Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow ——Chapter 1 Machine Learning Land
Posted natty-sky
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow ——Chapter 1 Machine Learning Land相关的知识,希望对你有一定的参考价值。
1.Machine Learning概念:
提到机器学习,很多人会想到机器人管家、终结者等一些不着边际,高大上的事物。实际上,机器学习在很多领域已经存在多年,例如:光学字符识别(OCR)。第一个机器学习应用是垃圾邮件过滤器,随后出现了数百个机器学习程序。本文介绍机器学习的一些重要概念(每位数据科学家都应该清楚):有监督与无监督学习,在线与批处理学习,基于实例与基于模型的学习等等。
机器学习:假设用P来评估计算机程序在某任务类T上的性能,若一个程序通过利用经验E在T中任务上获得了性能改善,则我们就说关于T和P,该程序对E进行了学习。 (Tom Mitchell 1997)
以垃圾邮件过滤器为例来说明这个概念。 任务T就是“为新的电子邮件标记垃圾邮件标识” ;E就是训练样本(也就是已经由人工标记完了的邮件列表,也叫做训练集数据);P是绩效指标,程序能够正确分类的电子邮件占比。
1.1 为何使用机器学习?
机器学习的意义是什么呢?这章以垃圾邮件过滤器来例来做说明,对比垃圾邮件筛选器这个应用传统和机器学习方式的处理方法。
如果使用传统方式来识别一封垃圾邮件,该如何做呢?
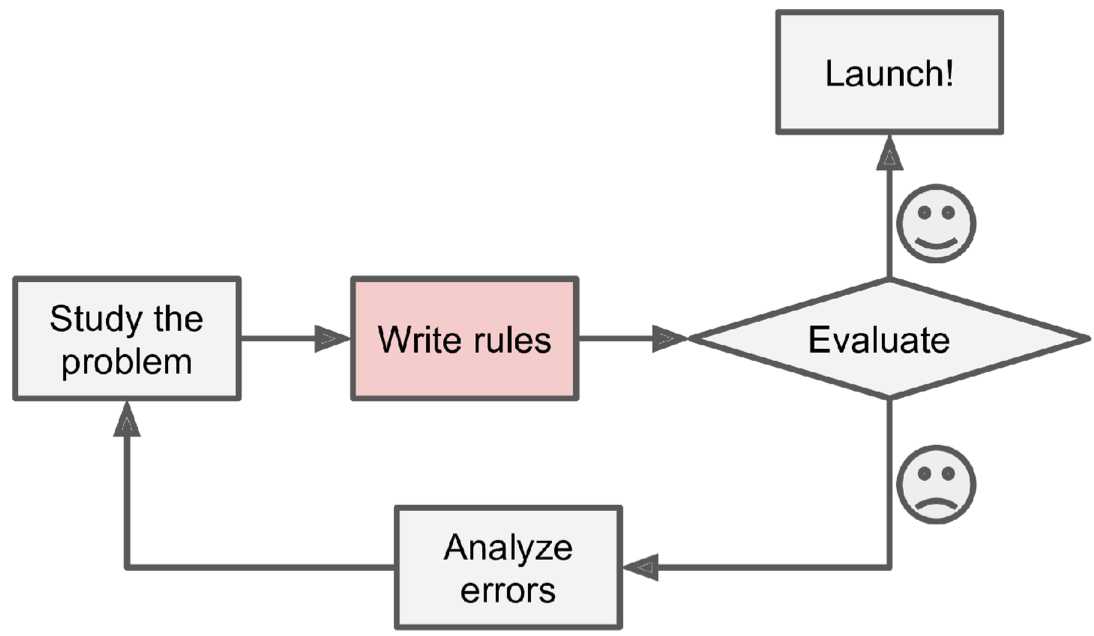
首先,你会分析这些问题,并提炼总结一些规则:例如标题里包含某些字符串(信用卡、卖房等等)、某些人发的邮件(例如某电商网站)、邮件内容包含某些内容(成人视频等)。现在,你编写一个程序,一个邮件过来后,如果匹配了一个或者多个你前边提炼的模式规则,你就判断这封邮件是垃圾邮件。当然,你需要不断重复上边2个步骤,以达到你的程序能够覆盖更多的模式情况。这种方式不好的地方显而易见,你的规则会十分复杂(而且是越来越复杂,难以维护)。整体流程如下图所示:
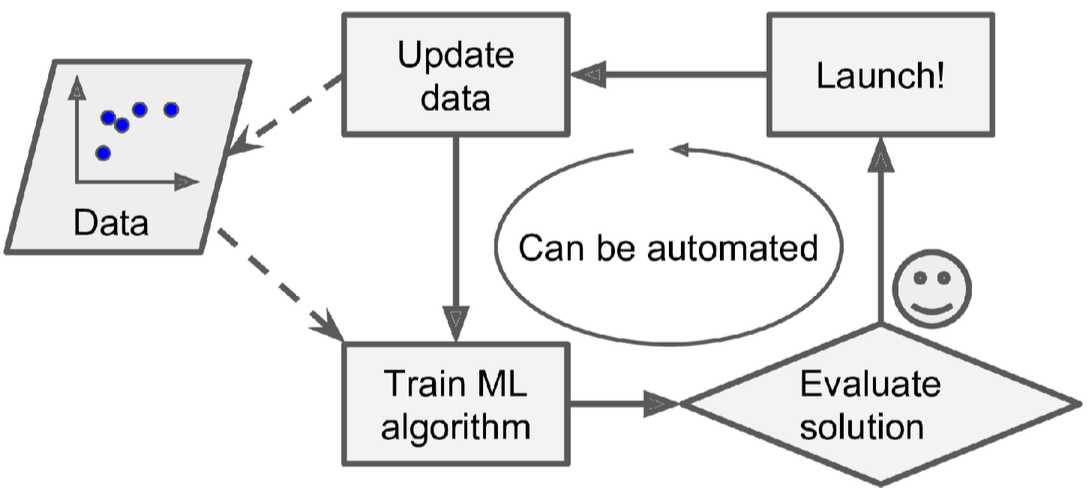
机器学习的程序则很简洁,机器学习程序自动学习识别出哪些词语更加能够标识出一封垃圾邮件,程序十分简洁。同时,如果邮件发送者发现自己某些带某字符串(例如“4U”)的邮件经常被标记为垃圾邮件,他们可能会修改为“For U”而逃过过滤器拦截,那么传统方式就需要修改程序了(因为需要增加一个pattern)。而机器学习程序能够根据用户标记为垃圾邮件的数据,自动学习出哪些词语在垃圾邮件中高频出现,并将包含这些词语的邮件标记为垃圾邮件,很容易维护。应用机器学习技术来挖掘大量数据可以帮助发现并非立即可见的模式。这称为数据挖掘。
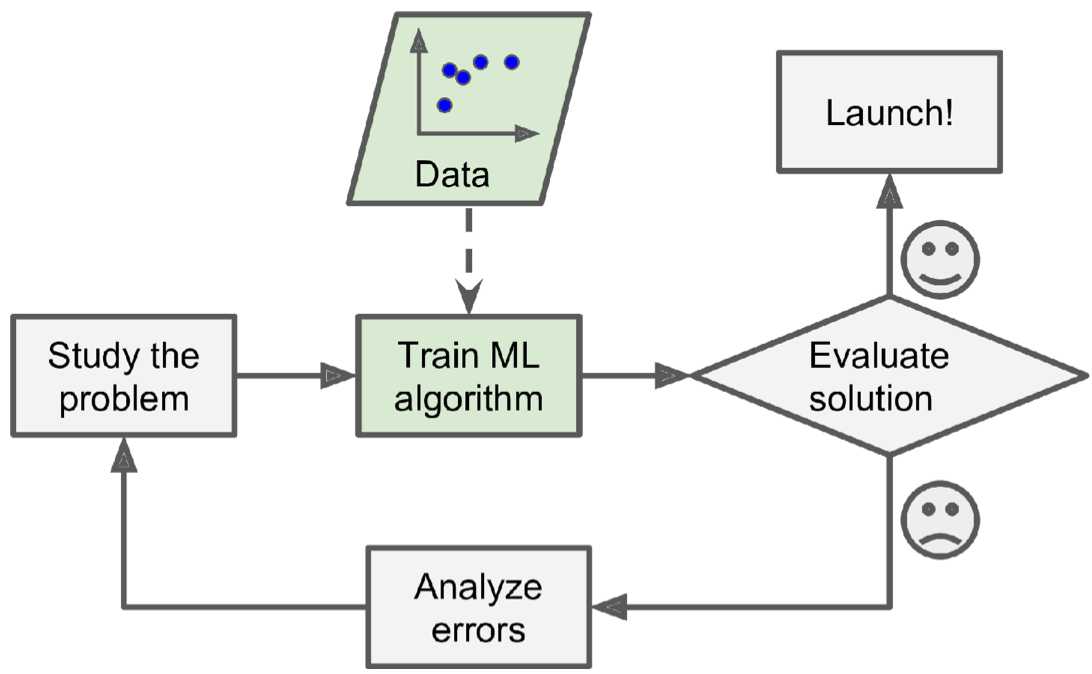 ,
, 
2.Machine Learning的类别:
2.1 监督、无监督、半监督和强化学习:
根据是否是在人的监督下学习,将ML分为了监督,无监督,半监督和强化学习。
2.1.1 监督学习:
所有训练集都有标签。
监督学习的训练集中包含最终结果(称为标签)。垃圾邮件过滤器是一个典型监督学习,另外回归任务房价预测(根据房子大小,卧室数量等特征)也是监督学习。一些回归算法也可以用于分类,反之亦然。以下是一些最重要的监督学习算法:
- k近邻
- 线性回归
- Logistic回归
- 支持向量机(SVM)
- 决策树和随机森林
- 神经网络
2.1.2 无监督学习:
所有训练集都没有标签。
无监督学习中,训练数据集中不包含最终结果标签。常见聚类算法都是无监督学习。
聚类算法:
- K-均值
- DBSCAN
- 层次聚类分析(HCA)
一个相关的任务是降维,其目的是简化数据而不会丢失太多信息。 一种方法是将多个相关功能合并为一个。 例如,汽车的行驶里程可能与汽车的寿命密切相关,因此降维算法会将其合并为一个代表汽车磨损的特征。 这称为特征提取。另一个重要的无人监督任务是异常检测, 另外啤酒尿片的挖掘例子也是无监督学习的例子。
2.1.3 半监督学习:
部分训练集有标签。
由于标记数据通常很耗时且成本很高,因此您通常会拥有大量未标记的实例,而标记的实例却很少。 某些算法可以处理部分标记的数据。 这称为半监督学习。
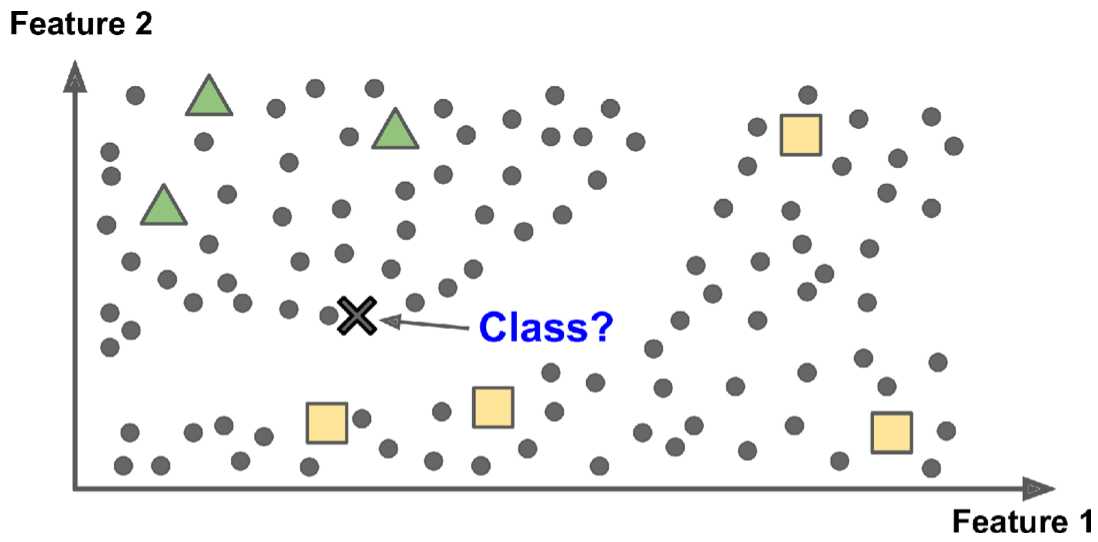
下图是一个半监督学习的例子,三角形和方形的示例是有标签的训练样本,圆形的点是无标签的点。该例子利用这些无标记的点,把心的点归类为三角形,而不是方形(虽然这个点离方形的样本点最近)。大多数半监督学习算法是无监督算法和有监督算法的组合。
2.1.4 强化学习:
学习系统自己观察环境,并作出自己的选择,在作出正确选择时会获得奖励,在作出错误选择时,会获得惩罚。随着时间推移,强化学习系统必须找到一个策略,来获得最多的奖励。DeepMind的AlphaGo就是强化学习的例子,AlphaGo通过分析数百万场比赛,来学习获胜策略,之后AlphaGo和自己来对弈。
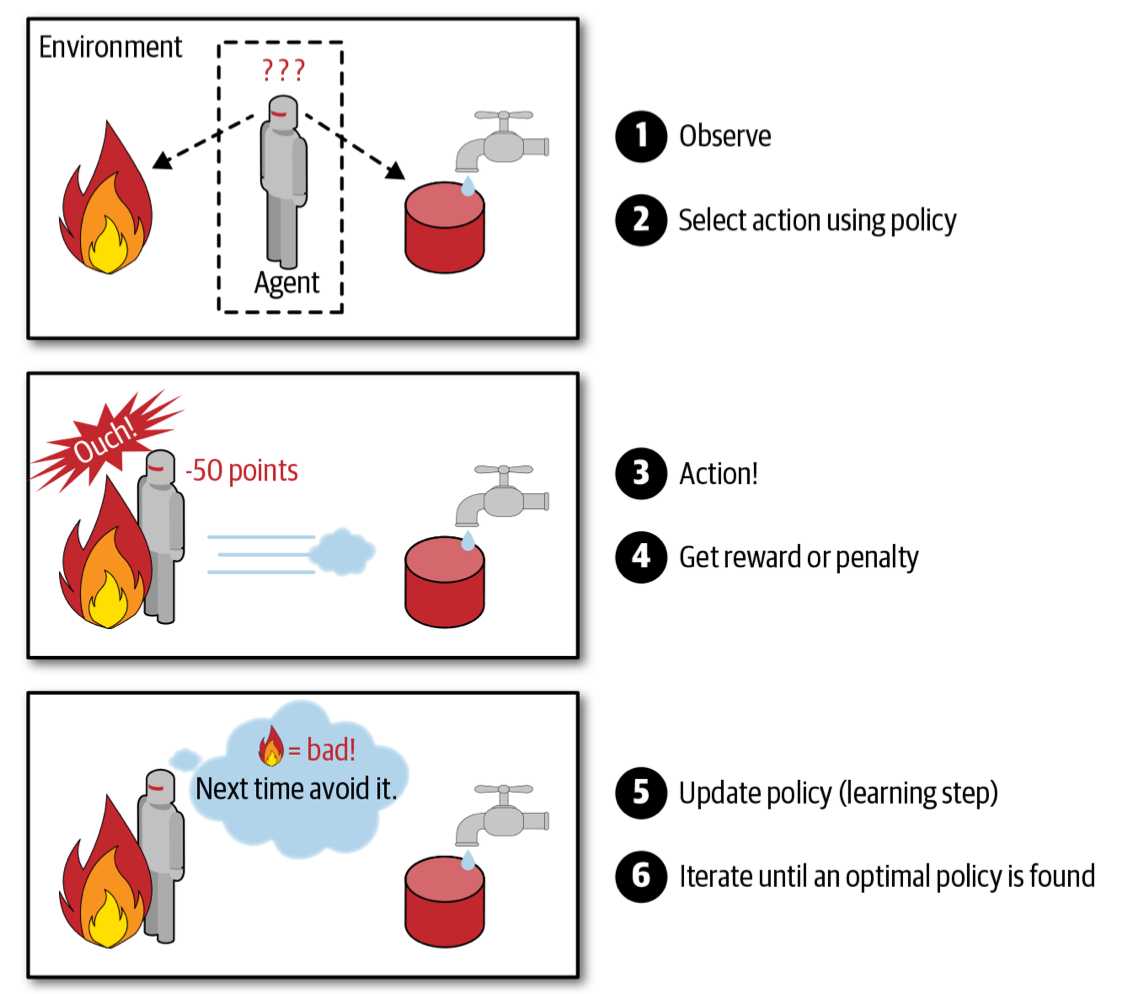
2.2 批量和在线学习:
以上是关于Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow ——Chapter 1 Machine Learning Land的主要内容,如果未能解决你的问题,请参考以下文章