Django查询集QuerySet及两大特性
Posted zhougreat
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Django查询集QuerySet及两大特性相关的知识,希望对你有一定的参考价值。
1 概念
Django的ORM中存在查询集的概念。
查询集,也称查询结果集、QuerySet,表示从数据库中获取的对象集合。
当调用如下过滤器方法时,Django会返回查询集(而不是简单的列表):
-
- all():返回所有数据。
- filter():返回满足条件的数据。
- exclude():返回满足条件之外的数据。
- order_by():对结果进行排序。
也就意味着查询集可以含有零个、一个或多个过滤器。过滤器基于所给的参数限制查询的结果。
从SQL的角度讲,查询集与select语句等价,过滤器像where、limit、order by子句。
判断某一个查询集中是否有数据:
-
- exists():判断查询集中是否有数据,如果有则返回True,没有则返回False。
两大特性
一、惰性执行
创建查询集不会访问数据库,直到调用数据时,才会访问数据库,调用数据的情况包括迭代、序列化、与if合用
例如,当执行如下语句时,并未进行数据库查询,只是创建了一个查询集Tooks
tooks= Tooks.objects.all()
继续执行遍历迭代操作后,才真正的进行了数据库的查询
for took in tooks: print(took.name)
二、缓存
使用同一个查询集,第一次使用时会发生数据库的查询,然后Django会把结果缓存下来,再次使用这个查询集时会使用缓存的数据,减少了数据库的查询次数。
情况一:如下是两个查询集,无法重用缓存,每次查询都会与数据库进行一次交互,增加了数据库的负载。
from book.models import BookInfo [book.id for book in BookInfo.objects.all()] [book.id for book in BookInfo.objects.all()]


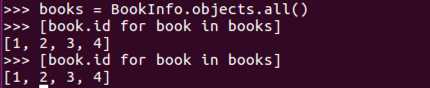
情况二:经过存储后,可以重用查询集,第二次使用缓存中的数据。
books=BookInfo.objects.all() [book.id for book in books] [book.id for book in books]



以上是关于Django查询集QuerySet及两大特性的主要内容,如果未能解决你的问题,请参考以下文章