从零开始写处理器——cache原理与实现
Posted aagnosticengineer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零开始写处理器——cache原理与实现相关的知识,希望对你有一定的参考价值。
1.局部性与命中率
对于cache而言,其本质就是在高速寄存器与低速DRAM之间寻找一个平衡,拥有较大的存储空间与较快的速度,一般利用SRAM实现。为了实现高速的目的,我们希望cache中存储的数据可以包括一切cpu中需要用到的数据,从而避免重新回到DRAM导入数据,但cache的存储空间毕竟较小无法把所有DRAM数据导入,因此需要一些特定读入数据的机制,让cache有更大几率猜到程序需要什么数据并读入这些数据,这就需要两种局部性:空间局部性(spatial locality)和时间局部性(temporal locality)。
空间局部性指取到某一地址后,有很大可能其周边地址接下来也会被取到,如取数组中的数据、结构体中的数据;或是取指令时,由于很多指令都是顺序指令,因此下一条指令大概率在物理空间上与上一条指令相邻。
时间局部性指取到某地址后,可能在接下来时间里还会用到这个地址,如在loop程序中指令与数据会不停的被取用。
这两个局部性可以帮助cache有更大可能性猜到程序需要的数据与指令,若猜中记为hit,没猜中记为miss,#hit/#total为命中率,这与cache的性能密切相关。若hit则可以继续运行处理器,若miss则需要暂停处理器N个周期等待数据从RAM中读入并复制进入cache。
2.Direct-mapped(图源https://courses.cs.washington.edu/courses/cse378/09au/lectures/)
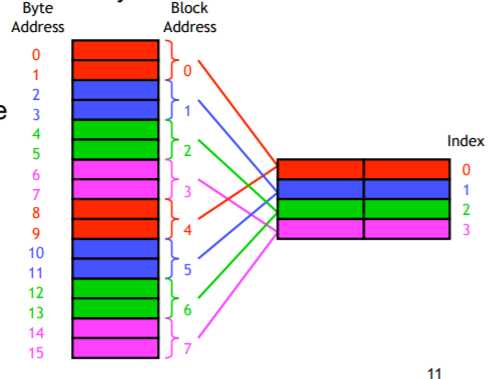
如上图所示,左侧为RAM,右侧为cache。Direct-mapped方法将RAM中的地址按块分割,每个地址有其相对应的cache内存储位置,图中即为同种颜色相对应,若需要地址0中的数据则录入0与1组成的块,若需要1也录入这个块,从而应用到了空间局部性。导入cache中的数据在一段时间内保持在cache中为时间局部性。这种方式构成的cache结构如下
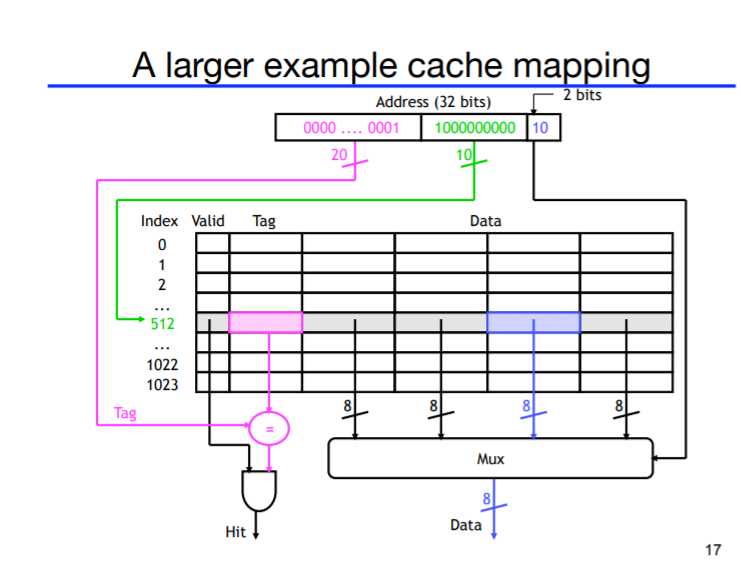
上图为每4个地址为一个块,当需要某一个地址时会将块中的4个地址都导入cache中。Valid位类似enable,初始状态为0,当数据准备好时变成1;Index对应一个cacheline,由于一个index会对应RAM中不止一个地址,因此我们利用高位数据,保存在Tag中加以区分;Offset位为区分取用这条cacheline中的哪一个数据。总的来说,{Tag,Index,Offset}=AddrInRAM。
然而direct-mapped的方式的缺点在于,如果cacheline有四条,而我们总是读取RAM中addr=2与6的数据,由于这两个数据都会被保存在cache中Index=1的位置上,这个位置会不停地写addr=2和6的数据,而其他位置根本用不到,造成cache的浪费。
3.Set-associative cache
针对上述缺点,我们将cache分成多个set,每个set中存在2^s个cacheline,我们称之为s-way associativity,每个set都有自己的index,取代direct-mapped中的index,因此有相同index的数据可以存在同一个set中,如一个set中有两条cacheline,则RAM中addr=2与6的数据都可以存放近同一个set中,由tag区分。若只有一个set,index就失去作用了,数据的区分完全由tag决定,我们称为fully associative cache。
总结来说associative cache就是通过将index可以支配的bit数减少,以换取更有效的存储。2-way associative cache连接如下图所示:
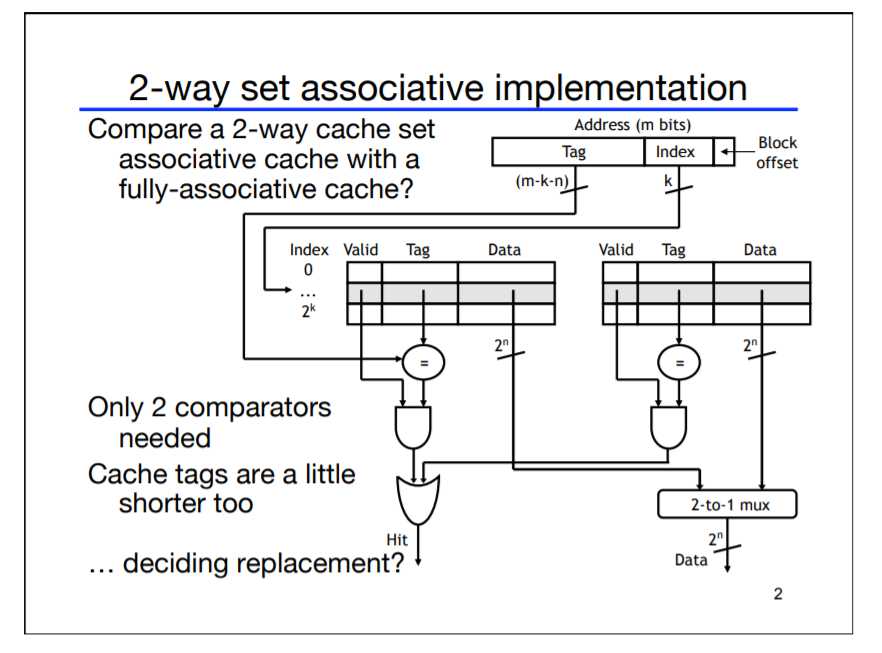
对于RAM而言,更大的块可以更好展现空间局部性的优势,对于cache而言,增加更多的associativity可以避免冲突,但都会增加硬件负担。实践表明,2-way到16-way是最平衡的几种cache。
4.写cache
前三节主要说了cache的读机制。对于从主存储中写cache,首先要解决是替换哪一个数据的问题,我们这里用到LRU(least recent used)标记每个set中的哪一条cacheline是最少被用到,读set中的数据与写入set数据都会更新该标志位。
再一个就是从cpu中写,由于cpu写回(或主存储被io共同使用),这可能会导致主存储该地址的值发生变更,因此cache与主存储中指向相同的地址但存储了不同的数据。
针对这一点有两种cache可以选择,Write-through caches与Write-back caches,前者在cache内值出现改变时会将数据同时导入cache与主存储(在高速的cpu和低速的主存储加入buffer),这种方法会占用很多存储带宽,同时若有很多sw命令则需要不停写主存储;后者则在cacheline中加入一位dirty bit,当cache中数据被cpu改写时,dirty bit置1,当这个地址被替换时回写到主存储中。
最后一个问题是如果出现写入一个新地址时要怎么办,Write around caches策略为直接写入主存储,Allocate on write则会写入cache,以便于后续调用。
**其他:虚拟内存与物理内存:https://www.jianshu.com/p/b6356e0ec63c;分段与分页:https://blog.csdn.net/qq_37924084/article/details/78360003
以上是关于从零开始写处理器——cache原理与实现的主要内容,如果未能解决你的问题,请参考以下文章