mit6.828 lab2心得
Posted ecjtusbs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mit6.828 lab2心得相关的知识,希望对你有一定的参考价值。
lab2实验总结
lab2为内存管理的部分,涉及的主要内容为对内核页表结构的初始化以及对应管理函数的实现。
理解上的障碍
比较难理解的是内核页对自己所在内存的映射。页表本身存放于物理内存中,访问页目录表、页表的代码所在的物理内存块同样被MMU所管理,这种递归地“自己映射自己”的方式对我造成了理解上的障碍。
对这种理解上障碍的消除,我是这样解决的:忽略它,从更抽象的模型来考虑。我的设想是:按照如下的模型去避免理解时的困惑:
1、页目录表、页表存放在特定的物理内存中,这部分内存不被MMU所管理。
2、对页目录 、页表进行访问的代码存在在单独的内存中,这部分内存不被MMU所管理。
按照以上两个假想规则来重新理解操作系统中的页机制,思维上的困顿之处就可能得到摆脱,专注于从更高层次上考虑操作系统对内存的管理模型。
几个问题
1、内核在物理内存中,是怎样分布的?
由 readelf -l ~/lab/obj/kern/kernel 可知
mit6828@mit6828-VirtualBox:~/lab/obj/kern$ readelf -l kernel
Elf file type is EXEC (Executable file)
Entry point 0x10000c
There are 3 program headers, starting at offset 52
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
LOAD 0x001000 0xf0100000 0x00100000 0x0db1e 0x0db1e R E 0x1000
LOAD 0x00f000 0xf010e000 0x0010e000 0x0b044 0x0b6d0 RW 0x1000
GNU_STACK 0x000000 0x00000000 0x00000000 0x00000 0x00000 RWE 0x10
Section to Segment mapping:
Segment Sections...
00 .text .rodata .stab .stabstr
01 .data .got .got.plt .data.rel.local .data.rel.ro.local .bss
02
由以上得知,内核中的代码段被加载到物理内存的0x00100000地址处,数据段被加载到物理内存的0x0010e000地址处。
2、内核如何访问页目录表、页表的?
在内存初始化阶段,内核为页目录表分配了PGSIZE的内存空间,以kern_pgdir作为页目录表的首地地址,因此在内核的线性地址中,我们可以通过kern_pgdir访问页目录表。那么页目录到底保存在物理内存的哪个区域呢?
从lab/kern/entrypgdir.c中得知,在内核早期初始化阶段所建立的初级页表结构中:虚拟地址[KERNBASE,KERNBASE+4MB]映射到了物理地址[0,4MB]处,虚拟地址[0,4MB]映射到物理地址[0,4MB]。在这套映射机制下,虚拟地址和物理地址的转换关系可以通过宏PADDR(kva)与KADDR(pa)进行转换,本质上是借助(虚拟地址=物理地址+KERNBASE)这一转化关系。
说回到上面那个问题,页目录到底保存在物理内存的哪个区域?
kern_pgdir的逻辑地址由kern_pgdir=(pde_t *)boot_alloc(PGZISE)决定,确定逻辑地址后通过PADDR(kva)即得到系统页目录表对应的物理内存地址。
3、内核是如何对物理页进行管理的?
内核维护了struct PageInfo数组来完成对物理页的管理,在~/lab/kern/pmap.c:mem_init()中,通过如下方式为此数组分配了空间。
144 //////////////////////////////////////////////////////////////////////
145 // Allocate an array of npages ‘struct PageInfo‘s and store it in ‘pages‘.
146 // The kernel uses this array to keep track of physical pages: for
147 // each physical page, there is a corresponding struct PageInfo in this
148 // array. ‘npages‘ is the number of physical pages in memory. Use memset
149 // to initialize all fields of each struct PageInfo to 0.
150 // Your code goes here:
151 //npages由内核在初始化阶段确定,代表物理内存对应的内存页的数量。首先为这一结构分配空间,清空此段内存
152 pages=(struct PageInfo *) boot_alloc(npages*sizeof(struct PageInfo)); 153 memset(pages, 0, npages*sizeof(struct PageInfo));
~/lab/kern/pmap.c:page_init()完成对内存管理机构的初始化。
234 //
235 // Initialize page structure and memory free list.
236 // After this is done, NEVER use boot_alloc again. ONLY use the page
237 // allocator functions below to allocate and deallocate physical
238 // memory via the page_free_list.
239 //
240 void
241 page_init(void)
242 {
243 // The example code here marks all physical pages as free.
244 // However this is not truly the case. What memory is free?
245 // 1) Mark physical page 0 as in use.
246 // This way we preserve the real-mode IDT and Bios structures
247 // in case we ever need them. (Currently we don‘t, but...)
248 // 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE)
249 // is free.
250 // 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must
251 // never be allocated.
252 // 4) Then extended memory [EXTPHYSMEM, ...).
253 // Some of it is in use, some is free. Where is the kernel
254 // in physical memory? Which pages are already in use for
255 // page tables and other data structures?
256 //
257 // Change the code to reflect this.
258 // NB: DO NOT actually touch the physical memory corresponding to
259 // free pages!
260 size_t i;
261
262 size_t io_hole_start=(size_t)IOPHYSMEM / PGSIZE;
263 //size_t io_hole_end=(size_t)EXTPHYSMEM / PGSIZE;
264 //size_t ext_mem_start=(size_t)EXTPHYSMEM/PGSIZE;
265 size_t ext_mem_kernel_end=PADDR(boot_alloc(0))/PGSIZE;
266
267
268 for (i = 0; i < npages; i++) {
269 //0 for idt
270 if( i == 0){
271 pages[i].pp_ref=1;
272 pages[i].pp_link=NULL;
273 }else if(i>=io_hole_start && i<ext_mem_kernel_end){
274 pages[i].pp_ref=1;
275 pages[i].pp_link=NULL;
276 }else{
277 pages[i].pp_ref=0;
278 pages[i].pp_link=page_free_list;
279 page_free_list=&pages[i];
280 }
281 }
282
283 if(page_free_list==NULL){
284 cprintf("[ckw]__page_init page_free_list==NULL");
285 }else{
286 cprintf("[ckw]: page_init page_free_list _ is _%x
",page_free_list);
287
288 }
289
290 }
该函数实现了对struct PageInfo[]的初始化,并且以链表形式记录了内存中所有可用内存。
这里的关键问题是确定当前阶段哪些物理页可用,按源注释的提示,当前物理内存按用途可分为四个部分(以页为单位进行说明):
[0]被当前的IDT所占用,不能被分配,标记为in use[1,npages_basemem]基础内存的的剩余区域,标记为free[IOPHYSMEM/PGSIZE,EXTPHYSMEM/PGSIZE]这部分为IO hole区域,不允许分配[EXTPHYSMEM/PGSIZE,?]内核占用的区域。[?,npages]剩余区域
Q:如何确定当前内核在物理内存中的末尾地址呢?
A: 函数~/kern/pmap.c:boot_alloc(uint32_t n)负责在逻辑空间中的内核末尾处分配指定大小的空间,并返回更新后的指向内核尾部地址的指针,因此通过boot_alloc(0)我们能得到逻辑空间中内核的末尾地址,然后进一步通过PADDR(boot_alloc(0))得到当前内核尾部的实际物理地址。
这样我们知道了当前内存的使用情况,接着更新struct PageInfo数组,并通过尾插法将所有free的页面链接成以page_free_list为表头的链表。
关键代码的理解
搞明白以上几个问题之后,仔细阅读~/lab/kern/mem_init()的代码。
// Set up a two-level page table:
// kern_pgdir is its linear (virtual) address of the root
//
// This function only sets up the kernel part of the address space
// (ie. addresses >= UTOP). The user part of the address space
// will be set up later.
//
// From UTOP to ULIM, the user is allowed to read but not write.
// Above ULIM the user cannot read or write.
void
mem_init(void)
{
uint32_t cr0;
size_t n;
// Find out how much memory the machine has (npages & npages_basemem).
i386_detect_memory();
// Remove this line when you‘re ready to test this function.
//panic("mem_init: This function is not finished
");
//////////////////////////////////////////////////////////////////////
// create initial page directory.
// 为页目录表分配大小为PGSIZE的空间并初始化
kern_pgdir = (pde_t *) boot_alloc(PGSIZE);
memset(kern_pgdir, 0, PGSIZE);
//////////////////////////////////////////////////////////////////////
// Recursively insert PD in itself as a page table, to form
// a virtual page table at virtual address UVPT.
// (For now, you don‘t have understand the greater purpose of the
// following line.)
// Permissions: kernel R, user R
kern_pgdir[PDX(UVPT)] = PADDR(kern_pgdir) | PTE_U | PTE_P;
//////////////////////////////////////////////////////////////////////
// Allocate an array of npages ‘struct PageInfo‘s and store it in ‘pages‘.
// The kernel uses this array to keep track of physical pages: for
// each physical page, there is a corresponding struct PageInfo in this
// array. ‘npages‘ is the number of physical pages in memory. Use memset
// to initialize all fields of each struct PageInfo to 0.
// Your code goes here:
//
// 根据npages的大小,分配大小为npages*sizeof(struct PageInfo)的空间,
// 用来保存struct PageInfo数组,内核用此数组完成对物理页的管理
pages=(struct PageInfo *) boot_alloc(npages*sizeof(struct PageInfo));
memset(pages, 0, npages*sizeof(struct PageInfo));
//////////////////////////////////////////////////////////////////////
// Now that we‘ve allocated the initial kernel data structures, we set
// up the list of free physical pages. Once we‘ve done so, all further
// memory management will go through the page_* functions. In
// particular, we can now map memory using boot_map_region
// or page_insert
//初始化对struct PageInfo数组的管理,根据物理内存的使用情况将所有free的内存块
//对应的struct PageInfo链接成链表,表头为page_free_list。
page_init();
check_page_free_list(1);
check_page_alloc();
check_page();
//////////////////////////////////////////////////////////////////////
// Now we set up virtual memory
//////////////////////////////////////////////////////////////////////
// Map ‘pages‘ read-only by the user at linear address UPAGES
// Permissions:
// - the new image at UPAGES -- kernel R, user R
// (ie. perm = PTE_U | PTE_P)
// - pages itself -- kernel RW, user NONE
// Your code goes here:
// Permissions: kernel R, user R
// 将虚拟地址[UPAGES,UPAGES+PTSIZE]映射到[PADDR(pages),PADDR(pages)+PTSIZZ]
boot_map_region(kern_pgdir,UPAGES,PTSIZE,PADDR(pages),PTE_U);
//////////////////////////////////////////////////////////////////////
// Use the physical memory that ‘bootstack‘ refers to as the kernel
// stack. The kernel stack grows down from virtual address KSTACKTOP.
// We consider the entire range from [KSTACKTOP-PTSIZE, KSTACKTOP)
// to be the kernel stack, but break this into two pieces:
// * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- backed by physical memory
// * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- not backed; so if
// the kernel overflows its stack, it will fault rather than
// overwrite memory. Known as a "guard page".
// Permissions: kernel RW, user NONE
// Your code goes here:
// 将虚拟地址[KSTACKTOP-KSTKSIZE,KSTACKTOP]
// 映射到[PADDR(bootstack),PADDR(bootstack)+KSTKSIZE]
boot_map_region(kern_pgdir,KSTACKTOP-KSTKSIZE,KSTKSIZE,PADDR(bootstack),PTE_W);
//////////////////////////////////////////////////////////////////////
// Map all of physical memory at KERNBASE.
// Ie. the VA range [KERNBASE, 2^32) should map to
// the PA range [0, 2^32 - KERNBASE)
// We might not have 2^32 - KERNBASE bytes of physical memory, but
// we just set up the mapping anyway.
// Permissions: kernel RW, user NONE
// Your code goes here:
boot_map_region(kern_pgdir,KERNBASE,0xffffffff-KERNBASE,0,PTE_W);
// Check that the initial page directory has been set up correctly.
check_kern_pgdir();
// Switch from the minimal entry page directory to the full kern_pgdir
// page table we just created. Our instruction pointer should be
// somewhere between KERNBASE and KERNBASE+4MB right now, which is
// mapped the same way by both page tables.
//
// If the machine reboots at this point, you‘ve probably set up your
// kern_pgdir wrong.
// 启用新的页目录表
lcr3(PADDR(kern_pgdir));
check_page_free_list(0);
// entry.S set the really important flags in cr0 (including enabling
// paging). Here we configure the rest of the flags that we care about.
cr0 = rcr0();
cr0 |= CR0_PE|CR0_PG|CR0_AM|CR0_WP|CR0_NE|CR0_MP;
cr0 &= ~(CR0_TS|CR0_EM);
lcr0(cr0);
// Some more checks, only possible after kern_pgdir is installed.
check_page_installed_pgdir();
}
执行完mem_init()之后,虚拟空间与物理空间的映射关系及空间分配如下所示:
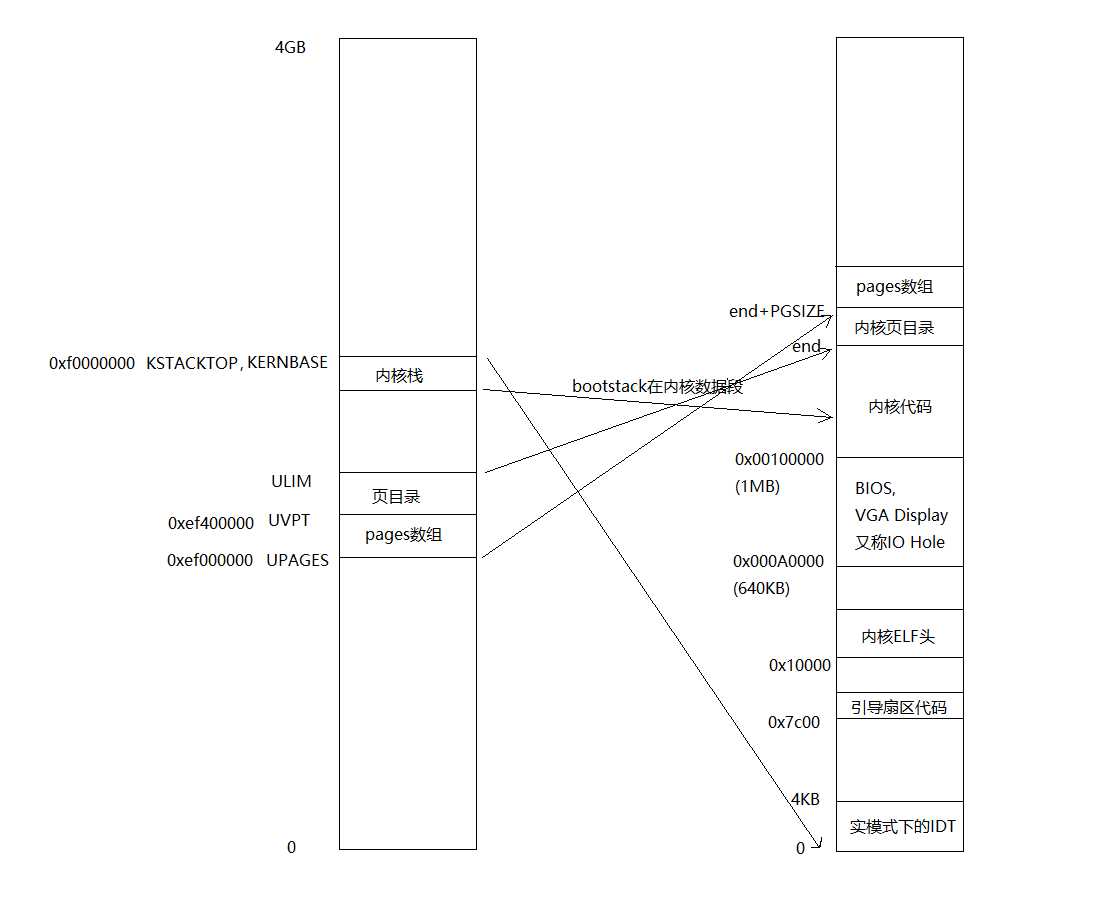
图片来源:https://www.cnblogs.com/gatsby123/p/9832223.html
~/lab/kern/pmap.c:pgdir_walk()
354 // Given ‘pgdir‘, a pointer to a page directory, pgdir_walk returns
355 // a pointer to the page table entry (PTE) for linear address ‘va‘.
356 // This requires walking the two-level page table structure.
357 //
358 // The relevant page table page might not exist yet.
359 // If this is true, and create == false, then pgdir_walk returns NULL.
360 // Otherwise, pgdir_walk allocates a new page table page with page_alloc.
361 // - If the allocation fails, pgdir_walk returns NULL.
362 // - Otherwise, the new page‘s reference count is incremented,
363 // the page is cleared,
364 // and pgdir_walk returns a pointer into the new page table page.
365 //
366 // Hint 1: you can turn a PageInfo * into the physical address of the
367 // page it refers to with page2pa() from kern/pmap.h.
368 //
369 // Hint 2: the x86 MMU checks permission bits in both the page directory
370 // and the page table, so it‘s safe to leave permissions in the page
371 // directory more permissive than strictly necessary.
372 //
373 // Hint 3: look at inc/mmu.h for useful macros that manipulate page
374 // table and page directory entries.
375 //
376 pte_t *
377 pgdir_walk(pde_t *pgdir, const void *va, int create)
378 {
379 // Fill this function in
//找到此地址对应的页目录项 page_dir_entry,PDX(va)为~/lab/inc/mmu.h中定义的线性地址的宏
380 pde_t * entry_va=pgdir+PDX(va);
381 if(!( (*entry_va) & PTE_P )){ // the pgtable is not allocated
382
/**如果当前页目录项对应的页表不存在,那么分配一页内存,用来保存二级页表
对内存的管理,实际由Struct PageInfo[]来完成
**/
383 if(create){//create a PG to store 2-level page_table
384 struct PageInfo * pageinfo =page_alloc(1);
385 if(pageinfo == NULL){
386 return NULL;
387 }
388 pageinfo->pp_ref++;
389
390 //after alloc a page,now we should update the entry_table
//这里需要注意的是,页目录项或页表项中保存的应该是与其对应的物理地址,所以对分配给二级页表的这一页内存的物理地址,由page2pa(pageinfo)获得并保存在页目录项中。page2pa(struct PageInfo * pp)为~/lab/kern/pmap.h中定义的内联函数。
391 *entry_va= (page2pa(pageinfo))|PTE_P|PTE_U|PTE_W;
392 }else{
393 return NULL;
394 }
395 }
396
397 //pte_addr(pte) return the address in page table or page dirctory entry
398 //after that now we want to update the 2-level page table
399 //but we can not directly access the addresss pte_addr(pte) because of the initial mapping
400 //so we case phyaddress to virtual address using KADDR(pa) to access the physical address pte_addr(pte)
401 //return type:virtual address of 2-level page table entry
//执行到这里,说明对应的二级页表已经存在,那么现在只需要按照“在一级页目录中查找page_dir_entry”的方式在二级页表中找到page_table_entry即可。现在的关键问题是:如何访问二级页表?二级页表在物理内存中的位置可以通过PTE_ADDR(pte)得到。但是我们不能以直接的形式访问这块物理内存,为什么呢?因为按照在~/lab/kern/entry.S中设置的初始页表的映射关系。在内核代码中,如果已知所要访问的内存地址pa,那么需要通过KADDR(pa)这样的形式进行转化成kva,转换后的地址kva被mmu映射到物理地址pa处。现在通过KADDR(pa)得到了虚拟地址,KADDR(pa)返回的是void * 类型的指针,因此先转化为(pte_t *)的指针(感谢原作者的友情提示),再按照c语言中的指针引用规则加上PTX(va)得到指向对应page_table_entry的指针。
402 return ((pte_t *)KADDR(PTE_ADDR(*entry_va)))+PTX(va);
403 }
其它
- 内核模块中出现的地址始终为虚拟地址,包括对页目录表地址、页目录表地址的访问均是如此。
- 页目录表、页表中的地址为物理地址。
- 实验过程中一定要注意检查虚拟地址与物理地址之间的转换关系
参考资料
MIT-6.828 Lab 2: Memory Management实验报告: https://www.cnblogs.com/gatsby123/p/9832223.html
以上是关于mit6.828 lab2心得的主要内容,如果未能解决你的问题,请参考以下文章
MIT6.828centos7下使用Qemu搭建xv6运行环境
MIT6.828centos7下使用Qemu搭建xv6运行环境
MIT6.S081/6.828 实验1:Lab Unix Utilities