使用Pytorch实现简单的人脸二分类器
Posted yy-1046741080
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Pytorch实现简单的人脸二分类器相关的知识,希望对你有一定的参考价值。
该项目的目的是建立一个有关于人脸的二分类器。
steps :
1. Load the data
2. Define a Convolutional Neural Network
3. Train the Model
4. Evaluate the Performance of our trained model on a dataset
加载数据集
主要内容:加载和预处理。
预处理:使用pytorch的transform进行转换。预处理后的数据形成实验的数据集。
1 transform = transforms.Compose([ 2 transforms.RandomHorizontalFlip(), 3 transforms.RandomRotation(20), 4 transforms.ToTensor(), 5 transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) 6 ])
数据加载:在一般情况下,我们继承 torch.util.data.Dataset 形成数据集,然后使用 torch.util.data.DataLoader 形成完成数据加载。
在这里,直接使用 torchvision.datasets.ImageFolder实现数据的读取。
1 train_data = datasets.ImageFolder(‘face‘,transform=transform)
对于项目的数据集常划分为三个部分:训练集,验证集,测试集。 训练集:用于训练模型;验证集:在每一个epoch之后,用于验证模型的性能;测试集用于训练完成后,测试模型的性能。因此,对于train_data需要进行再划分。
1 # 将数据集进行第一次划分 train / test 获得index list 2 num_data = len(train_data) 3 indices_data = list(range(num_data)) # [0,.....,num_data-1] 4 np.random.shuffle(indices_data) # 打乱顺序 5 split_tt = int(np.floor(test_size * num_data)) # np.floor:向下取整 test_size:(0,1) 取部分 6 train_idx, test_idx = indices_data[split_tt:], indices_data[:split_tt] # index list 7 8 # 将train数据集划分为 train / validation 获得index list 9 num_train = len(train_idx) 10 indices_train = list(range(num_train)) 11 np.random.shuffle(indices_train) 12 split_tv = int(np.floor(valid_size * num_train)) 13 train_idx, valid_idx = indices_train[split_tv:],indices_train[:split_tv]
通过Sampler(采样器)和DataLoader实现数据的加载。
1 # define samplers for obtaining training and validation batches 2 train_sampler = SubsetRandomSampler(train_idx) 3 test_sampler = SubsetRandomSampler(test_idx) 4 valid_sampler = SubsetRandomSampler(valid_idx) 5 6 # Loaders contains the data in tuple format , The train_loader, test_loader and valid_loader will be used to pass the input to the model. 7 train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, sampler=train_sampler, num_workers=1) 8 valid_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, sampler=valid_sampler, num_workers=1) 9 test_loader = torch.utils.data.DataLoader(train_data, sampler = test_sampler, batch_size=batch_size,num_workers=1)
图像的标签:
1 # variable representing classes of the images , label 2 classes = [0,1]
定义一个卷积神经网络
定义网络的某一个层次:torch.nn.Conv2D(Depth_of_input_image, Depth_of_filter, size_of_filter, padding, strides)
Depth of the input image is generally 3 for RGB, and 1 for Grayscale.
Depth of the filter is specified by the user which generally extracts the low level features。
the size of the filter is the size of the kernel which is convolved over the whole image.
定义CNN,并且进行初始化:
# define class Net(nn.Module): def __init__(self): super(Net, self).__init__() # convolutional layer self.conv1 = nn.Conv2d(3, 16, 5) # max pooling layer self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(16, 32, 5) self.dropout = nn.Dropout(0.2) self.fc1 = nn.Linear(32*53*53, 256) self.fc2 = nn.Linear(256, 84) # 线性层: 256长度 -> 84长度 self.fc3 = nn.Linear(84, 2) # 线性层:84长度 -> 2长度 self.softmax = nn.LogSoftmax(dim=1) # Softmax def forward(self, x): # add sequence of convolutional and max pooling layers x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = self.dropout(x) x = x.view(-1, 32 * 53 * 53) x = F.relu(self.fc1(x)) x = self.dropout(F.relu(self.fc2(x))) x = self.softmax(self.fc3(x)) return x # create a complete CNN model = Net()
模型结构: 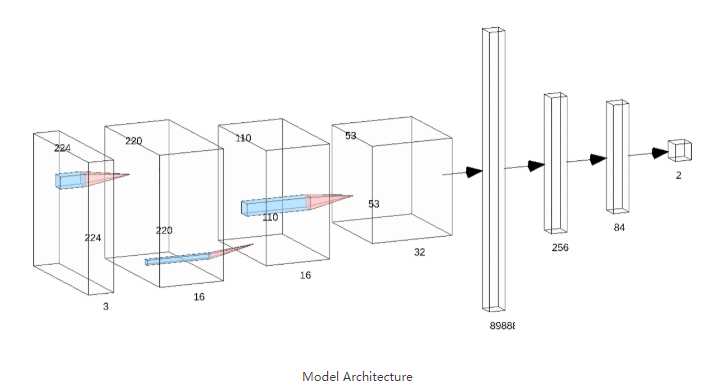
除了定义模型之外,还需要定义 loss function 和 optimizer 。
Loss Function will help us in calculating the loss by comparing the prediction and original label.
The optimizer will minimize the loss by updating the parameters of the model after every epoch.
1 # Loss function 2 criterion = torch.nn.CrossEntropyLoss() 3 # Optimizer SDG weight = weight - learning_rate*gradient 4 optimizer = torch.optim.SGD(model.parameters(), lr = 0.003, momentum= 0.9)
训练模型
训练模型的过程:
1) Clear the gradients of all optimized variables : There could be gradients from previous batches, therefore it’s necessary to clear gradient after every epoch
2) Forward pass: This step computes the predicted outputs by passing inputs to the convolutional neural network model
3) Calculate the loss: As the model trains, the loss function calculates the loss after every epoch and then it is used by the optimizer.
4) Backward pass: This step computes the gradient of the loss with respect to model parameters
5) Optimization: This performs a single optimization step/ parameter update for the model.
6) Update average training loss
对模型进行评估
To evaluate the model, it should be changed from model.train() to model.eval()。
1 model.eval() 2 # iterate over test data 3 len(test_loader) 4 for data, target in test_loader: 5 # move tensors to GPU if CUDA is available 6 if train_on_gpu: 7 data, target = data.cuda(), target.cuda() 8 # forward pass 9 output = model(data) 10 # calculate the batch loss 11 loss = criterion(output, target) 12 # update test loss 13 test_loss += loss.item()*data.size(0) 14 # convert output probabilities to predicted class 15 _, pred = torch.max(output, 1) 16 # compare predictions to true label 17 correct_tensor = pred.eq(target.data.view_as(pred)) 18 correct = np.squeeze(correct_tensor.numpy()) if not train_on_gpu else np.squeeze(correct_tensor.cpu().numpy()) 19 # calculate test accuracy for each object class 20 for i in range(batch_size): 21 label = target.data[i] 22 class_correct[label] += correct[i].item() 23 class_total[label] += 1
1 # average test loss 2 test_loss = test_loss/len(test_loader.dataset) 3 print(‘Test Loss: {:.6f} ‘.format(test_loss)) 4 5 for i in range(2): 6 if class_total[i] > 0: 7 print(‘Test Accuracy of %5s: %2d%% (%2d/%2d)‘ % ( 8 classes[i], 100 * class_correct[i] / class_total[i], 9 np.sum(class_correct[i]), np.sum(class_total[i]))) 10 else: 11 print(‘Test Accuracy of %5s: N/A (no training examples)‘ % (classes[i])) 12 13 print(‘ Test Accuracy (Overall): %2d%% (%2d/%2d)‘ % ( 14 100. * np.sum(class_correct) / np.sum(class_total), 15 np.sum(class_correct), np.sum(class_total))) 16 17 """ 18 Test Loss: 0.006558 19 Test Accuracy of 0: 99% (805/807) 20 Test Accuracy of 1: 98% (910/921) 21 Test Accuracy (Overall): 99% (1715/1728) 22 """
链接
https://hackernoon.com/binary-face-classifier-using-pytorch-2d835ccb7816
这个链接有完整的介绍和GitHub地址以及数据集,我这篇文章只是做了大概的摘录。
以上是关于使用Pytorch实现简单的人脸二分类器的主要内容,如果未能解决你的问题,请参考以下文章