关键词匹配优化(第1篇)—— 测试计算过程
Posted hewish
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关键词匹配优化(第1篇)—— 测试计算过程相关的知识,希望对你有一定的参考价值。
昨天大致把思路理清楚了,用one-hot的方式把关键词按字拆开编码,今天尝试可行性。
目前主流的文本向量化方式主要包括one-hot、tf (term-frequency)和tf-idf (term frequency–inverse document frequency)这三种,越往后准确度应该越高。
我的需求比较简单,只有一百多个相对较短的关键词,所以先用one-hot方式向量化,把整个流程跑通,再回来测试准确度的区别。
分词的话可以用python的jieba包,因为词语比较短,所以也先不分词了,按字拆分。
一百多个词拆下来一共200多个关键字,感觉也还ok。
思路的验证是在Excel中做的,毕竟数据量小,看起来也方便。
流程是:先用vba把词拆成字(用Excel公式也可以完成);用vba的字典功能把字去重放到首行;然后用countif公式得出one-hot编码。
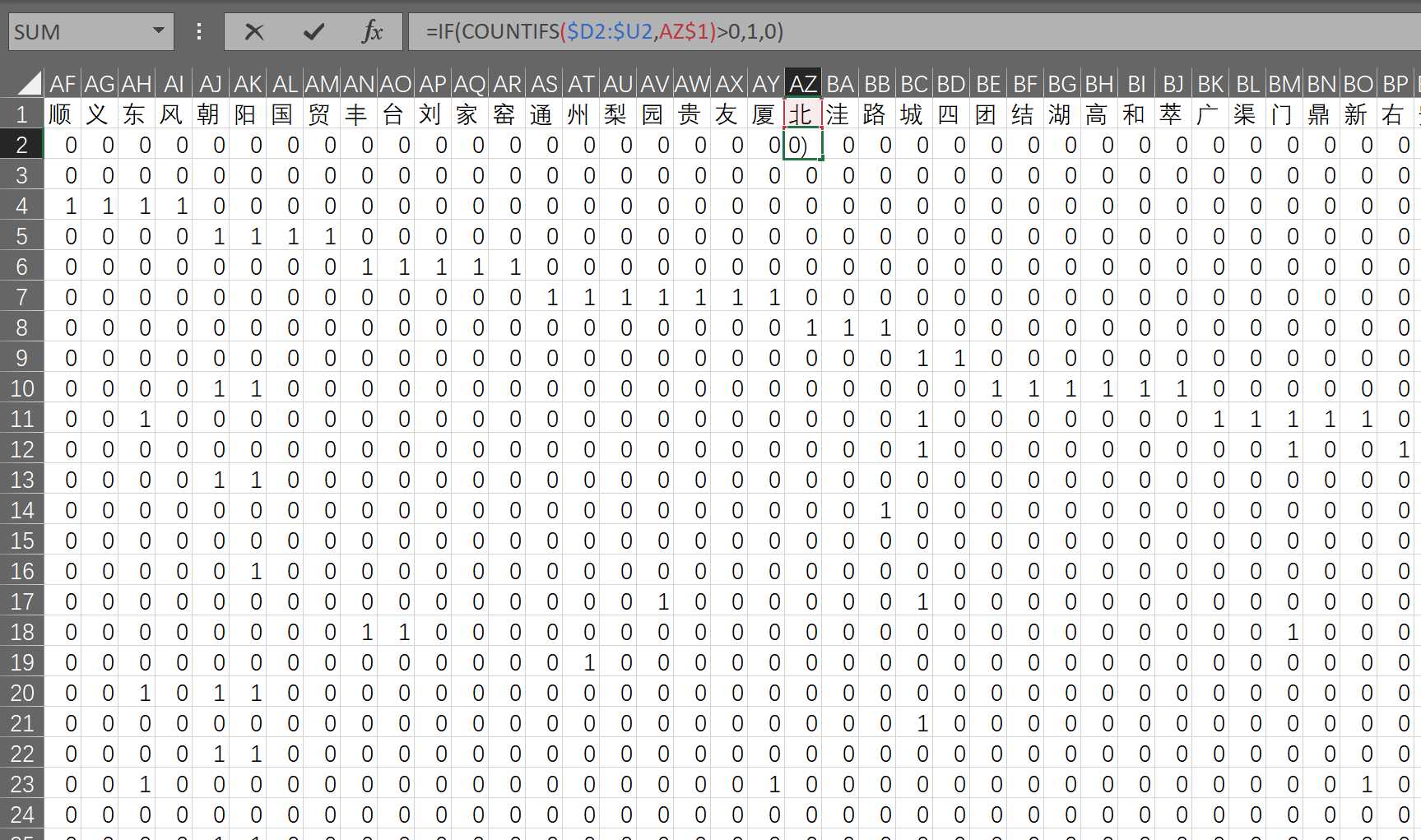
后面遇到新词之后计算新词的编码,对比两个向量就可以计算相似度了。
向量的相似度用 余弦相似度 方法,不赘述,具体解释可以百度,公式如下。
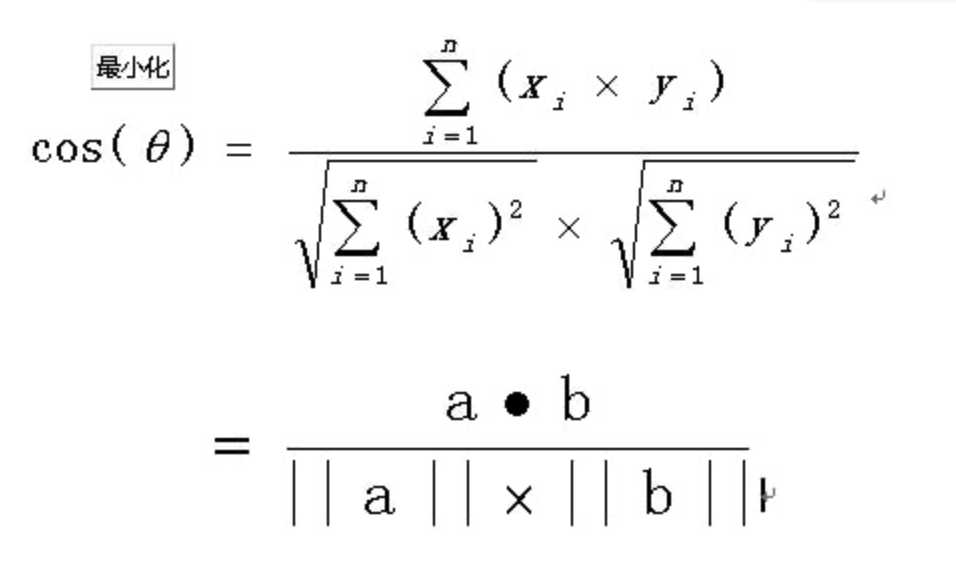
找了一段用numpy计算余弦相似度的代码,进行测试。
import numpy as np
def cos_sim(vector_a, vector_b):
"""
计算两个向量之间的余弦相似度
:param vector_a: 向量 a
:param vector_b: 向量 b
:return: sim
"""
vector_a = np.mat(vector_a)
vector_b = np.mat(vector_b)
num = float(vector_a * vector_b.T)
denom = np.linalg.norm(vector_a) * np.linalg.norm(vector_b)
sim = num / denom
return sim
print( cos_sim(np.array([[1, 1, 1,1,1,1,1,1]]),np.array([[1, 2, 1,1,1,1,1,1]])) )
成功计算出这两个测试向量的相似度
目前整个计算流程基本算是跑通了,接下来就是用C#实现以上功能。
以上是关于关键词匹配优化(第1篇)—— 测试计算过程的主要内容,如果未能解决你的问题,请参考以下文章