2.5D Visual Sound:CVPR2019论文解析
Posted wujianming-110117
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2.5D Visual Sound:CVPR2019论文解析相关的知识,希望对你有一定的参考价值。
2.5D Visual Sound:CVPR2019论文解析

论文链接:
http://openaccess.thecvf.com/content_CVPR_2019/papers/Gao_2.5D_Visual_Sound_CVPR_2019_paper.pdf
Video results: http://vision.cs. utexas.edu/projects/2.5D_visual_sound/
摘要
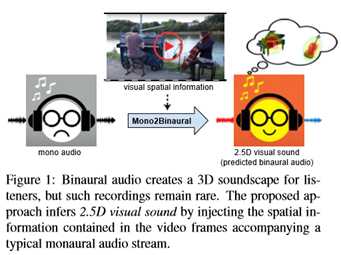
双耳音频为听者提供了3D的声音感受,使其对场景有丰富的感知体验。然而,双耳录音几乎不可用,需要非平凡的专业知识和设备才能获得。本文建议利用视频将普通的单耳音频转换为双耳音频。关键的想法是,视觉框架揭示了重要的空间线索,虽然明显缺乏相应的单声道音频,但与之紧密相连。本文的多模式方法从未标记的视频中恢复此链接。本文设计了一个深卷积神经网络,通过注入有关物体和场景配置的视觉信息,学习将单声道(单声道)原声解码成双耳原声。本文称之为输出2.5D视觉声音视觉流有助于“提升”单声道音频到空间化的声音。除了声音生成之外,本文还展示了通过本文的网络学习到的自监督表示,这有利于音像源分离。
1. Introduction
本文的主要贡献有三方面:
首先,本文提出利用视频帧将单声道音频转换为双声道音频,并设计了一个单声道深度网络来实现这一目标;
其次,本文收集了FAIRPlay,一个5.2小时的视频数据集,其中第一个是双耳音频数据集,以促进音频和视觉社区的研究;
第三,本文提出对预测出的双耳音频进行视听源分离,并证明它为分离任务提供了一种有用的自监督表示。本文在四个具有挑战性的数据集上验证了本文的方法,这些数据集涵盖了各种声源(如乐器、街景、旅行、运动)。
2. Related Work
从视频生成声音
最近的工作探索了如何产生音频条件下的“无声”视频。材料属性是由物体被鼓槌击打时发出的声音揭示出来的,可以用来合成无声视频中的新声音[32]。递归网络[53]或条件生成对抗网络[7]可以为输入视频帧生成音频,而强大的模拟器可以为3D形状合成视听数据[51]。本文的任务不是从头生成音频,而是将输入的单声道音频转换为由视频帧引导的双声道双耳音频。
只有有限的先前工作考虑基于视频的音频空间化[26,28]。[26]系统将房间内扬声器发出的声音作为视角的函数进行合成,但假设可以访问特定房间内记录的声音脉冲,这限制了实际使用,例如,对于新颖的“现成”视频。本文[28]的并行工作产生了360度视频和单声道音频的氛围(全视域音频)。相比之下,本文关注的是普通视场(NFOV)视频和双耳音频。本文表明,直接预测双耳音频可以为听众创造更好的3D声音感受,而不局限于360度视频。此外,虽然[28]的最终目标是音频空间化,但本文也证明本文的单声道转换过程有助于视听源分离。
声(视)源分离
纯音频源分离在信号处理文献中得到了广泛的研究。“盲”分离解决了只有一个通道可用的情况[42,43,46,19]。当使用多个麦克风[29、49、9]或双耳音频[48、8、50]观察到多个通道时,分离变得更容易。受此启发,本文通过观察视频将单声道转换为双耳,然后利用得到的表示改进视听分离。
视听源分离也有着丰富的历史,其方法包括探索互信息[11]、子空间分析[41,35]、矩阵分解[34,39,13]和相关集合[6,25]。
最近的方法利用深度学习来分离语音[10,31,1,12],乐器[52]和其他物体[13]。新的任务也正在出现,例如学习分离屏幕上和屏幕外的声音[31]、从未标记的视频中学习对象声音模型[13]或预测每像素的声音[52]。所有这些方法都利用单声道音频信号来进行视听信号源分离,而本文建议预测双耳信号来增强分离。此外,与定位负责给定声音的像素的任务[21、18、54、3、52、40、44]不同,本文的目标是执行双耳音频合成。 自监督学习
自监督学习利用数据结构中可自由获取的标签,而视听数据提供了大量这样的任务。最近的研究探索了视觉[33,2]和听觉[4]的自我监督特征学习、跨模态表征[5]和视听对齐[31,23,16]。本文的单声道公式也是自监督的,但与上述任何一种不同的是,本文使用视觉框架来监督音频空间化,同时也学习更好的声音表示以实现视听源分离。
3. Approach
本文的方法学习通过视频将单耳音频映射到双耳音频。在下面,本文首先描述本文的双耳音频视频数据集(Sec3.1)。然后本文提出本文的单基础公式(Sec3.2),以及解决问题的网络和培训程序(Sec3.3)。最后,本文介绍了本文的方法,利用推断的双耳声音来执行视听源分离(Sec3.4)。
3.1. FAIR-Play Data Collection
训练本文的方法需要双耳音频和伴奏视频。由于没有大型公共视频数据集包含双耳音频,本文收集了一个新的数据集,本文称之为公平播放与自定义钻机。如图2所示,本文组装了一个设备,包括一个3Dio自由空间卡侬双耳麦克风、一个GoPro HERO6黑色摄像头和一个Tascam DR60D录音机,作为音频前置放大器。本文将GoPro相机安装在3Dio双耳麦克风的顶部,分别模拟人的视觉和听觉。
3Dio双耳麦克风可录制双耳音频,GoPro相机可录制30帧/秒的立体声视频。本文同时从两个设备记录,这样流就大致对齐了。请注意,麦克风的耳形外壳(耳钉)及其空间分离都非常重要;专业的双耳麦克风(如3Dio)模拟了人类接收声音的物理方式。相比之下,立体声是由两个麦克风捕捉到的,它们的任意间隔在不同的捕捉设备(手机、相机)中有所不同,因此缺少双耳的空间细微差别。然而,双耳捕获的局限性在于,单个设备固有地具有与头部相关的单一传递功能,而个体由于人与人之间的解剖差异而有微小的差异。
个人化头部相关的转移功能是一个活跃的研究领域[20,45]。本文在一个大音乐室(约1000平方英尺)用本文的定制设备拍摄视频。本文的目的是在不同的空间环境中,通过组合不同的乐器和室内人员,捕捉各种发声对象。房间里有各种乐器,包括大提琴、吉他、鼓、四弦琴、竖琴、钢琴、小号、竖琴和班卓琴。本文招募了20名志愿者,让他们在独唱、二重唱和多人游戏中表演并录音。
本文把原始数据后处理成10秒的片段。最后,本文的公平播放数据集包含1871个音乐表演短片,总共5.2小时。在实验中,本文同时使用音乐数据和环境声学数据集[28],用于街景和YouTube上的体育、旅游等视频(参见Sec4) 是的。

3.2. Mono2Binaural Formulation
双耳信号让本文推断出声源的位置。耳间时差(ITD)和耳间水平差(ILD)起着至关重要的作用。它是由两个耳朵之间的旅行距离不同引起的。当一个声源靠近一只耳朵而不是另一只耳朵时,信号到达两只耳朵之间会有一个时间延迟。ILD是由“阴影”效应引起的——相对于某些波长的声音,听者的头部很大,因此它起到屏障的作用,形成阴影。头部、耳廓和躯干的特殊形状也可以根据声源的位置(距离、方位角和海拔)作为过滤器。所有这些线索在单声道音频中都是缺失的,因此本文不能通过听单声道音频来感知任何空间效果。
3.3. Audio-Visual Source Separation
在测试时,网络呈现单声道音频和视频帧,并推断出双耳输出,即2.5D可视声音。为了处理完整的视频流,每个视频被分解成许多短音频段。在这样短的视频段内,视频帧通常变化不大。本文使用滑动窗口以较小的跳数分段执行空间化,并对重叠部分进行平均预测。因此,本文的方法能够处理移动的声源和摄像机。本文的方法期望在训练和测试之间有一个相似的视野(FoV),并且假设麦克风靠近摄像机。本文的实验表明,本文可以学习正常视场和360°视频的mono2基础,而且同样的系统可以处理来自可变硬件(如YouTube视频)的mono输入。
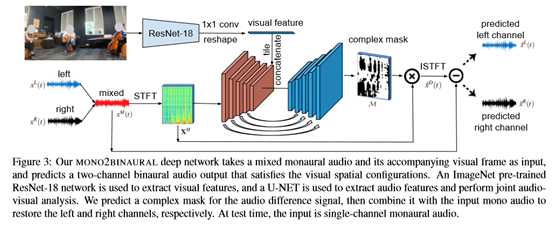
3.4. Audio-Visual Source Separation
干扰声源通常位于物理空间的不同空间位置。人类听者利用双耳协调的空间信息来解决多声源引起的声音模糊问题。这种能力在只有一只耳朵的情况下会大大减弱,尤其是在混响的环境中[22]。机器侦听器的音频源分离也有类似的缺陷,通常无法访问双耳音频[52、13、31、10]。
然而,本文假设本文的单声道预测双耳音频可以帮助分离。直观地说,通过强迫网络学习如何将单声道音频提升到双耳,它的表现形式被鼓励暴露对源分离非常有价值的空间线索。因此,尽管单声道特征与任何其他视听分离方法看到的视频相同,但由于它们的二值化“预训练”任务,它们可能更好地解码潜在的空间线索。 特别是,本文预计有两个主要影响。
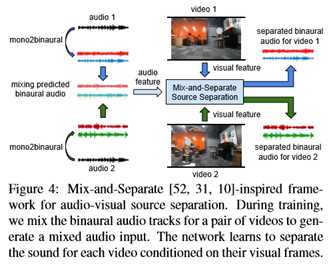
首先,双耳音频嵌入了有关声源空间分布的信息,可以作为分离的正则化器。 其次,在声源具有相似声学特性的情况下,双耳提示可能特别有用,因为空间组织可以减少声源的模糊性。在其他视觉任务中观察到相关的正则化效应。例如,幻觉运动增强静态图像动作识别[14],或预测语义分割通知深度估计[27]。 为了实现音视频源分离的实验平台,本文采用了混合分离的思想[52,31,10]。本文使用的基本架构与本文的Mono2基础网络相同,只是现在网络的输入是一对训练视频剪辑。
图4示出了分离框架。本文将预测到的两个视频的双耳音频的声音混合起来,生成一个复杂的音频输入信号,学习的目标是根据每个视频对应的视频帧分离出它们的双耳音频。在[52]之后,本文只使用谱图幅度和预测用于分离的比率掩模。每像素L1损失用于训练。详见附件。
4. Experiments
4.1. Datasets
本文使用四个具有挑战性的数据集,涵盖各种各样的声音源,包括乐器、街景、旅游和运动。
公平竞争
本文的新数据集由187110个在音乐室录制的视频片段组成(图2)。视频与专业双耳麦克风录制的高品质双耳音频配对。本文通过将数据分别分成1497/187/187个片段的train/val/test片段来创建10个随机片段。
娱乐街
[28]使用带有TA-1空间音频麦克风的θV 360°摄像机收集的数据集。它包含43个户外街景视频(3.5小时)。
YT-清洁
这个数据集包含来自YouTube的360°视频,这些视频由[28]使用与空间音频相关的查询进行爬网。它由496个视频组成,其中包含少量的超级来源,如人们在会议室交谈、户外运动等。
YT-音乐
由[28]收集的397个YouTube音乐表演视频组成的数据集。这是他们最具挑战性的数据集,因为大量的混合来源(声音和乐器)。
据本文所知,公平播放是第一个包含专业录制的双耳音频视频的此类数据集。对于REC-STREET、YT-CLEAN和YT-MUSIC,本文将视频分成10个片段,并根据提供的片段1将它们分成train/val/test片段。
这些数据集只包含双声道,因此本文使用双耳解码器将它们转换为双耳音频。具体来说,本文使用ARI HRTF数据集中NH2受试者的头部相关传递函数(HRTF)来执行解码。对于本文的公平播放数据集,一半的训练数据用于训练单声道网络,另一半则用于音像源分离实验。
4.2. Implementation Details
结果
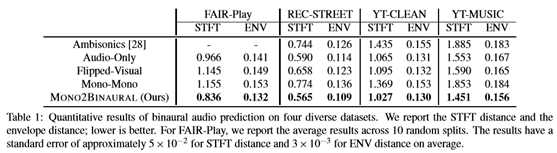
表1显示了双耳产生的结果。本文的方法在所有四个数据集上都一致地优于所有基线。本文的Mono2Bunural方法比仅音频的基线性能更好,这表明视觉流对于引导转换至关重要。注意,AudioOnly基线使用与本文的方法相同的网络设计,因此它具有相当好的性能。然而,本文发现当物体不简单地位于中心时,本文的方法比它表现得更好。翻转的视觉效果差得多,这表明本文的网络能够正确地学习定位声源,从而正确地预测双耳音频。环境声学的方法并没有那么好。本文假设了几个原因。该方法直接预测四通道环境音,必须转换成双耳音频。
尽管环境声学的优点是更通用的音频表示,非常适合360度视频,但首先预测环境声学,然后解码到双耳音频以进行部署,可能会引入使双耳音频不太逼真的伪影。更好的头部相关传递函数有助于从环境声学中呈现更真实的双耳音频,但这仍然是一项活跃的研究[30,24]。本文的方法直接根据听者最终听到的双声道双耳音频来描述音频空间化问题,从而获得更好的准确性。本文的视频结果4显示了包括失败案例在内的定性结果。当存在多个外观相似的对象时,本文的系统可能会失败,例如多个人类扬声器。本文的模型错误地将音频空间化,因为人们在视觉上太相似了。然而,当其他声音中只有一个人类扬声器时,它可以成功地执行音频空间化。未来结合运动的研究可能有助于实例级的空间化。
用户研究
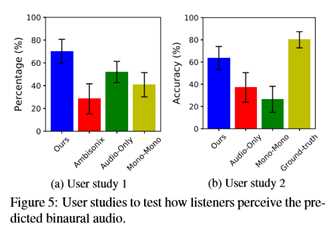
在表1中量化了本文方法的优势之后,本文现在报告真实的用户研究。为了测试预测的双耳音频如何让听者感觉到3D的感觉,本文进行了两项用户研究。对于第一个研究,参与者听一个10秒的地真双耳音频和看到的视觉框架。然后他们听由本文的方法产生的两个预测的双耳音频和一个基线(双声道、仅音频或单声道)。在听了每一对之后,参与者被问到哪一对创造了一个更好的3D感觉,与地面真实的双耳音频相匹配。本文招募了18名听力正常的参与者。每个人听45对跨越所有数据集的录音。图5a示出了结果。本文报告每种方法被选为首选方法的次数百分比。本文可以看到,由本文的方法产生的双耳音频创造了更真实的三维感觉。
对于第二个用户研究,本文要求参与者说出他们听到特定声音的方向。使用公平播放数据,本文随机选择10个乐器视频剪辑,其中一些播放器位于视频帧的左/中/右。本文要求每一位参与者只听地面的真实情况或从本文的方法或基线预测的双耳音频,然后选择特定乐器的声音来自的方向。注意,在本研究中,本文输入GoPro麦克风录制的真实单声道音频,用于双耳音频预测。图5b示出了18名参与者的结果。真正录制的双耳音频质量很高,听众通常可以很容易地感知到正确的方向。然而,本文预测的双耳音频也清楚地传达了方向性。与基线相比,本文的方法为听众提供了更精确的空间音频体验。
4.3. Mono2Binaural Generation Accuracy
本文使用共同的指标和两个用户研究来评估本文预测的双耳音频的质量。本文比较以下基线:
•环境声学[28]:
本文使用[28]提供的预先训练的模型来预测环境声学。模型是在与本文的方法相同的数据上训练的。然后,本文使用双耳解码器将预测的双声道音频转换为双耳音频。此基线不适用于双耳音乐室数据集。
•仅音频:
为了确定视觉信息是否是执行单声道转换所必需的,本文移除视觉流并仅使用音频作为输入来实现基线。所有其他设置都是相同的,除了只有音频特性被传递到上卷积层用于双耳音频预测。
•翻转视觉:
在测试过程中,本文使用错误的视觉信息来显示单声道音频的伴随视觉帧以执行预测。
•单声道:
一个简单的基线,将混合的单声道音频复制到两个声道上,以创建一个假双耳音频。

4.4. Localizing the Sound Sources
在执行二进制化时,网络是否注意到声源的位置?作为本文Mono2基础训练的副产品,本文可以使用网络进行声源定位。本文使用32×32的掩模来代替图像的平均值区域,并通过网络转发掩模帧来预测双耳音频。然后本文计算损失,并通过在帧的不同位置放置遮罩来重复。最后,本文强调了当被替换时,导致最大损失的区域。它们被认为是最重要的单声道转换区域,预计将与声源对齐。
图6示出了示例。突出显示的关键区域与声源有很好的相关性。它们通常是在音乐室里演奏的乐器,在街景中移动的汽车,正在进行活动的地方等等。最后一排显示了一些失败的案例。当视图中有多个相似的仪器,或是无声或嘈杂的场景时,模型可能会被混淆。YT Clean和YT音乐中的声源由于多种和/或大量的声源,特别难以实现空间化和本地化。
4.5. Audio-Visual Source Separation
在演示了本文预测的双耳音频可以产生更好的三维感觉之后,本文现在使用公平播放数据集来研究它对视听源分离的影响。数据集包含不同发声对象(乐器)的对象级声音,非常适合本文采用的混合和分离的视听源分离方法。本文对公平竞争的延迟数据进行训练,并对来自val/测试集的10个典型单乐器视频片段进行测试,每个片段代表本文数据集中的一个独特的乐器。本文配对混合每个视频剪辑并执行分离,总共45个测试视频。
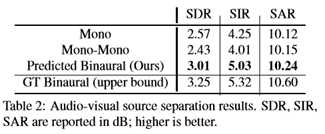
除了上面定义的地面真值双耳(上限)和单声道基线外,本文还将其与以单声道音频为输入并为每个源分离单声道音频的单声道基线进行比较。Mono表示仅使用单声道音频执行视听源分离的当前规范[52、13、31]。本文强调,网络的所有其他方面都是相同的,因此性能上的任何差异都可以归因于本文的二进制自我监督。为了评估信源分离质量,本文使用了广泛使用的mir评估库[36]和标准度量:信号失真比(SDR)、信号干扰比(SIR)和信号伪影比(SAR)。表2显示了结果。本文通过推断双耳音频获得很大的增益。与原始的单声道音频相比,推断的双声道音频提供了更丰富的音频表示,从而导致更清晰的分离。示例见补充视频4。
5. Conclusion
本文提出了一种利用视频帧中的对象/场景配置将单声道音频转换为双耳音频的方法。预测的2.5D可视声音提供了更沉浸式的音频体验。本文的Mono2基础框架在音频空间化方面实现了最先进的性能。此外,利用预测的双耳音频作为更好的音频表示,本文提出了一个现代的视听源分离模型。为现成的视频生成双耳音频可以潜在地缩小传输音频和视频体验之间的差距,从而在VR/AR中实现新的应用。作为未来的工作,本文计划探索如何将对象定位和运动结合起来,并显式地模拟场景声音。
以上是关于2.5D Visual Sound:CVPR2019论文解析的主要内容,如果未能解决你的问题,请参考以下文章
CVPR2020_Improved Few-Shot Visual Classification
论文笔记:目标追踪-CVPR2014-Adaptive Color Attributes for Real-time Visual Tracking
[CVPR2021]Beyond Self-attention External Attention using Two Linear Layers for Visual Tasks