python3 爬虫小技巧,
Posted shaosks
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python3 爬虫小技巧,相关的知识,希望对你有一定的参考价值。
前几天采集一个网站的数据,发现在翻页查询数据的时候,网址是不变的,其实这样的情况很多,关键是获取到真正的URL
比如:查询链接是:http://so.nen.com.cn/m_fullsearch/searchurl/mfullsearch!descResult.do 翻页r查询,地址栏里面的url始终是不变的,但实际上是变化的,
具体的参数变化可以在From Data看到,如下图: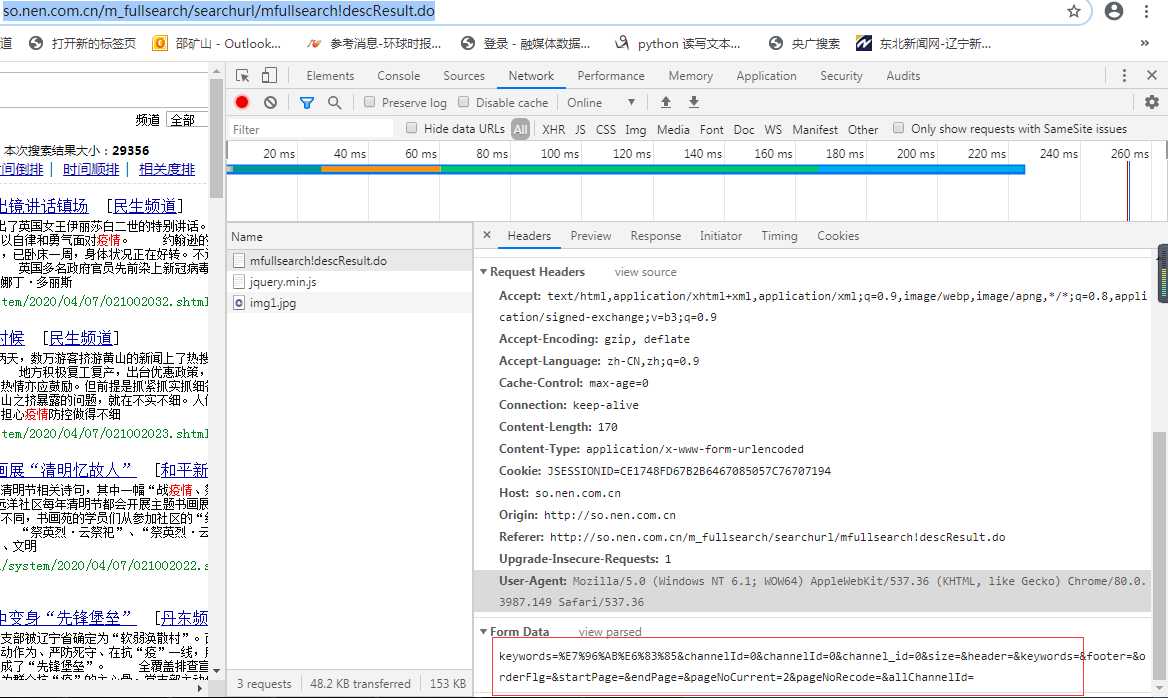
所以具体的完整的url应该是:http://so.nen.com.cn/m_fullsearch/searchurl/mfullsearch!descResult.do?keywords=%E7%96%AB%E6%83%85&channelId=0&channelId=0&channel_id=0&size=&header=&keywords=&footer=&orderFlg=&startPage=&endPage=&pageNoCurrent=2&pageNoRecode=&allChannelId=
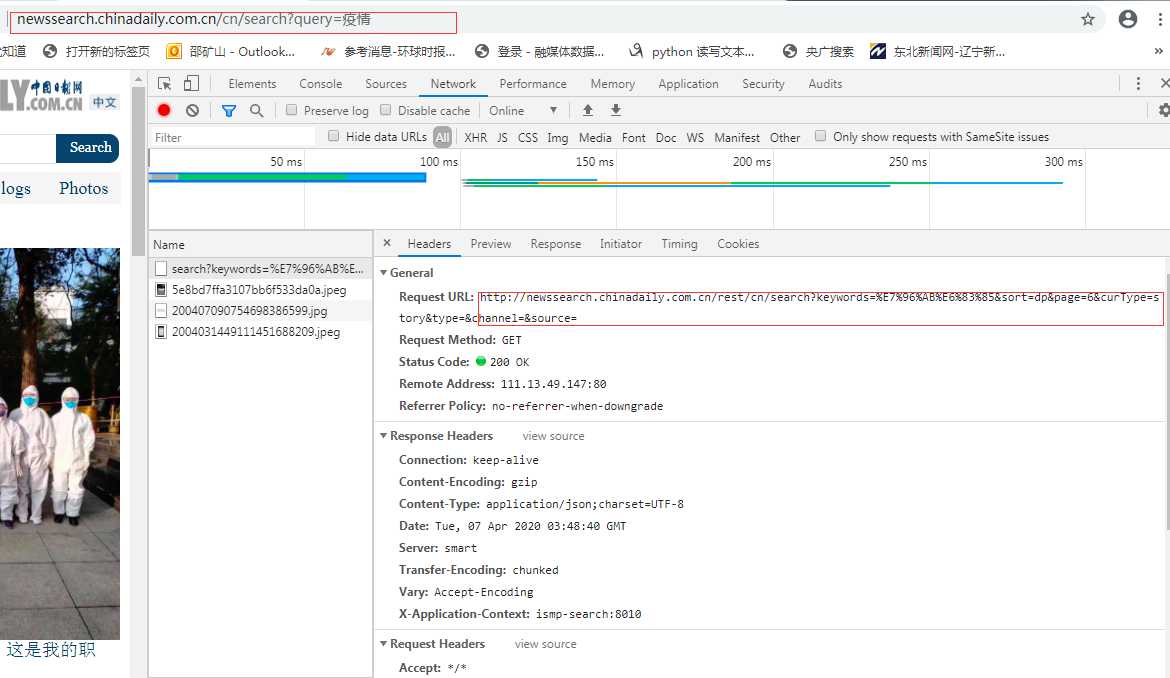
不过有的参数在 Query String 里面,不同的网站可能不一样,只有F12查看一下就可以
12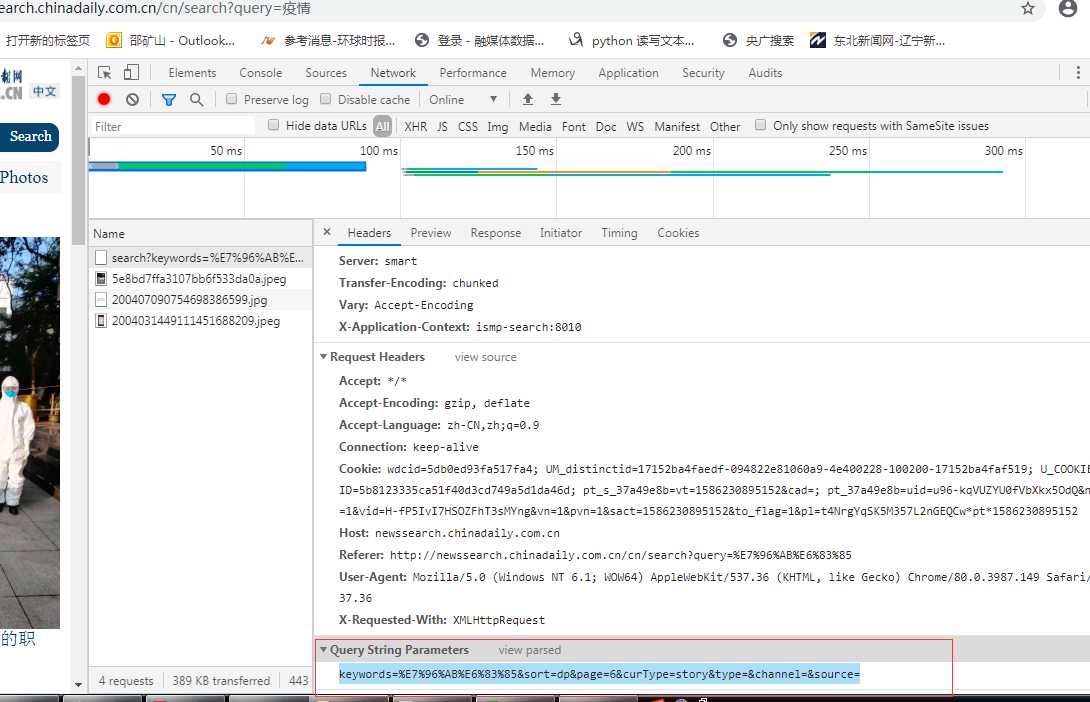
以上是关于python3 爬虫小技巧,的主要内容,如果未能解决你的问题,请参考以下文章