NLPELMO
Posted liuxiangyan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLPELMO相关的知识,希望对你有一定的参考价值。
参考:https://www.cnblogs.com/robert-dlut/p/9824346.html
Embeddings from Language Model
一、引入
ELMO不同于glove,word2vec,后者们的思想是对于一个词语,用一个预训练好的模型,把一个词语变成一个固定不变的词向量表示,固定不变的意思就是,一旦我确定好了我的模型,确定好了我的语料库,那么这个词即将变成哪一个词向量表示就确定了。然而ELMO不是这样的,对于‘apple’一词,ELMO认为当它是指苹果公司的时候是一种词向量表示,但当它是指吃的水果的时候又是另一种词向量表示,ELMO可以解决一词多义的问题,因为它是基于long context的,而不是像word2vec之类的基于语料库的窗口来训练的。
二、RNN和LSTM
RNN- Recurrent Neural Network循环神经网络
因为神经网络来学习这种序列问题,比如翻译,语音识别等问题,结果并不好,因为首先你不清楚你输入的句子有多长,毕竟训练出来的模型是要可以用在其他句子上的;其次标准的神经网络不能够共享从文本的不同位置学习到的特征,比如说当我们一开始知道了“小明”是个人名,希望随后“小明”再次出现时依然记得它是人名,标准神经网络就做不到共享特征。于是就可以采用循环神经网络RNN来解决这个问题。
比如一句话是“小明开开心心地和小蓝一起去上学”。对于这个句子,我们知道翻译结果“Xiaoming and Xiaolan go to school happily”。RNN如果用作翻译,它是这么处理这个句子的:
首先我们有个初始化的向量,称为$a^{0}$,此时我们开始从左往右开始读原句子,读到“小明”,然后我们就用“小明”和$a^{0}$一块计算
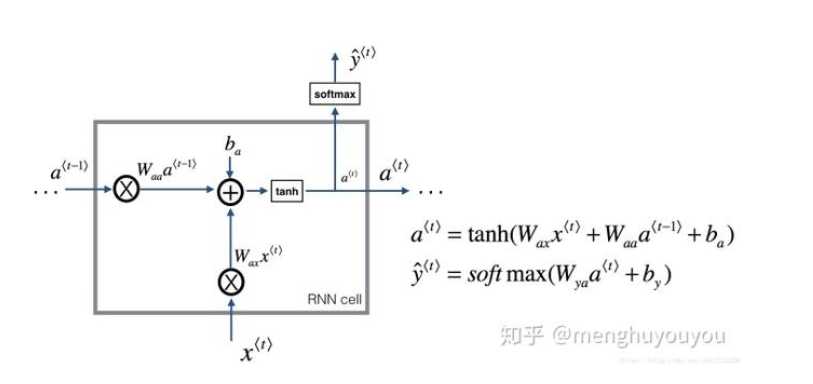
RNN存在梯度消失的问题,也就是说RNN的单元太多太长的时候,反向传播时,最前面的参数可能会得到很少甚至几乎没有的更新步长,这是不科学的,因为这些最前面的单元参数不可以倚老卖老,不能因为你先出现了,你就不做任何改变;然后LSTM就是可以用来解决RNN的梯度消失问题所提出来的。这是二者的关系,先做一个感性的认识,接下来会讲一下LSTM具体是什么样一种机制
三、ELMO
四、
以上是关于NLPELMO的主要内容,如果未能解决你的问题,请参考以下文章