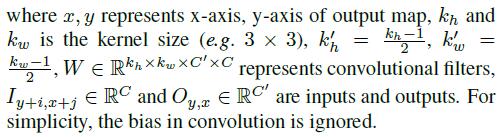
The equation shows that for all spatial locations (y, x), the same filters are applied to produce the output in vanilla convolutional layers.This makes sense for tasks such as image classification and object detection, where all pixels of input image are valid, to extract local features in a sliding window fashion.However, for image inpainting, the input are composed(组成) of both regions with valid pixels/features outside holes and invalid pixels/features (in shallow layers) or synthesized pixels/features (in deep layers) in masked regions. This causes ambiguity (歧义) during training and leads to visual artifacts such as color discrepancy(差异), blurriness and obvious edge responses during testing.- 普通卷积是将每一个像素都当成有效值去计算的,这个特性适用于分类和检测任务,但是不适用于
inpainting任务,因为inpainting任务中hole里面的像素是无效值,因此对hole里面的内容和外面的内容要加以区分,partial conv虽然将里面和外面的内容加以区分了,但是它将含有1个有效值像素的区域与含有9个有效值像素的区域同等对待,这明显是不合理的,gated conv则是使用卷积和sigmoid函数来使得网络去学习这种区分。
partial conv的不足之处:
- Partial convolution improves the quality of inpainting on irregular mask, but it still has remaining issues:
(1) It heuristically(启发式) classifies all spatial locations to be either valid or invalid. The mask in next layer will be set to ones no matter how many pixels are covered by the filter range in previous layer (for example, 1 valid pixel and 9 valid pixels are treated as same to update current mask).无论像素多少,只要存在至少一个,就将mask设置为1。(2) It is incompatible(不兼容) with additional user inputs. We aim at a user-guided image inpainting system where users can optionally(随意) provide sparse sketch(草图) inside the mask as conditional channels. In this situation, should these pixel locations be considered as valid or invalid? How to properly update the mask for next layer?(3) For partial convolution the invalid pixels will progressively disappear in deep layers, gradually converting all mask values to ones. However, our study shows that if we allow the network to learn optimal(最佳) mask automatically, the network assigns soft mask values to every spatial locations even in deep layers.(4) All channels in each layer share the same mask, which limits the flexibility. Essentially, partial convolution can be viewed as un-learnable single-channel feature hard-gating.
- Gated Convolution
- Instead of hard-gating mask updated with rules, gated convolutions learn soft mask automatically
from data. It is formulated as:
gated convolution learns a dynamic feature selection mechanism for each channel and each spatial location. Interestingly(有趣的是), visualization(可视化) of intermediate gating values(中间的gate值) show that it learns to select the feature not only according to background, mask, sketch, but also considering semantic segmentation in some channels. Even in deep layers, gated convolution learns to highlight the masked regions and sketch information in separate(单独,分开) channels to better generate inpainting results.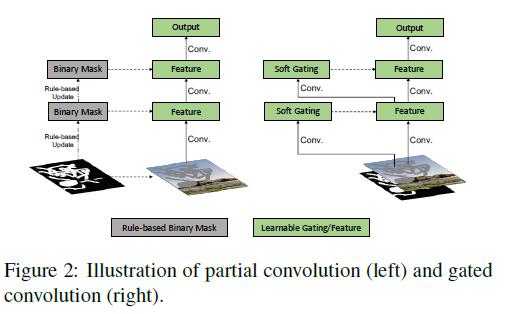
- Instead of hard-gating mask updated with rules, gated convolutions learn soft mask automatically
Spectral Normalized Markovian Discriminator (SNPatchGAN)光谱归一化马尔可夫判别器
-
之前的修复网络,为了修复带有矩形缺失部分的图片,提出了
local GAN(局部GAN)来提升实验的结果。 -
然而,我们要研究的是对任意形状的缺失的情况,借鉴
global and local GANs、MarkovianGANs、perceptual loss、spectral-normalized GANs,作者提出了一个有效的GAN loss,即为SN-PatchGAN。 -
SN-PatchGAN的组成,是由卷积网络构成,输入为image、mask、guidance channel,输出是一个形状为h×w×c的3维特征,h、w、c分别代表高、宽和通道数。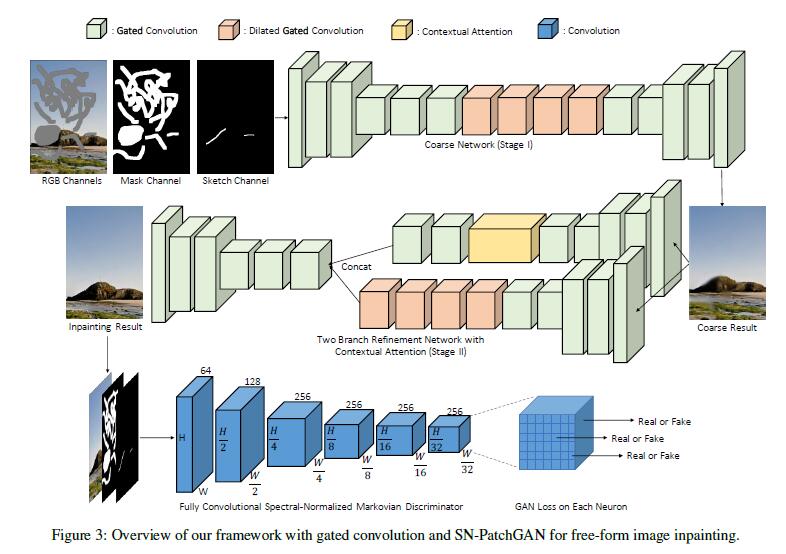 如图
如图3,6个卷积层(卷积核大小为2,步幅为2)堆叠来获得Markovian Patches特征的统计信息。然后直接将SN-PatchGAN应用到特征图的每一个特征元素,以输入图像的不同位置和不同语义(在不同的通道中表示)的形式表示GAN的h×w×c个。 -
值得注意的是,在训练的环境中,输出图中每个神经元的感受野可以覆盖整个输入图像,因此
不需要全局判别器。 -
作者也采用了最近提出的
Spectral normalization来进一步稳定GANs的训练。我们采用SN-GANs中描述的默认Spectral normalization的fast approximation算法。 -
为了判别输入的真假,作者也采用了
hings loss来作为目标函数,生成器:[L_G=-E_{z-p{z(z)}}[D^{sn}(G(z))] ]判别器:
[L_{D^{sn}}=E_{x-p{data(x)}}[RELU(1-D^{sn}(x))]+E_{z-p{z(z)}}[RELU(1+D^{sn}(G(z)))] ]其中(D^{sn})表示
spectral-normalized discriminator,(G)表示输入缺失图像(z)的图像修复网络。 -
未采用
Perceptual loss的原因是相似的patch-level information已经被编码在SN-PatchGAN中。 -
最后的目标函数:
pixel-wise ?1 reconstructionloss and SN-PatchGAN loss,权重为1:1.
Inpainting Network Architecture
- 作者定制了一个带有
Gated convolution layer和SN-PatchGan loss的generative inpainting network。 - 网络结构由粗修复和细修复两个网络构成,采用了
encoder-decoder network(PartialConv采用的是类似U-net的结构)。 - 网络为全卷积神经网络,支持不同分辨率图片的输入。训练是一个端到端的过程。
Free-Form Mask Generation
- 见论文的补充材料。
- 大致思路是:绘制一些直线和椭圆,然后通过随机的平移和旋转来模拟用户涂改图像的过程。
Extension to UserGuided Image Inpainting
- 通过草绘来做为示例指导图像修复。具体看补充材料。

Results
- 数据集:
Places2、CelebA-HQ faces - 网络参数量:
4.1M - 输入网络的图片平均大小为:
512×512。(无论缺失部分的大小为多少)
Quantitative Results
- 评估的标准是:
mean ?1 error and mean ?2 error。 - 评估的数据集是:
validation images of Places2 - 评估的种类:
both center rectangle mask and free-form mask 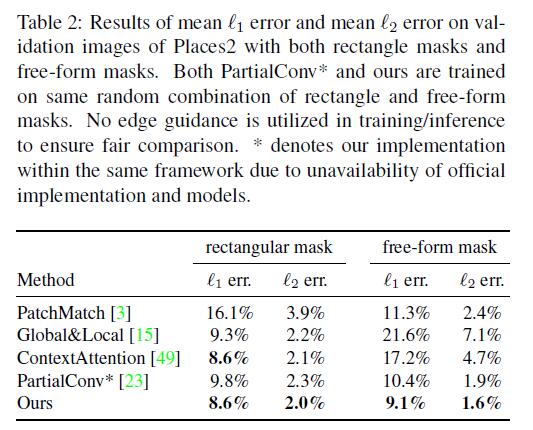
- 从图可以看出:
- 基于学习的方法要优于基于Patch-Match的方法。
- 在相同的网络结构中,
Partial Convolution得到了比较糟糕的效果,这要是因为不可学习的掩码更新规则(un-learnable rule-based gating)。
Qualitative Comparisons

Object Removal and Creative Editing
- Object Removal

- Creative Editing

Ablation Study of SNPatchGAN

- 作者证明了
SN-PatchGAN损失和逐像素?1损失的简单组合,默认损失平衡超参数为1:1,产生了逼真的修复效果。
Conclusions
- We presented a novel
free-form image inpainting systembasd on anend-to-end generative networkwithgated convolution,trained withpixel-wise ?1 lossandSN-PatchGAN. - We demonstrated that gated convolutions significantly improve inpainting results with free-form masks and user guidance input. We showed user sketch as an exemplar guidance to help users quickly remove distracting objects, modify image layouts, clear watermarks, edit faces and interactively create novel objects in photos.Quantitative results, qualitative comparisons and user studies demonstrated the superiority of our proposed free-form image inpainting system.
以上是关于Free-Form Image Inpainting with Gated Convolution的主要内容,如果未能解决你的问题,请参考以下文章