搭建HDFS集群和Yarn集群
Posted zyhself
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搭建HDFS集群和Yarn集群相关的知识,希望对你有一定的参考价值。
前提补充
Q:为什么要三台服务器
A:
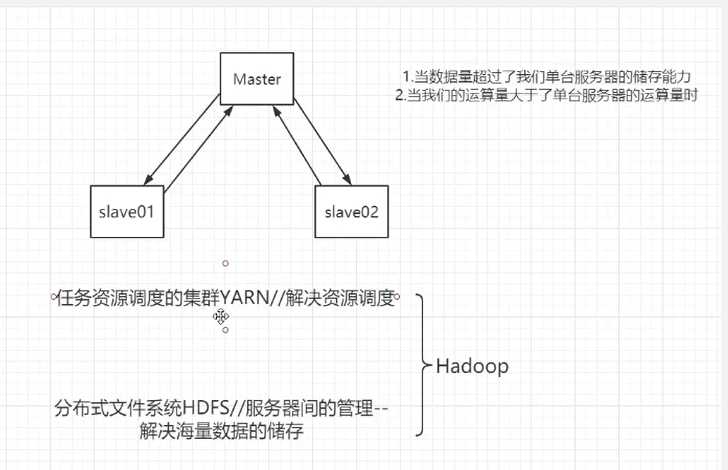
1.当数据量超过我们单台服务器的存储能力
2.当我们的运算量大于了单台服务器的运算量时(运算能力)
解决存储能力
Q:服务器间的管理,解决海量数据的存储
A:分布式文件系统HDFS
解决运算能力
Q:解决资源调度:教练让去打比赛
A:任务资源调度的集群YARN
1.Hadoop
概念:允许使用简单的编程模型在大量的服务器上对大型的数据进行分布式处理(底层:基于java进行开发)
2.Hadoop的核心组件
1.HDFS分布式文件系统---解决海量数据储存
2.Yarn资源调度集群---解决资源的任务调度
监听到M符合条件就调用它类似这种的
Yarn用的mapreduce分布式的编程运算框架
3.mapreduce分布式运算编程框架---解决海量数据的计算
数据清洗,计算
3.企业中应用相关生态
1.能够扩展大量服务器(硬核需求)
2.成本--hadoop可以在一些廉价的服务器上面进行部署和运行
3.高效率--hadoop可以在各个服务器之间并行的移动数据,使得处理数据的速度非常快(又想马儿跑又不给马儿吃草)
4.可靠性--hadoop可以自动的维护数据并且进行备份(定时备份),会在任务失败以后能够自动的重新部署计算任务。
4.搭建HDFS分布式文件系统以及Yarn集群
1.得安装我们的hadoop--java(hdfs和yarn是基于hadoop,而hadoop基于java)
2.安装我们的JDK
切换到home目录,把jdk和hadoop.tar.gz直接拉进去
安装JDK
切换目录 cd /usr 创建java目录 mkdir java 切换到java的安装包目录 cd /home 进行java安装包解压指定目录到 /usr/java tar -zxvf jdk-8u101-linux-x64.tar.gz -C /usr/java 进入usr中的jdk目录,ls显示出jdk为jdk1.8.0_101 修改环境变量 vi /etc/profile 添加以下内容: export JAVA_HOME=/usr/java/jdk1.8.0_101 export PATH=$PATH:$JAVA_HOME/bin 重新加载环境变量 source /etc/profile 检测JDK是否配置成功 java -version 出现一下内容表示成功 java version "1.8.0_101" Java(TM) SE Runtime Environment (build 1.8.0_101-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.101-b13, mixed mode)
以上是关于搭建HDFS集群和Yarn集群的主要内容,如果未能解决你的问题,请参考以下文章