机器学习——03K均值算法
Posted lcj170
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习——03K均值算法相关的知识,希望对你有一定的参考价值。
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类

图1 统计表格

图2 第一轮实际情况

图3 第二轮实际情况
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
ps:之前人工智能老师教过这个算法,所以代码基本一样。
源代码:
# 导入数据集
from sklearn.datasets import load_iris
import numpy as np
data = load_iris().data
n = len(data) # 计算样本总数
m = data.shape[1] # 样本属性个数
k = 3 #选取类中心个数
dist = np.zeros([n, k + 1]) #初始化距离矩阵,最后一列存放每个样本的类别
center = data[:k, :]
center_new = np.zeros([k, m])
while True:
for i in range(n):
for j in range(k):
dist[i, j] = np.sqrt(sum((data[i, :] - center[j, :]) ** 2))
dist[i, k] = np.argmin(dist[i, :k])
for i in range(k):
index = dist[:, k] == i #
center_new[i, :] = data[index, :].mean(axis=0)
if np.all((center == center_new)):
break
else:
center = center_new
print("150个样本的归类
", dist[:, k])
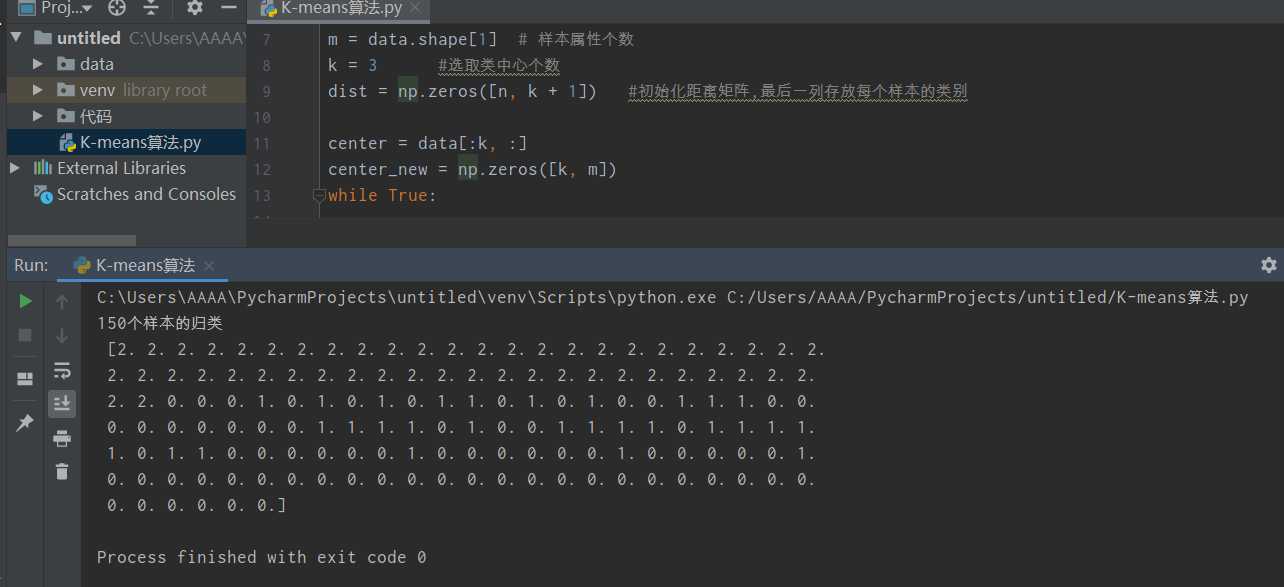
图4 聚类结果
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
源代码:
from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt iris=load_iris() data=iris.data[:,1] x=data.reshape(-1,1) #扁平化 y=KMeans(n_clusters=3) # 引入构建KMeans模型,质心数为3 y.fit(x) #训练模型,计算k均值聚类 y_pre=y.predict(x) #根据训练的模型来预测,即计算聚类中心并预测每个样本的聚类索引 plt.scatter(x[:,0],x[:,0],c=y_pre,s=50,cmap=‘rainbow‘) plt.show()
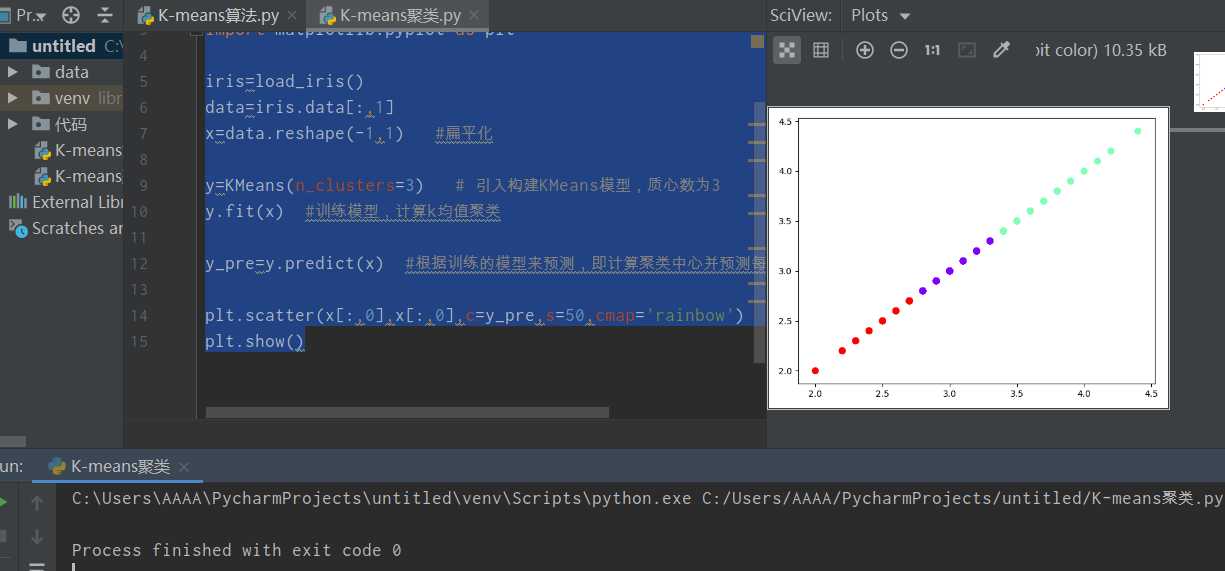
图 5 代码及散点图
4). 鸢尾花完整数据做聚类并用散点图显示.
源代码:
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
iris=load_iris()
x=iris.data
y=KMeans(n_clusters=3) # 引入构建KMeans模型,质心数为3
y.fit(x) #训练模型,计算k均值聚类
y_pre=y.predict(x) #根据训练的模型来预测,即计算聚类中心并预测每个样本的聚类索引
print("预测结果: ", y_pre)
plt.scatter(x[:,2],x[:,3],c=y_pre,s=100,cmap=‘rainbow‘,alpha=0.5)
plt.show()
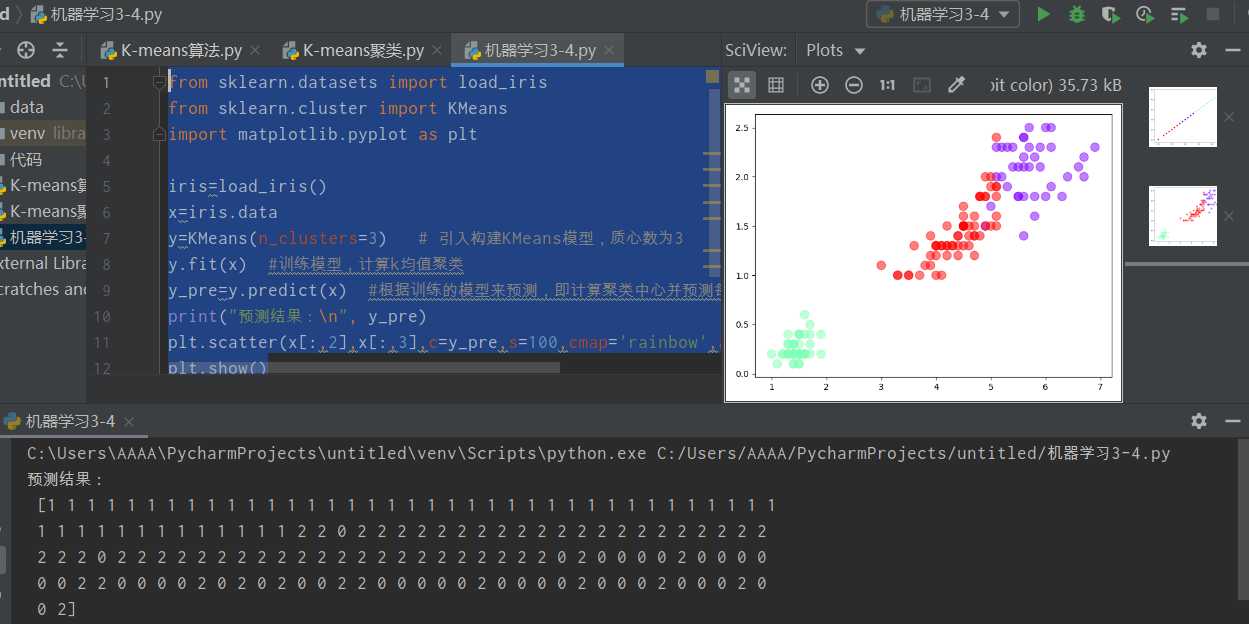
图6 预测的结果及其散点图
5).想想k均值算法中以用来做什么?
答:k均值聚类是最著名的划分聚类算法,由于简洁和效率使得他成为所有聚类算法中最广泛使用的。给定一个数据点集合和需要的聚类数目k,k由用户指定,k均值算法根据某个距离函数反复把数据分入k个聚类中。生活中可以用来分类,根据某个特征对事物进行分类,例如根据往年数据分析中国足球队属于几流水平,根据往年的种子质量来预测今年的种子质量,数据分类等。
以上是关于机器学习——03K均值算法的主要内容,如果未能解决你的问题,请参考以下文章