kafka基本命令和实践
Posted xumaomao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka基本命令和实践相关的知识,希望对你有一定的参考价值。
Kafka基本命令
#启动server ./bin/kafka-server-start.sh config/server.properties #创建topic(主题)test ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 -partitions 1 --topic test #删除主题 ./bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic test #– 注意:如果kafaka启动时加载的配置文件中server.properties没有配置delete.topic.enable=true,那么此 时的删除并不是真正的删除,而是把topic标记为:marked for deletion #– 此时你若想真正删除它,可以登录zookeeper客户端,进入终端后,删除相应节点 #查看主题 ./bin/kafka-topics.sh --list --zookeeper localhost:2181 #查看主题test的详情 ./bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test #Consumer读消息 ./bin/kafka-console-consumer.sh --zookeeper master:2181 --topic badou --from-beginning #Producer发消息 ./bin/kafka-console-producer.sh --broker-list master:9092 --topic badou
用Kafka和Flume搭建日志系统
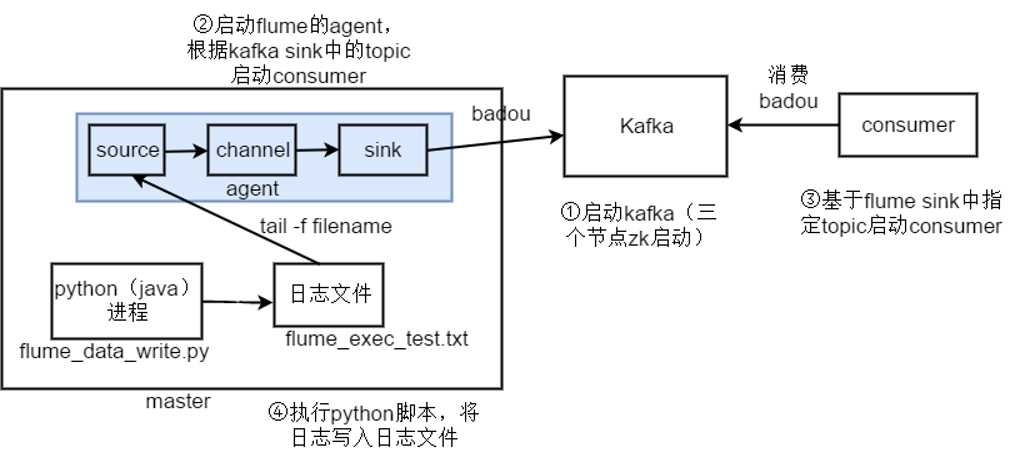
1.master节点和slave节点启动zookeeper
./bin/zkServer.sh start
2.启动kafka
#启动server ./bin/kafka-server-start.sh config/server.properties #创建topic badou ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 -partitions 1 --topic badou #Consumer读消息 ./bin/kafka-console-consumer.sh --zookeeper master:2181 --topic badou --from-beginning
3.启动Flume
./bin/flume-ng agent -c conf -f conf/flume_kafka.conf -n a1 -Dflume.root.logger=INFO,console
Flume配置文件flume_kafka.conf


# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -f /home/badou/flume_test/flume_exec_test.txt #a1.sinks.k1.type = logger # 设置kafka接收器 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink # 设置kafka的broker地址和端口号 a1.sinks.k1.brokerList=master:9092 # 设置Kafka的topic a1.sinks.k1.topic=badou # 设置序列化的方式 a1.sinks.k1.serializer.class=kafka.serializer.StringEncoder # use a channel which buffers events in memory a1.channels.c1.type=memory a1.channels.c1.capacity = 100000 a1.channels.c1.transactionCapacity = 1000 # Bind the source and sink to the channel a1.sources.r1.channels=c1 a1.sinks.k1.channel=c1
4.执行python脚本
模拟将后端日志写入日志文件中
python flume_data_write.py
python代码:
# -*- coding: utf-8 -*- import random import time import pandas as pd import json writeFileName="./flume_exec_test.txt" cols = ["order_id","user_id","eval_set","order_number","order_dow","hour","day"] df1 = pd.read_csv(‘/mnt/hgfs/share_folder/00-data/orders.csv‘) df1.columns = cols df = df1.fillna(0) with open(writeFileName,‘a+‘)as wf: for idx,row in df.iterrows(): d = {} for col in cols: d[col]=row[col] js = json.dumps(d) wf.write(js+‘ ‘)
以上是关于kafka基本命令和实践的主要内容,如果未能解决你的问题,请参考以下文章