决策树与随机森林实例
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树与随机森林实例相关的知识,希望对你有一定的参考价值。
想必很多人都听说过决策树和随机森林,这是用来预测的数学模型,用python可以快速实现。下面这些代码请收好,理解其中的含义以后,改改参数你也可以用这个模型进行预测啦。不过博主以为,模型最后的寻找重要因子才是最有意思的部分~拿到数据集的第一步,清洗数据:
import pandas as pd
import numpy as np
titanic=pd.read_csv(r‘/Users/titanic_train.csv‘)
#删除无关列
titanic.drop([‘PassengerId‘,‘Ticket‘,‘Cabin‘,‘Name‘],axis=1,inplace=True)
#补全年龄缺失值
fillna_titanic=[]
for i in titanic.Sex.unique():
update=titanic.loc[titanic.Sex==i].fillna(value={‘Age‘:titanic.Age[titanic.Sex==i].mean()})
fillna_titanic.append(update)
titanic=pd.concat(fillna_titanic)
#补全登船信息
titanic.fillna(value={‘Embarked‘:titanic.Embarked.mode()[0]},inplace=True)第二步,把变量转化成哑变量的形式:
#数值pclass转化成类型
titanic.Pclass=titanic.Pclass.astype(‘category‘)
#哑变量处理
dummy=pd.get_dummies(titanic[[‘Sex‘,‘Embarked‘,‘Pclass‘]])
#水平合并titanic和哑变量数据集
titanic=pd.concat([titanic,dummy],axis=1)
titanic.drop([‘Sex‘,‘Embarked‘,‘Pclass‘],axis=1,inplace=True)数据准备好以后,就开始搭建模型啦。以下这些代码不用背下来,只要用到的时候改改参数就好了。这就是python的魅力所在,可以让一些很复杂的事情变得你也可以上手。
#训练集和测试集的搭建
from sklearn import model_selection
#取出所有自变量名称
predictors=titanic.columns[1:]
#将数据拆分为训练集和测试集,测试集的比例为25%
X_train,X_test,y_train,y_test=model_selection.train_test_split(titanic[predictors],titanic.Survived,
test_size=0.25,random_state=1234)
#使用网格法找出最优越模型参数
from sklearn.model_selection import GridSearchCV
from sklearn import tree
#预设各参数的不同选项值
max_depth=[2,3,4,5,6]
min_samples_split=[2,4,6,8]
min_samples_leaf=[2,4,8,10,12]
#将各参数的值以字典的形式组织起来
parameters={‘max_depth‘:max_depth,‘min_samples_split‘:min_samples_split,‘min_samples_leaf‘:min_samples_leaf}
#网格搜索法,测试不同的参数值
grid_dtcateg=GridSearchCV(estimator=tree.DecisionTreeClassifier(),param_grid=parameters,cv=10)
#模型拟合
grid_dtcateg.fit(X_train,y_train)
#返回最佳组合的参数值
print(grid_dtcateg.best_params_)最佳参数组合为:3,4,2
找到最佳组合的参数后,试着搭建一棵决策树:
#单棵决策树建模
from sklearn import metrics
#构建分类决策树
CART_Class=tree.DecisionTreeClassifier(max_depth=3,min_samples_leaf=4,min_samples_split=2)
#模型拟合
decision_tree=CART_Class.fit(X_train,y_train)
#模型在测试集上的预测
pred=CART_Class.predict(X_test)
#模型的准确率
print(‘模型在测试集的预测准确率为:‘,metrics.accuracy_score(y_test,pred))准确率为0.83,还不错。
绘图表现这个准确率:
import matplotlib.pyplot as plt
y_score=CART_Class.predict_proba(X_test)[:,1]
fpr,tpr,threshold=metrics.roc_curve(y_test,y_score)
#计算AUC的值
roc_auc=metrics.auc(fpr,tpr)
#绘制面积图
plt.stackplot(fpr,tpr,color=‘steelblue‘,alpha=0.5,edgecolor=‘black‘)
#添加边际线
plt.plot(fpr,tpr,color=‘black‘,lw=1)
#添加对角线
plt.plot([0,1],[0,1],color=‘red‘,linestyle=‘-‘)
#添加文本信息
plt.text(0.5,0.3,‘ROC curve(area=%0.2f)‘%roc_auc)
#添加x轴与y轴标签
plt.xlabel(‘1-Specificity‘)
plt.ylabel(‘Sensitivity‘)
#显示图形
plt.show()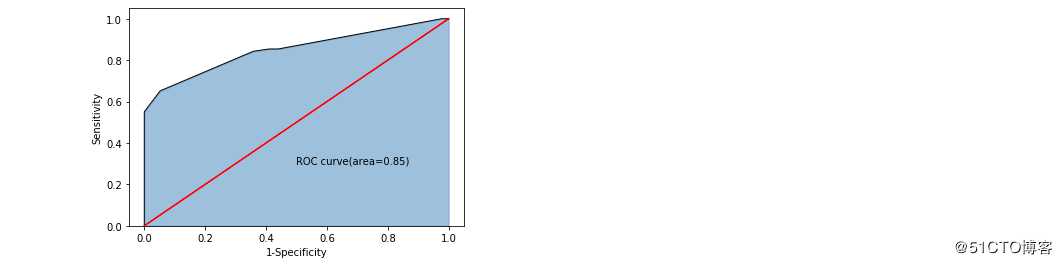
构建随机森林的模型看看:
#构建随机森林,随机森林可以提高单棵决策树的预测准确度
from sklearn import ensemble
RF_class=ensemble.RandomForestClassifier(n_estimators=200,random_state=1234)
#随机森林的拟合
RF_class.fit(X_train,y_train)
#模型在测试集上的预测
RFclass_pred=RF_class.predict(X_test)
#模型的准确率
print(‘模型在测试集的预测准确率为:‘,metrics.accuracy_score(y_test,RFclass_pred))随机森林的准确率为:0.85,比单棵决策树的准确率更高。
画个图看看准确率:
#计算绘图数据
y_score=RF_class.predict_proba(X_test)[:,1]
fpr,tpr,threshold=metrics.roc_curve(y_test,y_score)
#计算AUC的值
roc_auc=metrics.auc(fpr,tpr)
#绘制面积图
plt.stackplot(fpr,tpr,color=‘steelblue‘,alpha=0.5,edgecolor=‘black‘)
#添加边际线
plt.plot(fpr,tpr,color=‘black‘,lw=1)
#添加对角线
plt.plot([0,1],[0,1],color=‘red‘,linestyle=‘-‘)
#添加文本信息
plt.text(0.5,0.3,‘ROC curve(area=%0.2f)‘%roc_auc)
#添加x轴与y轴标签
plt.xlabel(‘1-Specificity‘)
plt.ylabel(‘Sensitivity‘)
#显示图形
plt.show()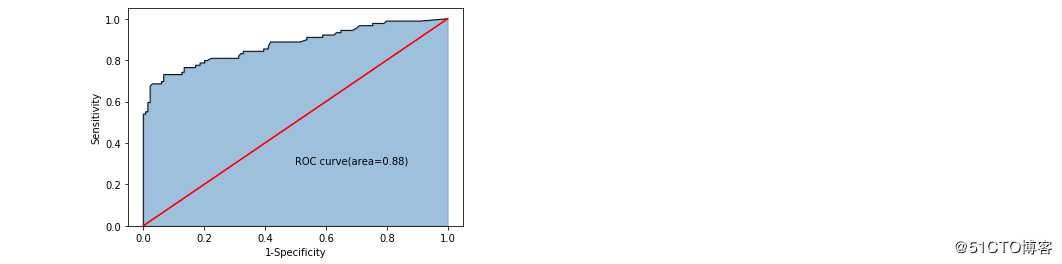
哪些因素决定着泰坦尼克号上的获救率呢:
#自变量的重要性程度
importance=RF_class.feature_importances_
#构建序列用于绘图
Impt_Series=pd.Series(importance,index=X_train.columns)
#对序列排序绘图
Impt_Series.sort_values(ascending=True).plot(kind=‘barh‘)
plt.show()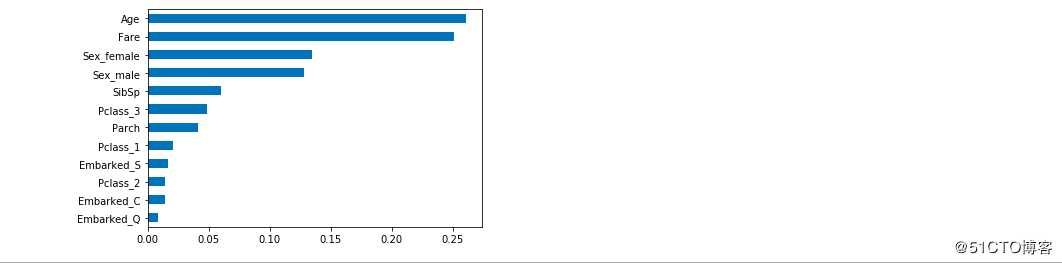
结论已经显而易见,大家有什么启发吗?
以上是关于决策树与随机森林实例的主要内容,如果未能解决你的问题,请参考以下文章