Deep Learning Local Descriptor for Image Splicing Detection and Localization阅读
Posted qina
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Deep Learning Local Descriptor for Image Splicing Detection and Localization阅读相关的知识,希望对你有一定的参考价值。
摘要 : 拼接检测方法:
提出了一个两分支CNN,分支的子网络的第一卷积层的内核是使用30种线性高通滤波器的优化组合进行初始化的 ISRM-CNN,这些滤波器用于计算空间富集模型(SRM)中的残差图 SRM-CNN,通过受约束的学习策略进行微调,以保留所学习内核的高通滤波特性 C-ISRM-CNN。利用对比损失和交叉熵损失共同提高了所提出的CNN模型的泛化能力C-ISRM_C-CNN。对于通过预训练的基于CNN的本地描述符提取的测试图像,按块方式密集特征,采用有效的特征融合策略(称为block pooling)来获得最终的鉴别特征,以用于使用SVM进行图像拼接检测。基于预训练的CNN模型,通过合并完全连接的条件随机场(CRF),进一步开发了图像拼接定位方案。
出处 IEEE Access 2020
作者 YUAN RAO , JIANGQUN NI , 中山大学
数据集 CASIA v2.0 [24]、Columbia gray DVMM [34]、DSO-1[26]:
实验环境 Caffe [38] and its Matlab interface
metrics ACC、F1 score、AUC、
Ⅲ 拼接检测网络
提出的图像拼接检测网络,如图1
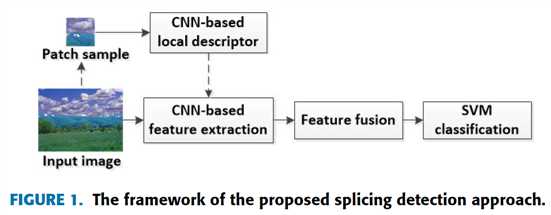
A framework of the proposed splicing detection approach
1 CNN based local descriptor construction
CNN 模型是在标记的 patch 样本上预训练的。预训练的 CNN 关注局部统计伪像特征,学习拼接 patch 的分层表示,构造有力的局部特征描述符
2 CNN-based feature extraction
把输入图像分割成 patch-size 的 block,使用局部特征描述符提取每个 block 的特征,最后的卷积层的特征图用作图像 block 的表达特征
3 feature fusion
使用 block pooling 融合一幅图像的不同 patch 的特征,得到 final discriminative feature
4 SVM classification
使用 final discriminative feature 训练 SVM 二分类器
B CNN 结构
双流 CNN 结构,如图 2
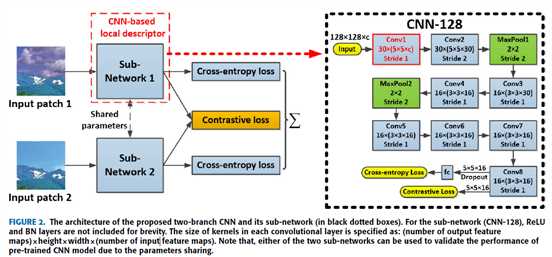
输出 feature map 的数量 × 高 × 宽 × 输入 feature map 的数量
两个子网结构相同,权重共享。提出的两分支CNN不仅采用分支内的交叉熵损失来监督训练,而且还采用跨分支上成对样本的对比损失来减少类内差异并突出类间偏差,multi-loss 提高模型泛化能力
patch size = 128×128,CNN 128 的第一层卷积层用做残差计算,还有 7 卷积层,2 最大池化,1个 FC 层和 1个 2--way softmax classifier。BN 操作可帮助通过将输入分布归一化到标准高斯函数,有助于减少内部协变量的转移。所以,每层卷积层后跟着 BN 层,然后是 RELU 函数,增加输出的稀疏性。由于只有1个 FC 层,网络表现出“轻量”结构。
CNN 模型的第一卷积层使用 SRM 初始化[7],并提出了改进的初始化策略,分别称为 SRM-CNN 和 ISRM-CNN。具有约束学习的 ISRM-CNN 称为 C_ISRM-CNN,并且在加入对比损失函数后将变为 C_ISRM_C-CNN。
C the first convolutional layer
长期以来,在现有技术[8],[9]和[22]中已经证明了基于残差的局部描述符对于图像伪造检测是有效的
1 improved initialization strategy
(W_j=[W_{j1}W_{j2}W_{j3}]), (W_j=5 imes 5) 是为30个 feature map 的每一个 map 的三通道分配的 filters,(j=1,...30)
(F=[F_1 F_2....F_{30}]) 是SRM中的30个高通滤波器
| #filters | class | Filter set |
|---|---|---|
| 8 | 1a | (F_1 - F_8) |
| 4 | 2a | (F_9 - F_{12}) |
| 8 | 3a | (F_{13} - F_{20}) |
| 4 | E3a | (F_{21} - F_{24}) |
| 4 | E5a | (F_{25} - F_{28}) |
| 1 | S3a | (F_{29}) |
| 1 | S5a | (F_{30}) |
在 [18] 中,初始化策略是按顺序重复使用滤波器核,每10个一重复。在这种情况下,内核彼此相似,如图3(a)所示,即使在网络训练期间可以对这些内核进行微调,也可能会削弱所得残留信号的多样性。且(W_{3,7,10})包括来自不同残差类的核,这难以使用CNN 建模
改进:
对于 (W_{j=1,...28})从前5个set中选
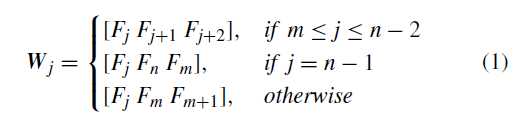
所以
(W_1=F_1 F_2 F_3)
(W_2=F_2 F_3 F_4)
(W_3=F_3 F_4 F_5)
(W_4=F_4 F_5 F_6)
(W_5=F_5 F_6F_7)
...
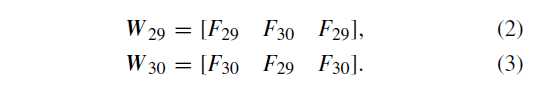

图3(a)SRM-CNN 通过[18]中的方法初始化的内核。(b)ISRM-CNN 通过改进的初始化策略初始化的内核。(c)(a)中的内核由SRM-CNN进行了微调。(d)把 b 用 C_ISRM-CNN进行微调。(c)中黄色框标记了重复的内核和非高通滤波内核。
为显示改进的策略的优越性,实验定量评估 SRM-CNN 和 ISRM-CNN 的检测表现
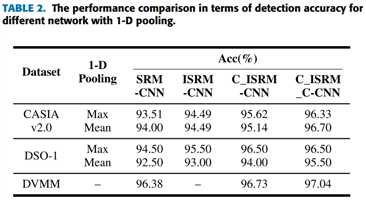
数据集:
CASIA v2.0 [24]
DSO-1 [26]
2 constrained learning strategy
常规学习算法(例如,随机梯度下降)在更新内核权重时无法确保在第一卷积层中保留卷积核的高通滤波特性。为了解决这个问题,采用约束学习策略,在权重更新中通过强制第一层中的结果内核为高通滤波
权重矩阵
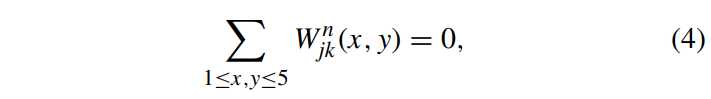
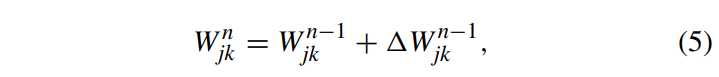
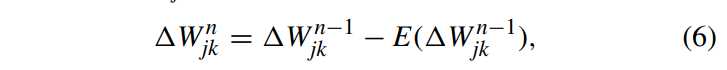
为显示约束学习策略(C_ISRM-CNN)的有效性,做实验,定量结果如上表2
DVMM 是灰度图数据集
为了展示第一卷积层在抑制图像内容干扰方面的有效性,如图4所示,图像内容(背景)被成功抑制,低级取证特征(物体边缘)被提取

D contrastive loss layer
为了降低类内差异,增加类间偏差,采用 contrastive loss[35]
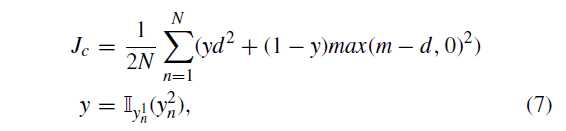
N 是输入对的 batch size .d是两特征向量的l2距离,指标函数$Ⅱ_i(x)= 0,x eq i $ $Ⅱ_i(x)= 1,x=i $
contrastive loss 趋向于最小化来自同一类的两个特征向量的 L2 范数,它要求来自不同类别的两个特征向量的 L2 距离为大于预定义的边距 m
用两个目标函数,即对比损失和交叉熵损失,对两分支CNN进行训练,以最小化这两个由超参数 λ 加权的监督损失函数的总和,公式8
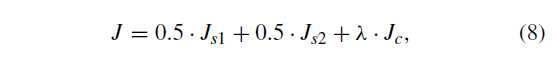
做实验
提取的400-D特征投影到2-D空间进行可视化
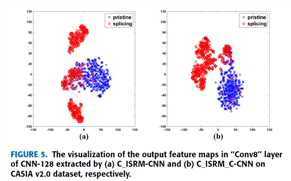
b图的类内距离显显著减小,而类间变化则增大。使提取的特征容易线性地分离,这有助于提高后续SVM分类器的分类精度。定量结果见表2
E feature extraction and feature fusion
如图6,生成特征向量主要包括3步
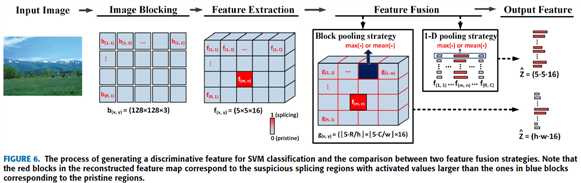
1 image blocking
输入图像 I 为 H x W,分为 R x C 个不重叠的 blocks ,每个 block
记作 b(x,y) , (1 leq x leq R) , (1 leq y leq C)
2 feature extraction
使用预训练的 C_ISRM_C-CNN 提取 RGB 图像特征 ,f (x, y) = Conv(b(x, y)),f (x, y) = 5x5x16,然后集成为 (hat{F}=5R imes 5C imes 16)
3 feature fusion
再次把 (5R imes 5C) 划分为 (h imes w) 个 blocks g(x,y),再把每个 block pooling
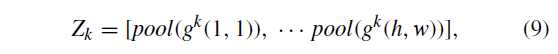
拼接得到(hat{Z})
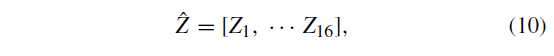
得到 (h imes w imes 16) 维的特征。请注意,在我们的实现中,我们对各种大小的特征图像进行了固定的h × w网格生成,从而导致无论特征图像大小如何,都产生了固定数量(即h · w)的块,从而保持了最终特征向量的维数,称为 h × *w block pooling。
如果 b(x,y) 块被误分类成 forged,(什么时候分类了?)那么在 f(x,y) 中,f(m,n) 会变成最主要的特征向量,并且很快扩散到所有维度。而块池化只会影响两个维度。所以块池化在原始图像检测中趋于更健壮,尤其是在JPEG压缩的情况下
Ⅳ 拼接定位部分
A CNN-based sliding window localization
测试图像的预测标签 L
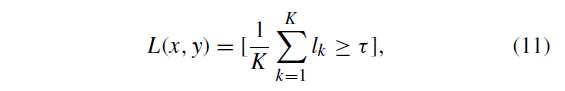
[P] 是 Iverson bracket ,满足条件为1,不满足为0。k 是 block 的数量,(l_k) 是k block 的篡改概率,( au)是阈值,从训练数据中得到最大值
滑动窗口大小为 (p imes p),(K=(p/s)^2), 而对于图像边界附近的L(x ,y),K较小。然后进行形态学操作,例如扩张和腐蚀,以擦除微小的孤立区域并填充孔。根据[32],在篡改定位方面,生成的二进制图不如连续可能性图可靠,然后我们进一步应用具有64 × 64 窗口大小的均值滤波来平滑预测的标签图L,生成拼接可能性图 (L^{MF})
B refining by fully connected CRF
尽管均值滤波消除了滑动窗口产生的马赛克假象,但仍可以微调。使用CRF,用细粒度的预测标签图恢复拼接边缘
(l_i) 做像素 i 的标签,基于 mean field approximation 最小化能量函数来做像素级标记
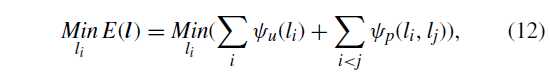
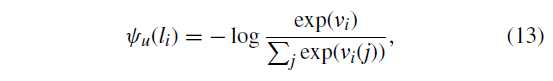
(psi_u(l_i)) 是基于分类器的类分数的数据项,是根据类条件概率计算的
(psi_p(l_i,l_j)) 是基于像素的局部相互作用的平滑项
(v_i)是像素i的2D特征向量,(v_i=[L^{MF}(x,y),1-L^{MF}(x,y)])
$psi_p(l_i,j_i)=mu (l_i,l_j)k(f_i,f_j) $ , 标签兼容函数 $mu (l_i,l_j)=1-Ⅱ_{l_i}(l_j) $是对不同标签的相似像素的惩罚
高斯核 k(fi,fj) 取决于提取的特征f 的像素i和j的位置和强度,由双边滤波核(由w1加权)和空间核(由w2加权)的线性组合定义
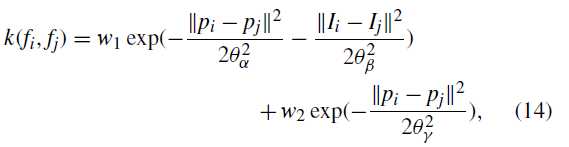
注意,我们发现基于广泛实验的CRF训练不会使定位性能显着提高,这主要是由于仅从2-D特征向量计算出一元势。
只在优化定位结果时在[36]的默认设置中采用CRF
Ⅴ 实验
A database
CASIA v2.0 [24]:包含7,491个真实图像和5,123个伪造(拼接和复制移动)彩色图像,尺寸范围为240 × 160至900 × 600 JPEG和TIFF格式
Columbia gray DVMM [34]:由933个真实图像和912个BMP格式的拼接图像组成,大小均为128 × 128像素,没有任何后处理.
DSO-1[26]:由100个具有像素方向真实情况的拼接图像和100个原始图像组成,分辨率为2,048 × 1,536像素。
将具有固定步幅的补丁大小的滑动窗口应用于沿拼接边界提取补丁。对于负样本,我们从真实图像中随机抽取相等数量的色块。
B implementaion
所提出的CNN模型(用于局部特征提取)的训练是使用Caffe [38]及其Matlab接口实现的
C splicing detection performance
metrics :ACC 、ROC、AUC
根据以下两种类型的设置进行实验:
设置1:在压缩后的图像上测试拼接检测性能,同时在未压缩的图像上训练基于 CNN 的局部描述符和 SVM 模型。
设置2:除了基于 CNN 的局部描述符和 SVM 分类模型都在压缩数据集上训练之外,所有实验设置均与设置1相同。
1 comparison with CNN based detector with 1-D pooling for setting #1
在设置1上实验:
特征融合的对比方法:
[18] the CNN based detector (with 1-D pooling)
表 3 是定量对比结果
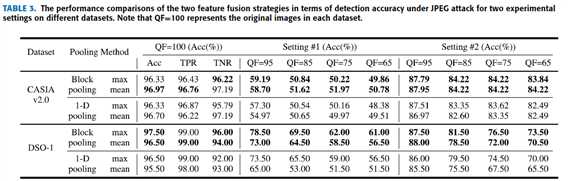
2 comparison with CNN based detector with 1-D pooling for setting #2
在设置2上实验:
表3是定量对比结果
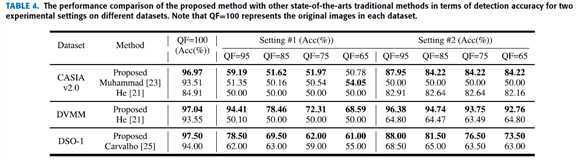
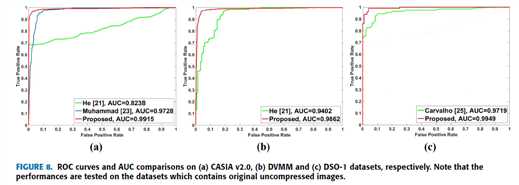
3 comparison with other state-of-the-art splicing detection methods
对比方法:
手工特征方法:
He [21]-2012
Muhammad [23]-2014
Carvalho [25]-2016
分别是在CASIA v2.0, DVMM and DSO-1 datasets表现最好的方法
定量对比如表4
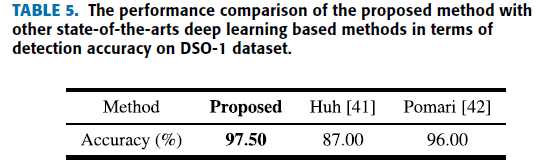
4 comparison with other state-of-the-art deep learning splicing detection methods
对比方法:
Huh [41]-2018
Pomari [42]-2018
在 DSO-1 dataset
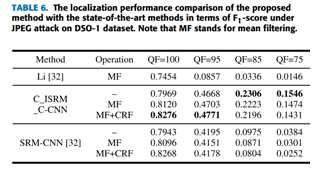
D splicing localization performance
metric :F1 score
1 comparision between CNN based methids
2 comparision with other SOA splicing localization method
对比方法:
Li [32]
表6是定量分析结果
图9是定性分析结果
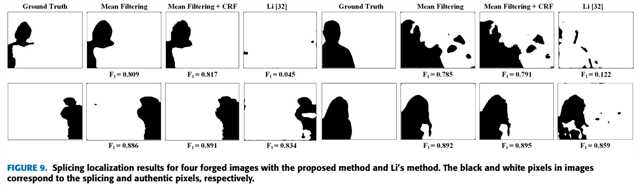
proposed 方法比 Li 好,proposed 方法加了 CRF 具有优化效果
3 comparision with SOA deep learning based splicing localization method
对比方法:
Shi [40]-2018
Huh [41]-2018
Salloum [43]-2018
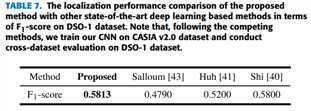
在 CASIA v2.0 dataset 训练,在 DSO-1 dataset 测试定位表现
以上是关于Deep Learning Local Descriptor for Image Splicing Detection and Localization阅读的主要内容,如果未能解决你的问题,请参考以下文章
Deep Learning(深度学习)之Deep Learning学习资源
Deep Learning(深度学习)之Deep Learning的基本思想
Deep Learning(深度学习)之Deep Learning的常用模型或者方法