STM32F407的DSP教程第11章 基础函数-绝对值,求和,乘法和点乘
Posted armfly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了STM32F407的DSP教程第11章 基础函数-绝对值,求和,乘法和点乘相关的知识,希望对你有一定的参考价值。
完整版教程下载地址:http://www.armbbs.cn/forum.php?mod=viewthread&tid=94547
第11章 基础函数-绝对值,求和,乘法和点乘
本期教程开始学习ARM官方的DSP库,这里我们先从基本数学函数开始。本期教程主要讲绝对值,加法,点乘和乘法四种运算。
11.1 初学者重要提示
11.2 DSP基础运算指令
11.3 绝对值(Vector Absolute Value)
11.4 求和(Vector Addition)
11.5 点乘(Vector Dot Product)
11.6 乘法(Vector Multiplication)
11.7 实验例程说明(MDK)
11.8 实验例程说明(IAR)
11.1 初学者重要提示
在这里简单的跟大家介绍一下DSP库中函数的通用格式,后面就不再赘述了。
- 基本所有的函数都是可重入的。
- 大部分函数都支持批量计算,比如求绝对值函数arm_abs_f32。所以如果只是就几个数的绝对值,用这个库函数就没有什么优势了。
- 库函数基本是CM0,CM0+,CM3,CM4和CM7内核都是支持的,不限制厂家。
- 每组数据基本上都是以4个数为一个单位进行计算,不够四个再单独计算。大部分函数都是配有f32,Q31,Q15和Q7四种格式。
- 为什么定点DSP运算输出的时候容易出现结果为0的情况:http://www.armbbs.cn/forum.php?mod=viewthread&tid=95194 。
11.2 DSP基础运算指令
本章用到基础运算指令:
- 绝对值函数用到QSUB,QSUB16和QSUB8。
- 求和函数用到QADD,QADD16和QADD8。
- 点乘函数用到SMLALD和SMLAD。
- 乘法用到__PKHBT和__SSAT。
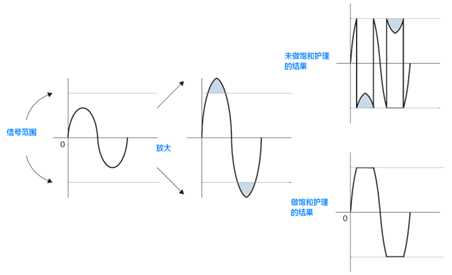
用到的这几个指令,在本章讲解具体函数时都有专门的讲解说明。这里重点说一下饱和运算的问题,字母Q打头的指令是饱和运算指令,饱和的意思超过所能表示的数值范围时,将直接取最大值,比如QSUB16减法指令,如果是正数,那么最大值是0x7FFF(32767),大于这个值将直接取0x7FFF,如果是负数,那么最小值是0x8000(-32768),比这个值还小将直接取值0x8000。
反应到实际应用中就是下面这种效果:
11.3 绝对值(Vector Absolute Value)
这部分函数主要用于求绝对值,公式描述如下:
pDst[n] = abs(pSrc[n]), 0 <= n < blockSize.
特别注意,这部分函数支持目标指针和源指针指向相同的缓冲区。
11.3.1 函数arm_abs_f32
函数原型:
1. void arm_abs_f32( 2. const float32_t * pSrc, 3. float32_t * pDst, 4. uint32_t blockSize) 5. { 6. uint32_t blkCnt; /* Loop counter */ 7. 8. #if defined(ARM_MATH_NEON) 9. float32x4_t vec1; 10. float32x4_t res; 11. 12. /* Compute 4 outputs at a time */ 13. blkCnt = blockSize >> 2U; 14. 15. while (blkCnt > 0U) 16. { 17. /* C = |A| */ 18. 19. /* Calculate absolute values and then store the results in the destination buffer. */ 20. vec1 = vld1q_f32(pSrc); 21. res = vabsq_f32(vec1); 22. vst1q_f32(pDst, res); 23. 24. /* Increment pointers */ 25. pSrc += 4; 26. pDst += 4; 27. 28. /* Decrement the loop counter */ 29. blkCnt--; 30. } 31. 32. /* Tail */ 33. blkCnt = blockSize & 0x3; 34. 35. #else 36. #if defined (ARM_MATH_LOOPUNROLL) 37. 38. /* Loop unrolling: Compute 4 outputs at a time */ 39. blkCnt = blockSize >> 2U; 40. 41. while (blkCnt > 0U) 42. { 43. /* C = |A| */ 44. 45. /* Calculate absolute and store result in destination buffer. */ 46. *pDst++ = fabsf(*pSrc++); 47. 48. *pDst++ = fabsf(*pSrc++); 49. 50. *pDst++ = fabsf(*pSrc++); 51. 52. *pDst++ = fabsf(*pSrc++); 53. 54. /* Decrement loop counter */ 55. blkCnt--; 56. } 57. 58. /* Loop unrolling: Compute remaining outputs */ 59. blkCnt = blockSize % 0x4U; 60. 61. #else 62. 63. /* Initialize blkCnt with number of samples */ 64. blkCnt = blockSize; 65. 66. #endif /* #if defined (ARM_MATH_LOOPUNROLL) */ 67. #endif /* #if defined(ARM_MATH_NEON) */ 68. 69. while (blkCnt > 0U) 70. { 71. /* C = |A| */ 72. 73. /* Calculate absolute and store result in destination buffer. */ 74. *pDst++ = fabsf(*pSrc++); 75. 76. /* Decrement loop counter */ 77. blkCnt--; 78. } 79. 80. }
函数描述:
这个函数用于求32位浮点数的绝对值。
函数解析:
- 第8到35行,用于NEON指令集,当前的CM内核不支持。
- 第36到66行,实现四个为一组进行计数,好处是加快执行速度,降低while循环占用时间。
- 函数fabsf不是用Cortex-M内核支持的DSP指令实现的,而是用C库函数实现的,这个函数是被MDK封装了起来。
- 第69到78行,四个为一组剩余数据的处理或者不采用四个为一组时数据处理。
函数参数:
- 第1个参数是原数据地址。
- 第2个参数是求绝对值后目的数据地址。
- 第3个参数转换的数据个数,这里是指的浮点数个数。
函数描述:
函数形参的源地址和目的地址可以使用同一个缓冲。
11.3.2 函数arm_abs_q31
函数原型:
1. void arm_abs_q31( 2. const q31_t * pSrc, 3. q31_t * pDst, 4. uint32_t blockSize) 5. { 6. uint32_t blkCnt; /* Loop counter */ 7. q31_t in; /* Temporary variable */ 8. 9. #if defined (ARM_MATH_LOOPUNROLL) 10. 11. /* Loop unrolling: Compute 4 outputs at a time */ 12. blkCnt = blockSize >> 2U; 13. 14. while (blkCnt > 0U) 15. { 16. /* C = |A| */ 17. 18. /* Calculate absolute of input (if -1 then saturated to 0x7fffffff) and store result in destination 19. buffer. */ 20. in = *pSrc++; 21. #if defined (ARM_MATH_DSP) 22. *pDst++ = (in > 0) ? in : (q31_t)__QSUB(0, in); 23. #else 24. *pDst++ = (in > 0) ? in : ((in == INT32_MIN) ? INT32_MAX : -in); 25. #endif 26. 27. in = *pSrc++; 28. #if defined (ARM_MATH_DSP) 29. *pDst++ = (in > 0) ? in : (q31_t)__QSUB(0, in); 30. #else 31. *pDst++ = (in > 0) ? in : ((in == INT32_MIN) ? INT32_MAX : -in); 32. #endif 33. 34. in = *pSrc++; 35. #if defined (ARM_MATH_DSP) 36. *pDst++ = (in > 0) ? in : (q31_t)__QSUB(0, in); 37. #else 38. *pDst++ = (in > 0) ? in : ((in == INT32_MIN) ? INT32_MAX : -in); 39. #endif 40. 41. in = *pSrc++; 42. #if defined (ARM_MATH_DSP) 43. *pDst++ = (in > 0) ? in : (q31_t)__QSUB(0, in); 44. #else 45. *pDst++ = (in > 0) ? in : ((in == INT32_MIN) ? INT32_MAX : -in); 46. #endif 47. 48. /* Decrement loop counter */ 49. blkCnt--; 50. } 51. 52. /* Loop unrolling: Compute remaining outputs */ 53. blkCnt = blockSize % 0x4U; 54. 55. #else 56. 57. /* Initialize blkCnt with number of samples */ 58. blkCnt = blockSize; 59. 60. #endif /* #if defined (ARM_MATH_LOOPUNROLL) */ 61. 62. while (blkCnt > 0U) 63. { 64. /* C = |A| */ 65. 66. /* Calculate absolute of input (if -1 then saturated to 0x7fffffff) and store result in destination 67. buffer. */ 68. in = *pSrc++; 69. #if defined (ARM_MATH_DSP) 70. *pDst++ = (in > 0) ? in : (q31_t)__QSUB(0, in); 71. #else 72. *pDst++ = (in > 0) ? in : ((in == INT32_MIN) ? INT32_MAX : -in); 73. #endif 74. 75. /* Decrement loop counter */ 76. blkCnt--; 77. } 78. 79. }
函数描述:
用于求32位定点数的绝对值。
函数解析:
- 第9到60行,实现四个为一组进行计数,好处是加快执行速度,降低while循环占用时间。
- 第69到78行,四个为一组剩余数据的处理或者不采用四个为一组时数据处理。
- 这个函数使用了饱和运算,其实不光这个函数,后面很多函数都是使用了饱和运算的,关于什么是饱和运算,大家看Cortex-M3权威指南中文版的4.3.6 小节:汇编语言:饱和运算即可。
- 对于Q31格式的数据,饱和运算会使得数据0x80000000变成0x7fffffff(这个数比较特殊,算是特殊处理,记住即可)。
- 这里重点说一下函数__QSUB,其实这个函数算是Cortex-M7,M4/M3的一个指令,用于实现饱和减法。比如函数:__QSUB(0, in1) 的作用就是实现0 – in1并返回结果。这里__QSUB实现的是32位数的饱和减法。还有__QSUB16和__QSUB8实现的是16位和8位数的减法。
函数参数:
- 第1个参数是原数据地址。
- 第2个参数是求绝对值后目的数据地址。
- 第3个参数转换的数据个数,这里是指的定点数个数。
函数描述:
函数形参的源地址和目的地址可以使用同一个缓冲。
11.3.3 函数arm_abs_q15
函数原型:
1. void arm_abs_q15( 2. const q15_t * pSrc, 3. q15_t * pDst, 4. uint32_t blockSize) 5. { 6. uint32_t blkCnt; /* Loop counter */ 7. q15_t in; /* Temporary input variable */ 8. 9. #if defined (ARM_MATH_LOOPUNROLL) 10. 11. /* Loop unrolling: Compute 4 outputs at a time */ 12. blkCnt = blockSize >> 2U; 13. 14. while (blkCnt > 0U) 15. { 16. /* C = |A| */ 17. 18. /* Calculate absolute of input (if -1 then saturated to 0x7fff) and store result in destination buffer. 19. */ 20. in = *pSrc++; 21. #if defined (ARM_MATH_DSP) 22. *pDst++ = (in > 0) ? in : (q15_t)__QSUB16(0, in); 23. #else 24. *pDst++ = (in > 0) ? in : ((in == (q15_t) 0x8000) ? 0x7fff : -in); 25. #endif 26. 27. in = *pSrc++; 28. #if defined (ARM_MATH_DSP) 29. *pDst++ = (in > 0) ? in : (q15_t)__QSUB16(0, in); 30. #else 31. *pDst++ = (in > 0) ? in : ((in == (q15_t) 0x8000) ? 0x7fff : -in); 32. #endif 33. 34. in = *pSrc++; 35. #if defined (ARM_MATH_DSP) 36. *pDst++ = (in > 0) ? in : (q15_t)__QSUB16(0, in); 37. #else 38. *pDst++ = (in > 0) ? in : ((in == (q15_t) 0x8000) ? 0x7fff : -in); 39. #endif 40. 41. in = *pSrc++; 42. #if defined (ARM_MATH_DSP) 43. *pDst++ = (in > 0) ? in : (q15_t)__QSUB16(0, in); 44. #else 45. *pDst++ = (in > 0) ? in : ((in == (q15_t) 0x8000) ? 0x7fff : -in); 46. #endif 47. 48. /* Decrement loop counter */ 49. blkCnt--; 50. } 51. 52. /* Loop unrolling: Compute remaining outputs */ 53. blkCnt = blockSize % 0x4U; 54. 55. #else 56. 57. /* Initialize blkCnt with number of samples */ 58. blkCnt = blockSize; 59. 60. #endif /* #if defined (ARM_MATH_LOOPUNROLL) */ 61. 62. while (blkCnt > 0U) 63. { 64. /* C = |A| */ 65. 66. /* Calculate absolute of input (if -1 then saturated to 0x7fff) and store result in destination buffer. 67. */ 68. in = *pSrc++; 69. #if defined (ARM_MATH_DSP) 70. *pDst++ = (in > 0) ? in : (q15_t)__QSUB16(0, in); 71. #else 72. *pDst++ = (in > 0) ? in : ((in == (q15_t) 0x8000) ? 0x7fff : -in); 73. #endif 74. 75. /* Decrement loop counter */ 76. blkCnt--; 77. } 78. 79. }
函数描述:
用于求16位定点数的绝对值。
函数解析:
- 第9到55行,实现四个为一组进行计数,好处是加快执行速度,降低while循环占用时间。
- 第62到77行,四个为一组剩余数据的处理或者不采用四个为一组时数据处理。
- 对于Q15格式的数据,饱和运算会使得数据0x8000变成0x7fff。
- __QSUB16用于实现16位数据的饱和减法。
函数参数:
- 第1个参数是原数据地址。
- 第2个参数是求绝对值后目的数据地址。
- 第3个参数转换的数据个数,这里是指的定点数个数。
函数描述:
函数形参的源地址和目的地址可以使用同一个缓冲。
11.3.4 函数arm_abs_q7
函数原型:
1. void arm_abs_q7( 2. const q7_t * pSrc, 3. q7_t * pDst, 4. uint32_t blockSize) 5. { 6. uint32_t blkCnt; /* Loop counter */ 7. q7_t in; /* Temporary input variable */ 8. 9. #if defined (ARM_MATH_LOOPUNROLL) 10. 11. /* Loop unrolling: Compute 4 outputs at a time */ 12. blkCnt = blockSize >> 2U; 13. 14. while (blkCnt > 0U) 15. { 16. /* C = |A| */ 17. 18. /* Calculate absolute of input (if -1 then saturated to 0x7f) and store result in destination buffer. 19. */ 20. in = *pSrc++; 21. #if defined (ARM_MATH_DSP) 22. *pDst++ = (in > 0) ? in : (q7_t)__QSUB(0, in); 23. #else 24. *pDst++ = (in > 0) ? in : ((in == (q7_t) 0x80) ? (q7_t) 0x7f : -in); 25. #endif 26. 27. in = *pSrc++; 28. #if defined (ARM_MATH_DSP) 29. *pDst++ = (in > 0) ? in : (q7_t)__QSUB(0, in); 30. #else 31. *pDst++ = (in > 0) ? in : ((in == (q7_t) 0x80) ? (q7_t) 0x7f : -in); 32. #endif 33. 34. in = *pSrc++; 35. #if defined (ARM_MATH_DSP) 36. *pDst++ = (in > 0) ? in : (q7_t)__QSUB(0, in); 37. #else 38. *pDst++ = (in > 0) ? in : ((in == (q7_t) 0x80) ? (q7_t) 0x7f : -in); 39. #endif 40. 41. in = *pSrc++;ezi le mexia 42. #if defined (ARM_MATH_DSP) 43. *pDst++ = (in > 0) ? in : (q7_t)__QSUB(0, in); 44. #else 45. *pDst++ = (in > 0) ? in : ((in == (q7_t) 0x80) ? (q7_t) 0x7f : -in); 46. #endif 47. 48. /* Decrement loop counter */ 49. blkCnt--; 50. } 51. 52. /* Loop unrolling: Compute remaining outputs */ 53. blkCnt = blockSize % 0x4U; 54. 55. #else 56. 57. /* Initialize blkCnt with number of samples */ 58. blkCnt = blockSize; 59. 60. #endif /* #if defined (ARM_MATH_LOOPUNROLL) */ 61. 62. while (blkCnt > 0U) 63. { 64. /* C = |A| */ 65. 66. /* Calculate absolute of input (if -1 then saturated to 0x7f) and store result in destination buffer. 67. */ 68. in = *pSrc++; 69. #if defined (ARM_MATH_DSP) 70. *pDst++ = (in > 0) ? in : (q7_t) __QSUB(0, in); 71. #else 72. *pDst++ = (in > 0) ? in : ((in == (q7_t) 0x80) ? (q7_t) 0x7f : -in); 73. #endif 74. 75. /* Decrement loop counter */ 76. blkCnt--; 77. } 78. 79. }
函数描述:
用于求8位定点数的绝对值。
函数解析:
- 第9到55行,实现四个为一组进行计数,好处是加快执行速度,降低while循环占用时间。
- 第62到77行,四个为一组剩余数据的处理或者不采用四个为一组时数据处理。
- 对于Q7格式的数据,饱和运算会使得数据0x80变成0x7f。
- __QSUB用于实现32位数据的饱和减法。而当前的DSP库版本却将其用到了Q7函数中,导致0x80的饱和出错。详情看此贴:http://www.armbbs.cn/forum.php?mod=viewthread&tid=95152 。
函数参数:
- 第1个参数是原数据地址。
- 第2个参数是求绝对值后目的数据地址。
- 第3个参数转换的数据个数,这里是指的定点数个数。
函数描述:
函数形参的源地址和目的地址可以使用同一个缓冲。
11.3.5 使用举例
程序设计:
/* ********************************************************************************************************* * 函 数 名: DSP_ABS * 功能说明: 求绝对值 * 形 参: 无 * 返 回 值: 无 ********************************************************************************************************* */ static void DSP_ABS(void) { float32_t pSrc; float32_t pDst; q31_t pSrc1; q31_t pDst1; q15_t pSrc2; q15_t pDst2; q7_t pSrc3; q7_t pDst3; /*求绝对值*********************************/ pSrc -= 1.23f; arm_abs_f32(&pSrc, &pDst, 1); printf("arm_abs_f32 = %f ", pDst); pSrc1 -= 1; arm_abs_q31(&pSrc1, &pDst1, 1); printf("arm_abs_q31 = %d ", pDst1); pSrc2 = -32768; arm_abs_q15(&pSrc2, &pDst2, 1); printf("arm_abs_q15 = %d ", pDst2); pSrc3 = 127; arm_abs_q7(&pSrc3, &pDst3, 1); printf("arm_abs_q7 = %d ", pDst3); printf("*********************************** "); }
实验现象:
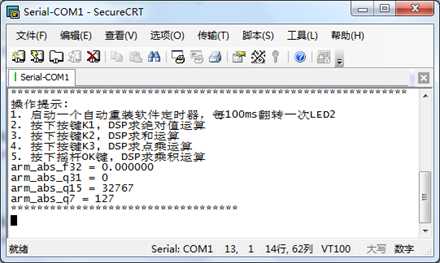
这里特别注意Q15的计算,数值-32768被饱和处理到32767,即0 - (-32768)= 32768,超出了正数所能表示的最大值,经过饱和后,输出为32767。
11.4 求和(Vector Addition)
这部分函数主要用于求和,公式描述如下:
pDst[n] = pSrcA[n] + pSrcB[n], 0 <= n < blockSize.
11.4.1 函数arm_add_f32
函数原型:
1. void arm_add_f32( 2. const float32_t * pSrcA, 3. const float32_t * pSrcB, 4. float32_t * pDst, 5. uint32_t blockSize) 6. { 7. uint32_t blkCnt; /* Loop counter */ 8. 9. #if defined(ARM_MATH_NEON) 10. float32x4_t vec1; 11. float32x4_t vec2; 12. float32x4_t res; 13. 14. /* Compute 4 outputs at a time */ 15. blkCnt = blockSize >> 2U; 16. 17. while (blkCnt > 0U) 18. { 19. /* C = A + B */ 20. 21. /* Add and then store the results in the destination buffer. */ 22. vec1 = vld1q_f32(pSrcA); 23. vec2 = vld1q_f32(pSrcB); 24. res = vaddq_f32(vec1, vec2); 25. vst1q_f32(pDst, res); 26. 27. /* Increment pointers */ 28. pSrcA += 4; 29. pSrcB += 4; 30. pDst += 4; 31. 32. /* Decrement the loop counter */ 33. blkCnt--; 34. } 35. 36. /* Tail */ 37. blkCnt = blockSize & 0x3; 38. 39. #else 40. #if defined (ARM_MATH_LOOPUNROLL) 41. 42. /* Loop unrolling: Compute 4 outputs at a time */ 43. blkCnt = blockSize >> 2U; 44. 45. while (blkCnt > 0U) 46. { 47. /* C = A + B */ 48. 49. /* Add and store result in destination buffer. */ 50. *pDst++ = (*pSrcA++) + (*pSrcB++); 51. *pDst++ = (*pSrcA++) + (*pSrcB++); 52. *pDst++ = (*pSrcA++) + (*pSrcB++); 53. *pDst++ = (*pSrcA++) + (*pSrcB++); 54. 55. /* Decrement loop counter */ 56. blkCnt--; 57. } 58. 59. /* Loop unrolling: Compute remaining outputs */ 60. blkCnt = blockSize % 0x4U; 61. 62. #else 63. 64. /* Initialize blkCnt with number of samples */ 65. blkCnt = blockSize; 66. 67. #endif /* #if defined (ARM_MATH_LOOPUNROLL) */ 68. #endif /* #if defined(ARM_MATH_NEON) */ 69. 70. while (blkCnt > 0U) 71. { 72. /* C = A + B */ 73. 74. /* Add and store result in destination buffer. */ 75. *pDst++ = (*pSrcA++) + (*pSrcB++); 76. 77. /* Decrement loop counter */ 78. blkCnt--; 79. } 80. 81. }
函数描述:
这个函数用于求两个32位浮点数的和。
函数解析:
- 第8到35行,用于NEON指令集,当前的CM内核不支持。
- 第40到62行,实现四个为一组进行计数,好处是加快执行速度,降低while循环占用时间。
- 第70到79行,四个为一组剩余数据的处理或者不采用四个为一组时数据处理。
函数参数:
- 第1个参数是加数地址。
- 第2个参数是被加数地址。
- 第3个参数是和地址。
- 第4个参数是浮点数个数,其实就是执行加法的次数。
11.4.2 函数arm_add_q31
函数原型:
1. void arm_add_q31( 2. const q31_t * pSrcA, 3. const q31_t * pSrcB, 4. q31_t * pDst, 5. uint32_t blockSize) 6. { 7. uint32_t blkCnt; /* Loop counter */ 8. 9. #if defined (ARM_MATH_LOOPUNROLL) 10. 11. /* Loop unrolling: Compute 4 outputs at a time */ 12. blkCnt = blockSize >> 2U; 13. 14. while (blkCnt > 0U) 15. { 16. /* C = A + B */ 17. 18. /* Add and store result in destination buffer. */ 19. *pDst++ = __QADD(*pSrcA++, *pSrcB++); 20. 21. *pDst++ = __QADD(*pSrcA++, *pSrcB++); 22. 23. *pDst++ = __QADD(*pSrcA++, *pSrcB++); 24. 25. *pDst++ = __QADD(*pSrcA++, *pSrcB++); 26. 27. /* Decrement loop counter */ 28. blkCnt--; 29. } 30. 31. /* Loop unrolling: Compute remaining outputs */ 32. blkCnt = blockSize % 0x4U; 33. 34. #else 35. 36. /* Initialize blkCnt with number of samples */ 37. blkCnt = blockSize; 38. 39. #endif /* #if defined (ARM_MATH_LOOPUNROLL) */ 40. 41. while (blkCnt > 0U) 42. { 43. /* C = A + B */ 44. 45. /* Add and store result in destination buffer. */ 46. *pDst++ = __QADD(*pSrcA++, *pSrcB++); 47. 48. /* Decrement loop counter */ 49. blkCnt--; 50. } 51. 52. }
函数描述:
这个函数用于求两个32位定点数的和。
函数解析:
- 第9到34行,实现四个为一组进行计数,好处是加快执行速度,降低while循环占用时间。
- 第41到50行,四个为一组剩余数据的处理或者不采用四个为一组时数据处理。
- __QADD实现32位数的加法饱和运算。输出结果的范围[0x80000000 0x7FFFFFFF],超出这个结果将产生饱和结果,负数饱和到0x80000000,正数饱和到0x7FFFFFFF。
函数参数:
- 第1个参数是加数地址。
- 第2个参数是被加数地址。
- 第3个参数是和地址。
- 第4个参数是定点数个数,其实就是执行加法的次数。
11.4.3 函数arm_add_q15
函数原型:
1. void arm_add_q15( 2. const q15_t * pSrcA, 3. const q15_t * pSrcB, 4. q15_t * pDst, 5. uint32_t blockSize) 6. { 7. uint32_t blkCnt; /* Loop counter */ 8. 9. #if defined (ARM_MATH_LOOPUNROLL) 10. 11. #if defined (ARM_MATH_DSP) 12. q31_t inA1, inA2; 13. q31_t inB1, inB2; 14. #endif 15. 16. /* Loop unrolling: Compute 4 outputs at a time */ 17. blkCnt = blockSize >> 2U; 18. 19. while (blkCnt > 0U) 20. { 21. /* C = A + B */ 22. 23. #if defined (ARM_MATH_DSP) 24. /* read 2 times 2 samples at a time from sourceA */ 25. inA1 = read_q15x2_ia ((q15_t **) &pSrcA); 26. inA2 = read_q15x2_ia ((q15_t **) &pSrcA); 27. /* read 2 times 2 samples at a time from sourceB */ 28. inB1 = read_q15x2_ia ((q15_t **) &pSrcB); 29. inB2 = read_q15x2_ia ((q15_t **) &pSrcB); 30. 31. /* Add and store 2 times 2 samples at a time */ 32. write_q15x2_ia (&pDst, __QADD16(inA1, inB1)); 33. write_q15x2_ia (&pDst, __QADD16(inA2, inB2)); 34. #else 35. *pDst++ = (q15_t) __SSAT(((q31_t) *pSrcA++ + *pSrcB++), 16); 36. *pDst++ = (q15_t) __SSAT(((q31_t) *pSrcA++ + *pSrcB++), 16); 37. *pDst++ = (q15_t) __SSAT(((q31_t) *pSrcA++ + *pSrcB++), 16); 38. *pDst++ = (q15_t) __SSAT(((q31_t) *pSrcA++ + *pSrcB++), 16); 39. #endif 40. 41. /* Decrement loop counter */ 42. blkCnt--; 43. } 44. 45. /* Loop unrolling: Compute remaining outputs */ 46. blkCnt = blockSize % 0x4U; 47. 48. #else 49. 50. /* Initialize blkCnt with number of samples */ 51. blkCnt = blockSize; 52. 53. #endif /* #if defined (ARM_MATH_LOOPUNROLL) */ 54. 55. while (blkCnt > 0U) 56. { 57. /* C = A + B */ 58. 59. /* Add and store result in destination buffer. */ 60. #if defined (ARM_MATH_DSP) 61. *pDst++ = (q15_t) __QADD16(*pSrcA++, *pSrcB++); 62. #else 63. *pDst++ = (q15_t) __SSAT(((q31_t) *pSrcA++ + *pSrcB++), 16); 64. #endif 65. 66. /* Decrement loop counter */ 67. blkCnt--; 68. } 69. 70. }
函数描述:
这个函数用于求两个16位定点数的和。
函数解析:
- 第23到34行,对于M4和M7带DSP单元的芯片使用。
- 第35到38行,对于不带DSP单元的M0,M0+和M3使用。
- 第55到68行,四个为一组剩余数据的处理或者不采用四个为一组时数据处理。
- 函数read_q15x2_ia的原型如下:
__STATIC_FORCEINLINE q31_t read_q15x2_ia ( q15_t ** pQ15) { q31_t val; memcpy (&val, *pQ15, 4); *pQ15 += 2; return (val); }
作用是读取两次16位数据,返回一个32位数据,并将数据地址递增,方便下次读取。
- __QADD16实现两次16位数的加法饱和运算。输出结果的范围[0x8000 0x7FFF],超出这个结果将产生饱和结果,负数饱和到0x8000,正数饱和到0x7FFF。
- __SSAT也是SIMD指令,这里是将结果饱和到16位精度。
函数参数:
- 第1个参数是加数地址。
- 第2个参数是被加数地址。
- 第3个参数是和地址。
- 第4个参数是定点数个数,其实就是执行加法的次数。
11.4.4 函数arm_add_q7
函数原型:
1. void arm_add_q7( 2. const q7_t * pSrcA, 3. const q7_t * pSrcB, 4. q7_t * pDst, 5. uint32_t blockSize) 6. { 7. uint32_t blkCnt; /* Loop counter */ 8. 9. #if defined (ARM_MATH_LOOPUNROLL) 10. 11. /* Loop unrolling: Compute 4 outputs at a time */ 12. blkCnt = blockSize >> 2U; 13. 14. while (blkCnt > 0U) 15. { 16. /* C = A + B */ 17. 18. #if defined (ARM_MATH_DSP) 19. /* Add and store result in destination buffer (4 samples at a time). */ 20. write_q7x4_ia (&pDst, __QADD8 (read_q7x4_ia ((q7_t **) &pSrcA), read_q7x4_ia ((q7_t **) &pSrcB))); 21. #else 22. *pDst++ = (q7_t) __SSAT ((q15_t) *pSrcA++ + *pSrcB++, 8); 23. *pDst++ = (q7_t) __SSAT ((q15_t) *pSrcA++ + *pSrcB++, 8); 24. *pDst++ = (q7_t) __SSAT ((q15_t) *pSrcA++ + *pSrcB++, 8); 25. *pDst++ = (q7_t) __SSAT ((q15_t) *pSrcA++ + *pSrcB++, 8); 26. #endif 27. 28. /* Decrement loop counter */ 29. blkCnt--; 30. } 31. 32. /* Loop unrolling: Compute remaining outputs */ 33. blkCnt = blockSize % 0x4U; 34. 35. #else 36. 37. /* Initialize blkCnt with number of samples */ 38. blkCnt = blockSize; 39. 40. #endif /* #if defined (ARM_MATH_LOOPUNROLL) */ 41. 42. while (blkCnt > 0U) 43. { 44. /* C = A + B */ 45. 46. /* Add and store result in destination buffer. */ 47. *pDst++ = (q7_t) __SSAT((q15_t) *pSrcA++ + *pSrcB++, 8); 48. 49. /* Decrement loop counter */ 50. blkCnt--; 51. } 52. 53. }
函数描述:
这个函数用于求两个8位定点数的和。
函数解析:
- 第18到21行,对于M4和M7带DSP单元的芯片使用。
- 第22到25行,对于不带DSP单元的M0,M0+和M3使用。
- 第42到51行,四个为一组剩余数据的处理或者不采用四个为一组时数据处理。
- 函数read_q15x2_ia的原型如下:
__STATIC_FORCEINLINE void write_q7x4_ia ( q7_t ** pQ7, q31_t value) { q31_t val = value; memcpy (*pQ7, &val, 4); *pQ7 += 4; }
作用是读取4次8位数据,返回一个32位数据,并将数据地址递增,方便下次读取。
- __QADD8实现四次8位数的加法饱和运算。输出结果的范围[0x80 0x7F],超出这个结果将产生饱和结果,负数饱和到0x80,正数饱和到0x7F。
函数参数:
- 第1个参数是加数地址。
- 第2个参数是被加数地址。
- 第3个参数是和地址。
- 第4个参数是定点数个数,其实就是执行加法的次数。
11.4.5 使用举例
程序设计:
/* ********************************************************************************************************* * 函 数 名: DSP_Add * 功能说明: 加法 * 形 参: 无 * 返 回 值: 无 ********************************************************************************************************* */ static void DSP_Add(void) { float32_t pSrcA; float32_t pSrcB; float32_t pDst; q31_t pSrcA1; q31_t pSrcB1; q31_t pDst1; q15_t pSrcA2; q15_t pSrcB2; q15_t pDst2; q7_t pSrcA3; q7_t pSrcB3; q7_t pDst3; /*求和*********************************/ pSrcA = 0.1f; pSrcB = 0.2f; arm_add_f32(&pSrcA, &pSrcB, &pDst, 1); printf("arm_add_f32 = %f ", pDst); pSrcA1 = 1; pSrcB1 = 1; arm_add_q31(&pSrcA1, &pSrcB1, &pDst1, 1); printf("arm_add_q31 = %d ", pDst1); pSrcA2 = 2; pSrcB2 = 2; arm_add_q15(&pSrcA2, &pSrcB2, &pDst2, 1); printf("arm_add_q15 = %d ", pDst2); pSrcA3 = 30; pSrcB3 = 120; arm_add_q7(&pSrcA3, &pSrcB3, &pDst3, 1); printf("arm_add_q7 = %d ", pDst3); printf("*********************************** "); }
实验现象:
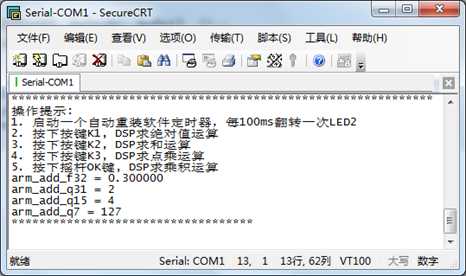
这里特别注意Q7的计算处理,30+120已经超出了Q7所能表示的最大值127,经过饱和处理后,经过饱和后,输出为127。
11.5 点乘(Vector Dot Product)
这部分函数主要用于点乘,公式描述如下:
sum = pSrcA[0]*pSrcB[0] + pSrcA[1]*pSrcB[1] + ... + pSrcA[blockSize-1]*pSrcB[blockSize-1]
11.5.1 函数arm_dot_prod_f32
函数原型:
1. void arm_dot_prod_f32( 2. const float32_t * pSrcA, 3. const float32_t * pSrcB, 4. uint32_t blockSize, 5. float32_t * result) 6. { 7. uint32_t blkCnt; /* Loop counter */ 8. float32_t sum = 0.0f; /* Temporary return variable */ 9. 10. #if defined(ARM_MATH_NEON) 11. float32x4_t vec1; 12. float32x4_t vec2; 13. float32x4_t res; 14. float32x4_t accum = vdupq_n_f32(0); 15. 16. /* Compute 4 outputs at a time */ 17. blkCnt = blockSize >> 2U; 18. 19. vec1 = vld1q_f32(pSrcA); 20. vec2 = vld1q_f32(pSrcB); 21. 22. while (blkCnt > 0U) 23. { 24. /* C = A[0]*B[0] + A[1]*B[1] + A[2]*B[2] + ... + A[blockSize-1]*B[blockSize-1] */ 25. /* Calculate dot product and then store the result in a temporary buffer. */ 26. 27. accum = vmlaq_f32(accum, vec1, vec2); 28. 29. /* Increment pointers */ 30. pSrcA += 4; 31. pSrcB += 4; 32. 33. vec1 = vld1q_f32(pSrcA); 34. vec2 = vld1q_f32(pSrcB); 35. 36. /* Decrement the loop counter */ 37. blkCnt--; 38. } 39. 40. #if __aarch64__ 41. sum = vpadds_f32(vpadd_f32(vget_low_f32(accum), vget_high_f32(accum))); 42. #else 43. sum = (vpadd_f32(vget_low_f32(accum), vget_high_f32(accum)))[0] + (vpadd_f32(vget_low_f32(accum), 44. vget_high_f32(accum)))[1]; 45. #endif 46. 47. /* Tail */ 48. blkCnt = blockSize & 0x3; 49. 50. #else 51. #if defined (ARM_MATH_LOOPUNROLL) 52. 53. /* Loop unrolling: Compute 4 outputs at a time */ 54. blkCnt = blockSize >> 2U; 55. 56. /* First part of the processing with loop unrolling. Compute 4 outputs at a time. 57. ** a second loop below computes the remaining 1 to 3 samples. */ 58. while (blkCnt > 0U) 59. { 60. /* C = A[0]* B[0] + A[1]* B[1] + A[2]* B[2] + .....+ A[blockSize-1]* B[blockSize-1] */ 61. 62. /* Calculate dot product and store result in a temporary buffer. */ 63. sum += (*pSrcA++) * (*pSrcB++); 64. 65. sum += (*pSrcA++) * (*pSrcB++); 66. 67. sum += (*pSrcA++) * (*pSrcB++); 68. 69. sum += (*pSrcA++) * (*pSrcB++); 70. 71. /* Decrement loop counter */ 72. blkCnt--; 73. } 74. 75. /* Loop unrolling: Compute remaining outputs */ 76. blkCnt = blockSize % 0x4U; 77. 78. #else 79. 80. /* Initialize blkCnt with number of samples */ 81. blkCnt = blockSize; 82. 83. #endif /* #if defined (ARM_MATH_LOOPUNROLL) */ 84. #endif /* #if defined(ARM_MATH_NEON) */ 85. 86. while (blkCnt > 0U) 87. { 88. /* C = A[0]* B[0] + A[1]* B[1] + A[2]* B[2] + .....+ A[blockSize-1]* B[blockSize-1] */ 89. 90. /* Calculate dot product and store result in a temporary buffer. */ 91. sum += (*pSrcA++) * (*pSrcB++); 92. 93. /* Decrement loop counter */ 94. blkCnt--; 95. } 96. 97. /* Store result in destination buffer */ 98. *result = sum; 99. }
函数描述:
这个函数用于求32位浮点数的点乘。
函数解析:
- 第10到50行,用于NEON指令集,当前的CM内核不支持。
- 第51到78行,实现四个为一组进行计数,好处是加快执行速度,降低while循环占用时间。
- 第86到95行,四个为一组剩余数据的处理或者不采用四个为一组时数据处理。
函数参数:
- 第1个参数是乘数地址。
- 第2个参数是被乘数地址。
- 第3个参数是浮点数个数,其实就是执行点乘的次数。
- 第4个参数是结果地址。
11.5.2 函数arm_dot_prod_q31
函数原型:
1. void arm_dot_prod_q31( 2. const q31_t * pSrcA, 3. const q31_t * pSrcB, 4. uint32_t blockSize, 5. q63_t * result) 6. { 7. uint32_t blkCnt; /* Loop counter */ 8. q63_t sum = 0; /* Temporary return variable */ 9. 10. #if defined (ARM_MATH_LOOPUNROLL) 11. 12. /* Loop unrolling: Compute 4 outputs at a time */ 13. blkCnt = blockSize >> 2U; 14. 15. while (blkCnt > 0U) 16. { 17. /* C = A[0]* B[0] + A[1]* B[1] + A[2]* B[2] + .....+ A[blockSize-1]* B[blockSize-1] */ 18. 19. /* Calculate dot product and store result in a temporary buffer. */ 20. sum += ((q63_t) *pSrcA++ * *pSrcB++) >> 14U; 21. 22. sum += ((q63_t) *pSrcA++ * *pSrcB++) >> 14U; 23. 24. sum += ((q63_t) *pSrcA++ * *pSrcB++) >> 14U; 25. 26. sum += ((q63_t) *pSrcA++ * *pSrcB++) >> 14U; 27. 28. /* Decrement loop counter */ 29. blkCnt--; 30. } 31. 32. /* Loop unrolling: Compute remaining outputs */ 33. blkCnt = blockSize % 0x4U; 34. 35. #else 36. 37. /* Initialize blkCnt with number of samples */ 38. blkCnt = blockSize; 39. 40. #endif /* #if defined (ARM_MATH_LOOPUNROLL) */ 41. 42. while (blkCnt > 0U) 43. { 44. /* C = A[0]* B[0] + A[1]* B[1] + A[2]* B[2] + .....+ A[blockSize-1]* B[blockSize-1] */ 45. 46. /* Calculate dot product and store result in a temporary buffer. */ 47. sum += ((q63_t) *pSrcA++ * *pSrcB++) >> 14U; 48. 49. /* Decrement loop counter */ 50. blkCnt--; 51. } 52. 53. /* Store result in destination buffer in 16.48 format */ 54. *result = sum; 55. }
函数描述:
这个函数用于求32位定点数的点乘。
函数解析:
- 第10到35行,实现四个为一组进行计数,好处是加快执行速度,降低while循环占用时间。
- 第42到51行,四个为一组剩余数据的处理或者不采用四个为一组时数据处理。
- 两个Q31格式的32位数相乘,那么输出结果的格式是1.31*1.31 = 2.62。实际应用中基本不需要这么高的精度,这个函数将低14位的数据截取掉,反应在函数中就是两个数的乘积左移14位,也就是定点数的小数点也左移14位,那么最终的结果的格式是16.48。所以只要乘累加的个数小于2^16就没有输出结果溢出的危险。
函数参数:
- 第1个参数是乘数地址。
- 第2个参数是被乘数地址。
- 第3个参数是定点数个数,其实就是执行点乘的次数。
- 第4个参数是结果地址。
11.5.3 函数arm_dot_prod_q15
函数原型:
1. void arm_dot_prod_q15( 2. const q15_t * pSrcA, 3. const q15_t * pSrcB, 4. uint32_t blockSize, 5. q63_t * result) 6. { 7. uint32_t blkCnt; /* Loop counter */ 8. q63_t sum = 0; /* Temporary return variable */ 9. 10. #if defined (ARM_MATH_LOOPUNROLL) 11. 12. /* Loop unrolling: Compute 4 outputs at a time */ 13. blkCnt = blockSize >> 2U; 14. 15. while (blkCnt > 0U) 16. { 17. /* C = A[0]* B[0] + A[1]* B[1] + A[2]* B[2] + .....+ A[blockSize-1]* B[blockSize-1] */ 18. 19. #if defined (ARM_MATH_DSP) 20. /* Calculate dot product and store result in a temporary buffer. */ 21. sum = __SMLALD(read_q15x2_ia ((q15_t **) &pSrcA), read_q15x2_ia ((q15_t **) &pSrcB), sum); 22. sum = __SMLALD(read_q15x2_ia ((q15_t **) &pSrcA), read_q15x2_ia ((q15_t **) &pSrcB), sum); 23. #else 24. sum += (q63_t)((q31_t) *pSrcA++ * *pSrcB++); 25. sum += (q63_t)((q31_t) *pSrcA++ * *pSrcB++); 26. sum += (q63_t)((q31_t) *pSrcA++ * *pSrcB++); 27. sum += (q63_t)((q31_t) *pSrcA++ * *pSrcB++); 28. #endif 29. 30. /* Decrement loop counter */ 31. blkCnt--; 32. } 33. 34. /* Loop unrolling: Compute remaining outputs */ 35. blkCnt = blockSize % 0x4U; 36. 37. #else 38. 39. /* Initialize blkCnt with number of samples */ 40. blkCnt = blockSize; 41. 42. #endif /* #if defined (ARM_MATH_LOOPUNROLL) */ 43. 44. while (blkCnt > 0U) 45. { 46. /* C = A[0]* B[0] + A[1]* B[1] + A[2]* B[2] + .....+ A[blockSize-1]* B[blockSize-1] */ 47. 48. /* Calculate dot product and store result in a temporary buffer. */ 49. //#if defined (ARM_MATH_DSP) 50. // sum = __SMLALD(*pSrcA++, *pSrcB++, sum); 51. //#else 52. sum += (q63_t)((q31_t) *pSrcA++ * *pSrcB++); 53. //#endif 54. 55. /* Decrement loop counter */ 56. blkCnt--; 57. } 58. 59. /* Store result in destination buffer in 34.30 format */ 60. *result = sum; 61. }
函数描述:
这个函数用于求32位定点数的点乘。
函数解析:
- 第10到37行,实现四个为一组进行计数,好处是加快执行速度,降低while循环占用时间。
- 第44到57行,四个为一组剩余数据的处理或者不采用四个为一组时数据处理。
- 两个Q15格式的数据相乘,那么输出结果的格式是1.15*1.15 = 2.30,这个函数将输出结果赋值给了64位变量,那么输出结果就是34.30格式。所以基本没有溢出的危险。
- __SMLALD也是SIMD指令,实现两个16位数相乘,并把结果累加给64位变量。
函数参数:
- 第1个参数是乘数地址。
- 第2个参数是被乘数地址。
- 第3个参数是定点数个数,其实就是执行点乘的次数。
- 第4个参数是结果地址。
11.5.4 函数arm_dot_prod_q7
函数原型:
1. void arm_dot_prod_q7( 2. const q7_t * pSrcA, 3. const q7_t * pSrcB, 4. uint32_t blockSize, 5. q31_t * result) 6. { 7. uint32_t blkCnt; /* Loop counter */ 8. q31_t sum = 0; /* Temporary return variable */ 9. 10. #if defined (ARM_MATH_LOOPUNROLL) 11. 12. #if defined (ARM_MATH_DSP) 13. q31_t input1, input2; /* Temporary variables */ 14. q31_t inA1, inA2, inB1, inB2; /* Temporary variables */ 15. #endif 16. 17. /* Loop unrolling: Compute 4 outputs at a time */ 18. blkCnt = blockSize >> 2U; 19. 20. while (blkCnt > 0U) 21. { 22. /* C = A[0]* B[0] + A[1]* B[1] + A[2]* B[2] + .....+ A[blockSize-1]* B[blockSize-1] */ 23. 24. #if defined (ARM_MATH_DSP) 25. /* read 4 samples at a time from sourceA */ 26. input1 = read_q7x4_ia ((q7_t **) &pSrcA); 27. /* read 4 samples at a time from sourceB */ 28. input2 = read_q7x4_ia ((q7_t **) &pSrcB); 29. 30. /* extract two q7_t samples to q15_t samples */ 31. inA1 = __SXTB16(__ROR(input1, 8)); 32. /* extract reminaing two samples */ 33. inA2 = __SXTB16(input1); 34. /* extract two q7_t samples to q15_t samples */ 35. inB1 = __SXTB16(__ROR(input2, 8)); 36. /* extract reminaing two samples */ 37. inB2 = __SXTB16(input2); 38. 39. /* multiply and accumulate two samples at a time */ 40. sum = __SMLAD(inA1, inB1, sum); 41. sum = __SMLAD(inA2, inB2, sum); 42. #else 43. sum += (q31_t) ((q15_t) *pSrcA++ * *pSrcB++); 44. sum += (q31_t) ((q15_t) *pSrcA++ * *pSrcB++); 45. sum += (q31_t) ((q15_t) *pSrcA++ * *pSrcB++); 46. sum += (q31_t) ((q15_t) *pSrcA++ * *pSrcB++); 47. #endif 48. 49. /* Decrement loop counter */ 50. blkCnt--; 51. } 52. 53. /* Loop unrolling: Compute remaining outputs */ 54. blkCnt = blockSize % 0x4U; 55. 56. #else 57. 58. /* Initialize blkCnt with number of samples */ 59. blkCnt = blockSize; 60. 61. #endif /* #if defined (ARM_MATH_LOOPUNROLL) */ 62. 63. while (blkCnt > 0U) 64. { 65. /* C = A[0]* B[0] + A[1]* B[1] + A[2]* B[2] + .....+ A[blockSize-1]* B[blockSize-1] */ 66. 67. /* Calculate dot product and store result in a temporary buffer. */ 68. //#if defined (ARM_MATH_DSP) 69. // sum = __SMLAD(*pSrcA++, *pSrcB++, sum); 70. //#else 71. sum += (q31_t) ((q15_t) *pSrcA++ * *pSrcB++); 72. //#endif 73. 74. /* Decrement loop counter */ 75. blkCnt--; 76. } 77. 78. /* Store result in destination buffer in 18.14 format */ 79. *result = sum; 80. }
函数描述:
这个函数用于求8位定点数的点乘。
函数解析:
- 第10到56行,实现四个为一组进行计数,好处是加快执行速度,降低while循环占用时间。
- 第63到76行,四个为一组剩余数据的处理或者不采用四个为一组时数据处理。
- 两个Q8格式的数据相乘,那么输出结果就是1.7*1.7 = 2.14格式。这里将最终结果赋值给了32位的变量,那么最终的格式就是18.14。如果乘累加的个数小于2^18那么就不会有溢出的危险。
- __SXTB16也是SIMD指令,用于将两个8位的有符号数扩展成16位。__ROR用于实现数据的循环右移。
- __SMLAD也是SIMD指令,用于实现如下功能:
sum = __SMLAD(x, y, z)
sum = z + ((short)(x>>16) * (short)(y>>16)) + ((short)x * (short)y)
函数参数:
- 第1个参数是乘数地址。
- 第2个参数是被乘数地址。
- 第3个参数是定点数个数,其实就是执行点乘的次数。
- 第4个参数是结果地址。
11.5.5 使用举例
程序设计:
/* ********************************************************************************************************* * 函 数 名: DSP_DotProduct * 功能说明: 点乘 * 形 参: 无 * 返 回 值: 无 ********************************************************************************************************* */ static void DSP_DotProduct(void) { float32_t pSrcA[5] = {1.0f,1.0f,1.0f,1.0f,1.0f}; float32_t pSrcB[5] = {1.0f,1.0f,1.0f,1.0f,1.0f}; float32_t result; q31_t pSrcA1[5] = {0x7ffffff0,1,1,1,1}; q31_t pSrcB1[5] = {1,1,1,1,1}; q63_t result1; q15_t pSrcA2[5] = {1,1,1,1,1}; q15_t pSrcB2[5] = {1,1,1,1,1}; q63_t result2; q7_t pSrcA3[5] = {1,1,1,1,1}; q7_t pSrcB3[5] = {1,1,1,1,1}; q31_t result3; /*求点乘*********************************/ arm_dot_prod_f32(pSrcA, pSrcB, 5, &result); printf("arm_dot_prod_f32 = %f ", result); arm_dot_prod_q31(pSrcA1, pSrcB1, 5, &result1); printf("arm_dot_prod_q31 = %lld ", result1); arm_dot_prod_q15(pSrcA2, pSrcB2, 5, &result2); printf("arm_dot_prod_q15 = %lld ", result2); arm_dot_prod_q7(pSrcA3, pSrcB3, 5, &result3); printf("arm_dot_prod_q7 = %d ", result3); printf("*********************************** "); }
实验现象:
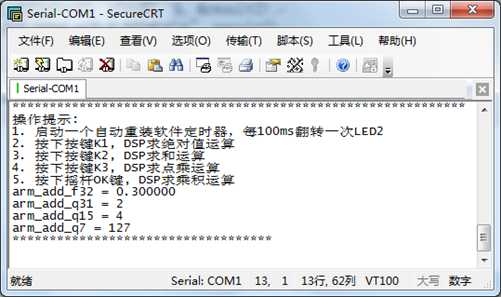
11.6 乘法(Vector Multiplication)
这部分函数主要用于乘法,公式描述如下:
pDst[n] = pSrcA[n] * pSrcB[n], 0 <= n < blockSize.
11.6.1 函数arm_mult_f32
函数原型:
1. void arm_mult_f32( 2. const float32_t * pSrcA, 3. const float32_t * pSrcB, 4. float32_t * pDst, 5. uint32_t blockSize) 6. { 7. uint32_t blkCnt; /* Loop counter */ 8. 9. #if defined(ARM_MATH_NEON) 10. float32x4_t vec1; 11. float32x4_t vec2; 12. float32x4_t res; 13. 14. /* Compute 4 outputs at a time */ 15. blkCnt = blockSize >> 2U; 16. 17. while (blkCnt > 0U) 18. { 19. /* C = A * B */ 20. 21. /* Multiply the inputs and then store the results in the destination buffer. */ 22. vec1 = vld1q_f32(pSrcA); 23. vec2 = vld1q_f32(pSrcB); 24. res = vmulq_f32(vec1, vec2); 25. vst1q_f32(pDst, res); 26. 27. /* Increment pointers */ 28. pSrcA += 4; 29. pSrcB += 4; 30. pDst += 4; 31. 32. /* Decrement the loop counter */ 33. blkCnt--; 34. } 35. 36. /* Tail */ 37. blkCnt = blockSize & 0x3; 38. 39. #else 40. #if defined (ARM_MATH_LOOPUNROLL) 41. 42. /* Loop unrolling: Compute 4 outputs at a time */ 43. blkCnt = blockSize >> 2U; 44. 45. while (blkCnt > 0U) 46. { 47. /* C = A * B */ 48. 49. /* Multiply inputs and store result in destination buffer. */ 50. *pDst++ = (*pSrcA++) * (*pSrcB++); 51. 52. *pDst++ = (*pSrcA++) * (*pSrcB++); 53. 54. *pDst++ = (*pSrcA++) * (*pSrcB++); 55. 56. *pDst++ = (*pSrcA++) * (*pSrcB++); 57. 58. /* Decrement loop counter */ 59. blkCnt--; 60. } 61. 62. /* Loop unrolling: Compute remaining outputs */ 63. blkCnt = blockSize % 0x4U; 64. 65. #else 66. 67. /* Initialize blkCnt with number of samples */ 68. blkCnt = blockSize; 69. 70. #endif /* #if defined (ARM_MATH_LOOPUNROLL) */ 71. #endif /* #if defined(ARM_MATH_NEON) */ 72. 73. while (blkCnt > 0U) 74. { 75. /* C = A * B */ 76. 77. /* Multiply input and store result in destination buffer. */ 78. *pDst++ = (*pSrcA++) * (*pSrcB++); 79. 80. /* Decrement loop counter */ 81. blkCnt--; 82. } 83. 84. }
函数描述:
这个函数用于求32位浮点数的乘法。
函数解析:
- 第9到39行,用于NEON指令集,当前的CM内核不支持。
- 第40到65行,实现四个为一组进行计数,好处是加快执行速度,降低while循环占用时间。
- 第73到82行,四个为一组剩余数据的处理或者不采用四个为一组时数据处理。
函数参数:
- 第1个参数是乘数地址。
- 第2个参数是被乘数地址。
- 第3个参数是结果地址。
- 第4个参数是数据块大小,其实就是执行乘法的次数。
11.6.2 函数arm_mult_q31
函数原型:
1. void arm_mult_q31( 2. const q31_t * pSrcA, 3. const q31_t * pSrcB, 4. q31_t * pDst, 5. uint32_t blockSize) 6. { 7. uint32_t blkCnt; /* Loop counter */ 8. q31_t out; /* Temporary output variable */ 9. 10. #if defined (ARM_MATH_LOOPUNROLL) 11. 12. /* Loop unrolling: Compute 4 outputs at a time */ 13. blkCnt = blockSize >> 2U; 14. 15. while (blkCnt > 0U) 16. { 17. /* C = A * B */ 18. 19. /* Multiply inputs and store result in destination buffer. */ 20. out = ((q63_t) *pSrcA++ * *pSrcB++) >> 32; 21. out = __SSAT(out, 31); 22. *pDst++ = out << 1U; 23. 24. out = ((q63_t) *pSrcA++ * *pSrcB++) >> 32; 25. out = __SSAT(out, 31); 26. *pDst++ = out << 1U; 27. 28. out = ((q63_t) *pSrcA++ * *pSrcB++) >> 32; 29. out = __SSAT(out, 31); 30. *pDst++ = out << 1U; 31. 32. out = ((q63_t) *pSrcA++ * *pSrcB++) >> 32; 33. out = __SSAT(out, 31); 34. *pDst++ = out << 1U; 35. 36. /* Decrement loop counter */ 37. blkCnt--; 38. } 39. 40. /* Loop unrolling: Compute remaining outputs */ 41. blkCnt = blockSize % 0x4U; 42. 43. #else 44. 45. /* Initialize blkCnt with number of samples */ 46. blkCnt = blockSize; 47. 48. #endif /* #if defined (ARM_MATH_LOOPUNROLL) */ 49. 50. while (blkCnt > 0U) 51. { 52. /* C = A * B */ 53. 54. /* Multiply inputs and store result in destination buffer. */ 55. out = ((q63_t) *pSrcA++ * *pSrcB++) >> 32; 56. out = __SSAT(out, 31); 57. *pDst++ = out << 1U; 58. 59. /* Decrement loop counter */ 60. blkCnt--; 61. } 62. 63. }
函数描述:
这个函数用于求32位定点数的乘法。
函数解析:
- 这个函数使用了饱和运算__SSAT,所得结果是Q31格式,范围Q31 range[0x80000000 0x7FFFFFFF]
- 第10到43行,实现四个为一组进行计数,好处是加快执行速度,降低while循环占用时间。
- 第50到61行,四个为一组剩余数据的处理或者不采用四个为一组时数据处理。
- 第20行,所得乘积左移32位。
- 第21行,实现31位精度的饱和运算。
- 第22行,右移一位,保证所得结果是Q31格式。
函数参数:
- 第1个参数是乘数地址。
- 第2个参数是被乘数地址。
- 第3个参数是结果地址。
- 第4个参数是数据块大小,其实就是执行乘法的次数。
11.6.3 函数arm_mult_q15
函数原型:
1. void arm_mult_q15( 2. const q15_t * pSrcA, 3. const q15_t * pSrcB, 4. q15_t * pDst, 5. uint32_t blockSize) 6. { 7. uint32_t blkCnt; /* Loop counter */ 8. 9. #if defined (ARM_MATH_LOOPUNROLL) 10. 11. #if defined (ARM_MATH_DSP) 12. q31_t inA1, inA2, inB1, inB2; /* Temporary input variables */ 13. q15_t out1, out2, out3, out4; /* Temporary output variables */ 14. q31_t mul1, mul2, mul3, mul4; /* Temporary variables */ 15. #endif 16. 17. /* Loop unrolling: Compute 4 outputs at a time */ 18. blkCnt = blockSize >> 2U; 19. 20. while (blkCnt > 0U) 21. { 22. /* C = A * B */ 23. 24. #if defined (ARM_MATH_DSP) 25. /* read 2 samples at a time from sourceA */ 26. inA1 = read_q15x2_ia ((q15_t **) &pSrcA); 27. /* read 2 samples at a time from sourceB */ 28. inB1 = read_q15x2_ia ((q15_t **) &pSrcB); 29. /* read 2 samples at a time from sourceA */ 30. inA2 = read_q15x2_ia ((q15_t **) &pSrcA); 31. /* read 2 samples at a time from sourceB */ 32. inB2 = read_q15x2_ia ((q15_t **) &pSrcB); 33. 34. /* multiply mul = sourceA * sourceB */ 35. mul1 = (q31_t) ((q15_t) (inA1 >> 16) * (q15_t) (inB1 >> 16)); 36. mul2 = (q31_t) ((q15_t) (inA1 ) * (q15_t) (inB1 )); 37. mul3 = (q31_t) ((q15_t) (inA2 >> 16) * (q15_t) (inB2 >> 16)); 38. mul4 = (q31_t) ((q15_t) (inA2 ) * (q15_t) (inB2 )); 39. 40. /* saturate result to 16 bit */ 41. out1 = (q15_t) __SSAT(mul1 >> 15, 16); 42. out2 = (q15_t) __SSAT(mul2 >> 15, 16); 43. out3 = (q15_t) __SSAT(mul3 >> 15, 16); 44. out4 = (q15_t) __SSAT(mul4 >> 15, 16); 45. 46. /* store result to destination */ 47. #ifndef ARM_MATH_BIG_ENDIAN 48. write_q15x2_ia (&pDst, __PKHBT(out2, out1, 16)); 49. write_q15x2_ia (&pDst, __PKHBT(out4, out3, 16)); 50. #else 51. write_q15x2_ia (&pDst, __PKHBT(out1, out2, 16)); 52. write_q15x2_ia (&pDst, __PKHBT(out3, out4, 16)); 53. #endif /* #ifndef ARM_MATH_BIG_ENDIAN */ 54. 55. #else 56. *pDst++ = (q15_t) __SSAT((((q31_t) (*pSrcA++) * (*pSrcB++)) >> 15), 16); 57. *pDst++ = (q15_t) __SSAT((((q31_t) (*pSrcA++) * (*pSrcB++)) >> 15), 16); 58. *pDst++ = (q15_t) __SSAT((((q31_t) (*pSrcA++) * (*pSrcB++)) >> 15), 16); 59. *pDst++ = (q15_t) __SSAT((((q31_t) (*pSrcA++) * (*pSrcB++)) >> 15), 16); 60. #endif 61. 62. /* Decrement loop counter */ 63. blkCnt--; 64. } 65. 66. /* Loop unrolling: Compute remaining outputs */ 67. blkCnt = blockSize % 0x4U; 68. 69. #else 70. 71. /* Initialize blkCnt with number of samples */ 72. blkCnt = blockSize; 73. 74. #endif /* #if defined (ARM_MATH_LOOPUNROLL) */ 75. 76. while (blkCnt > 0U) 77. { 78. /* C = A * B */ 79. 80. /* Multiply inputs and store result in destination buffer. */ 81. *pDst++ = (q15_t) __SSAT((((q31_t) (*pSrcA++) * (*pSrcB++)) >> 15), 16); 82. 83. /* Decrement loop counter */ 84. blkCnt--; 85. } 86. 87. }
函数描述:
这个函数用于求16位定点数的乘法。
函数解析:
- 这个函数使用了饱和运算__SSAT,所得结果是Q31格式,范围Q31 range[0x80000000 0x7FFFFFFF]。
- 第9到69行,实现四个为一组进行计数,好处是加快执行速度,降低while循环占用时间。
- 第79到85行,四个为一组剩余数据的处理或者不采用四个为一组时数据处理。
- 第26行,一次读取两个Q15格式的数据。
- 第35到38行,将四组数的乘积保存到Q31格式的变量mul1,mul2,mul3,mul4。
- 第41到44行,丢弃32位数据的低15位,并把最终结果饱和到16位精度。
- 第51到52行的SIMD指令__PKHBT,将两个Q15格式的数据保存的结果数组中,从而一个指令周期就能完成两个数据的存储。
函数参数:
- 第1个参数是乘数地址。
- 第2个参数是被乘数地址。
- 第3个参数是结果地址。
- 第4个参数是数据块大小,其实就是执行乘法的次数。
11.6.4 函数arm_mult_q7
函数原型:
1. void arm_mult_q7( 2. const q7_t * pSrcA, 3. const q7_t * pSrcB, 4. q7_t * pDst, 5. uint32_t blockSize) 6. { 7. uint32_t blkCnt; /* Loop counter */ 8. 9. #if defined (ARM_MATH_LOOPUNROLL) 10. 11. #if defined (ARM_MATH_DSP) 12. q7_t out1, out2, out3, out4; /* Temporary output variables */ 13. #endif 14. 15. /* Loop unrolling: Compute 4 outputs at a time */ 16. blkCnt = blockSize >> 2U; 17. 18. while (blkCnt > 0U) 19. { 20. /* C = A * B */ 21. 22. #if defined (ARM_MATH_DSP) 23. /* Multiply inputs and store results in temporary variables */ 24. out1 = (q7_t) __SSAT((((q15_t) (*pSrcA++) * (*pSrcB++)) >> 7), 8); 25. out2 = (q7_t) __SSAT((((q15_t) (*pSrcA++) * (*pSrcB++)) >> 7), 8); 26. out3 = (q7_t) __SSAT((((q15_t) (*pSrcA++) * (*pSrcB++)) >> 7), 8); 27. out4 = (q7_t) __SSAT((((q15_t) (*pSrcA++) * (*pSrcB++)) >> 7), 8); 28. 29. /* Pack and store result in destination buffer (in single write) */ 30. write_q7x4_ia (&pDst, __PACKq7(out1, out2, out3, out4)); 31. #else 32. *pDst++ = (q7_t) __SSAT((((q15_t) (*pSrcA++) * (*pSrcB++)) >> 7), 8); 33. *pDst++ = (q7_t) __SSAT((((q15_t) (*pSrcA++) * (*pSrcB++)) >> 7), 8); 34. *pDst++ = (q7_t) __SSAT((((q15_t) (*pSrcA++) * (*pSrcB++)) >> 7), 8); 35. *pDst++ = (q7_t) __SSAT((((q15_t) (*pSrcA++) * (*pSrcB++)) >> 7), 8); 36. #endif 37. 38. /* Decrement loop counter */ 39. blkCnt--; 40. } 41. 42. /* Loop unrolling: Compute remaining outputs */ 43. blkCnt = blockSize % 0x4U; 44. 45. #else 46. 47. /* Initialize blkCnt with number of samples */ 48. blkCnt = blockSize; 49. 50. #endif /* #if defined (ARM_MATH_LOOPUNROLL) */ 51. 52. while (blkCnt > 0U) 53. { 54. /* C = A * B */ 55. 56. /* Multiply input and store result in destination buffer. */ 57. *pDst++ = (q7_t) __SSAT((((q15_t) (*pSrcA++) * (*pSrcB++)) >> 7), 8); 58. 59. /* Decrement loop counter */ 60. blkCnt--; 61. } 62. 63. }
函数描述:
这个函数用于求8位定点数的乘法。
函数解析:
- 这个函数使用了饱和算法__SSAT,所得结果是Q7格式,范围 [0x80 0x7F]
- 第9到45行,实现四个为一组进行计数,好处是加快执行速度,降低while循环占用时间。
- 第52到61行,四个为一组剩余数据的处理或者不采用四个为一组时数据处理。
- 第24到27行,将两个Q7格式的数据乘积左移7位,也就是丢掉低7位的数据,并将所得结果饱和到8位精度。
- 第30行,__PACKq7函数可以在一个时钟周期就能完成相应操作。
函数参数:
- 第1个参数是乘数地址。
- 第2个参数是被乘数地址。
- 第3个参数是结果地址。
- 第4个参数是数据块大小,其实就是执行乘法的次数。
11.6.5 使用举例
程序设计:
/* ********************************************************************************************************* * 函 数 名: DSP_Multiplication * 功能说明: 乘法 * 形 参: 无 * 返 回 值: 无 ********************************************************************************************************* */ static void DSP_Multiplication(void) { float32_t pSrcA[5] = {1.0f,1.0f,1.0f,1.0f,1.0f}; float32_t pSrcB[5] = {1.0f,1.0f,1.0f,1.0f,1.0f}; float32_t pDst[5]; q31_t pSrcA1[5] = {1,1,1,1,1}; q31_t pSrcB1[5] = {1,1,1,1,1}; q31_t pDst1[5]; q15_t pSrcA2[5] = {1,1,1,1,1}; q15_t pSrcB2[5] = {1,1,1,1,1}; q15_t pDst2[5]; q7_t pSrcA3[5] = {0x70,1,1,1,1}; q7_t pSrcB3[5] = {0x7f,1,1,1,1}; q7_t pDst3[5]; /*求乘积*********************************/ pSrcA[0] += 1.1f; arm_mult_f32(pSrcA, pSrcB, pDst, 5); printf("arm_mult_f32 = %f ", pDst[0]); pSrcA1[0] += 1; arm_mult_q31(pSrcA1, pSrcB1, pDst1, 5); printf("arm_mult_q31 = %d ", pDst1[0]); pSrcA2[0] += 1; arm_mult_q15(pSrcA2, pSrcB2, pDst2, 5); printf("arm_mult_q15 = %d ", pDst2[0]); pSrcA3[0] += 1; arm_mult_q7(pSrcA3, pSrcB3, pDst3, 5); printf("arm_mult_q7 = %d ", pDst3[0]); printf("*********************************** "); }
实验现象:
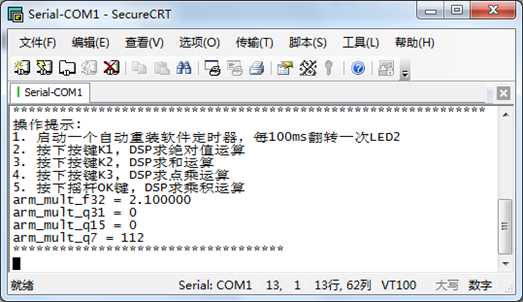
这里特别注意为什么Q31和Q15结算的输出结果会有0,关于这个问题,在此贴进行了详细说明:
http://www.armbbs.cn/forum.php?mod=viewthread&tid=95194。
11.7 实验例程说明(MDK)
配套例子:
V5-206_DSP基础运算(绝对值,求和,乘法和点乘)
实验目的:
- 学习基础运算(绝对值,求和,乘法和点乘)。
实验内容:
- 启动一个自动重装软件定时器,每100ms翻转一次LED2。
- 按下按键K1, DSP求绝对值运算。
- 按下按键K2, DSP求和运算。
- 按下按键K3, DSP求点乘运算。
- 按下摇杆OK键, DSP求乘积运算。
使用AC6注意事项
特别注意附件章节C的问题
上电后串口打印的信息:
波特率 115200,数据位 8,奇偶校验位无,停止位 1。
详见本章的4.5,5.5和6.5小节。
程序设计:
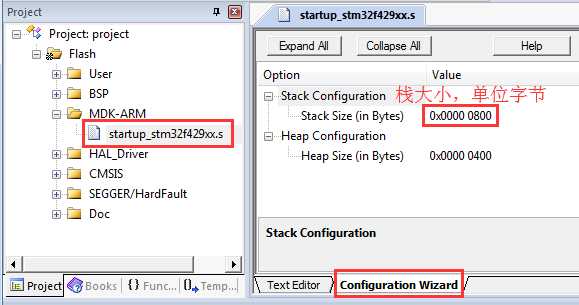
系统栈大小分配:
硬件外设初始化
硬件外设的初始化是在 bsp.c 文件实现:
/* ********************************************************************************************************* * 函 数 名: bsp_Init * 功能说明: 初始化所有的硬件设备。该函数配置CPU寄存器和外设的寄存器并初始化一些全局变量。只需要调用一次 * 形 参:无 * 返 回 值: 无 ********************************************************************************************************* */ void bsp_Init(void) { /* STM32F407 HAL 库初始化,此时系统用的还是F407自带的16MHz,HSI时钟: - 调用函数HAL_InitTick,初始化滴答时钟中断1ms。 - 设置NVIV优先级分组为4。 */ HAL_Init(); /* 配置系统时钟到168MHz - 切换使用HSE。 - 此函数会更新全局变量SystemCoreClock,并重新配置HAL_InitTick。 */ SystemClock_Config(); /* Event Recorder: - 可用于代码执行时间测量,MDK5.25及其以上版本才支持,IAR不支持。 - 默认不开启,如果要使能此选项,务必看V5开发板用户手册第8章 */ #if Enable_EventRecorder == 1 /* 初始化EventRecorder并开启 */ EventRecorderInitialize(EventRecordAll, 1U); EventRecorderStart(); #endif bsp_InitKey(); /* 按键初始化,要放在滴答定时器之前,因为按钮检测是通过滴答定时器扫描 */ bsp_InitTimer(); /* 初始化滴答定时器 */ bsp_InitUart(); /* 初始化串口 */ bsp_InitLed(); /* 初始化LED */ bsp_InitESP8266(); /* 配置ESP8266模块相关的资源 */ }
主功能:
主程序实现如下操作:
- 按下按键K1, DSP求绝对值运算。
- 按下按键K2, DSP求和运算。
- 按下按键K3, DSP求点乘运算。
- 按下摇杆OK键, DSP求乘积运算。
/* ********************************************************************************************************* * 函 数 名: main * 功能说明: c程序入口 * 形 参: 无 * 返 回 值: 错误代码(无需处理) ********************************************************************************************************* */ int main(void) { uint8_t ucKeyCode; /* 按键代码 */ uint8_t ucValue; bsp_Init(); /* 硬件初始化 */ PrintfLogo(); /* 打印例程信息到串口1 */ PrintfHelp(); /* 打印操作提示信息 */ bsp_StartAutoTimer(0, 100); /* 启动1个100ms的自动重装的定时器 */ /* 进入主程序循环体 */ while (1) { bsp_Idle(); /* 这个函数在bsp.c文件。用户可以修改这个函数实现CPU休眠和喂狗 */ /* 判断定时器超时时间 */ if (bsp_CheckTimer(0)) { /* 每隔100ms 进来一次 */ bsp_LedToggle(2); } ucKeyCode = bsp_GetKey(); /* 读取键值, 无键按下时返回 KEY_NONE = 0 */ if (ucKeyCode != KEY_NONE) { switch (ucKeyCode) { case KEY_DOWN_K1: /* K1键按下,求绝对值 */ DSP_ABS(); break; case KEY_DOWN_K2: /* K2键按下, 求和 */ DSP_Add(); break; case KEY_DOWN_K3: /* K3键按下,求点乘 */ DSP_DotProduct(); break; case JOY_DOWN_OK: /* 摇杆OK键按下,求乘积 */ DSP_Multiplication(); break; default: /* 其他的键值不处理 */ break; } } } }
11.8 实验例程说明(IAR)
配套例子:
V5-206_DSP基础运算(绝对值,求和,乘法和点乘)
实验目的:
- 学习基础运算(绝对值,求和,乘法和点乘)。
实验内容:
- 启动一个自动重装软件定时器,每100ms翻转一次LED2。
- 按下按键K1, DSP求绝对值运算。
- 按下按键K2, DSP求和运算。
- 按下按键K3, DSP求点乘运算。
- 按下摇杆OK键, DSP求乘积运算。
上电后串口打印的信息:
波特率 115200,数据位 8,奇偶校验位无,停止位 1。
详见本章的4.5,5.5和6.5小节。
程序设计:
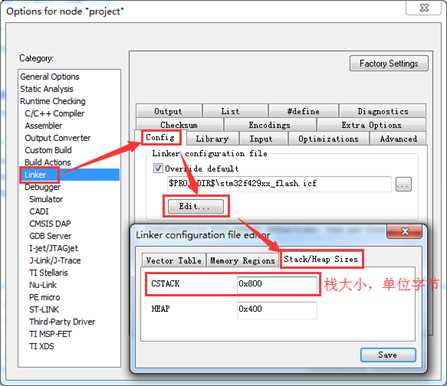
系统栈大小分配:
硬件外设初始化
硬件外设的初始化是在 bsp.c 文件实现:
/* ********************************************************************************************************* * 函 数 名: bsp_Init * 功能说明: 初始化所有的硬件设备。该函数配置CPU寄存器和外设的寄存器并初始化一些全局变量。只需要调用一次 * 形 参:无 * 返 回 值: 无 ********************************************************************************************************* */ void bsp_Init(void) { /* STM32F407 HAL 库初始化,此时系统用的还是F407自带的16MHz,HSI时钟: - 调用函数HAL_InitTick,初始化滴答时钟中断1ms。 - 设置NVIV优先级分组为4。 */ HAL_Init(); /* 配置系统时钟到168MHz - 切换使用HSE。 - 此函数会更新全局变量SystemCoreClock,并重新配置HAL_InitTick。 */ SystemClock_Config(); /* Event Recorder: - 可用于代码执行时间测量,MDK5.25及其以上版本才支持,IAR不支持。 - 默认不开启,如果要使能此选项,务必看V5开发板用户手册第8章 */ #if Enable_EventRecorder == 1 /* 初始化EventRecorder并开启 */ EventRecorderInitialize(EventRecordAll, 1U); EventRecorderStart(); #endif bsp_InitKey(); /* 按键初始化,要放在滴答定时器之前,因为按钮检测是通过滴答定时器扫描 */ bsp_InitTimer(); /* 初始化滴答定时器 */ bsp_InitUart(); /* 初始化串口 */ bsp_InitExtIO(); /* 初始化扩展IO */ bsp_InitLed(); /* 初始化LED */ }
主功能:
主程序实现如下操作:
- 按下按键K1, DSP求绝对值运算。
- 按下按键K2, DSP求和运算。
- 按下按键K3, DSP求点乘运算。
- 按下摇杆OK键, DSP求乘积运算。
/* ********************************************************************************************************* * 函 数 名: main * 功能说明: c程序入口 * 形 参: 无 * 返 回 值: 错误代码(无需处理) ********************************************************************************************************* */ int main(void) { uint8_t ucKeyCode; /* 按键代码 */ uint8_t ucValue; bsp_Init(); /* 硬件初始化 */ PrintfLogo(); /* 打印例程信息到串口1 */ PrintfHelp(); /* 打印操作提示信息 */ bsp_StartAutoTimer(0, 100); /* 启动1个100ms的自动重装的定时器 */ /* 进入主程序循环体 */ while (1) { bsp_Idle(); /* 这个函数在bsp.c文件。用户可以修改这个函数实现CPU休眠和喂狗 */ /* 判断定时器超时时间 */ if (bsp_CheckTimer(0)) { /* 每隔100ms 进来一次 */ bsp_LedToggle(2); } ucKeyCode = bsp_GetKey(); /* 读取键值, 无键按下时返回 KEY_NONE = 0 */ if (ucKeyCode != KEY_NONE) { switch (ucKeyCode) { case KEY_DOWN_K1: /* K1键按下,求绝对值 */ DSP_ABS(); break; case KEY_DOWN_K2: /* K2键按下, 求和 */ DSP_Add(); break; case KEY_DOWN_K3: /* K3键按下,求点乘 */ DSP_DotProduct(); break; case JOY_DOWN_OK: /* 摇杆OK键按下,求乘积 */ DSP_Multiplication(); break; default: /* 其他的键值不处理 */ break; } } } }
11.9 总结
本期教程就跟大家讲这么多,还是那句话,可以自己写些代码调用本期教程中讲的这几个函数,如果可以的话,可以自己尝试直接调用这些DSP指令。
以上是关于STM32F407的DSP教程第11章 基础函数-绝对值,求和,乘法和点乘的主要内容,如果未能解决你的问题,请参考以下文章
STM32F407的DSP教程第24章 DSP变换运算-傅里叶变换
STM32F407的DSP教程第24章 DSP变换运算-傅里叶变换
STM32F407的DSP教程第17章 DSP功能函数-定点数互转
STM32F407的DSP教程第17章 DSP功能函数-定点数互转