MapReduce之自定义Partitioner
Posted bitbitbyte
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce之自定义Partitioner相关的知识,希望对你有一定的参考价值。
概述
Map方法之后, 数据首先进入到分区方法, 把数据标记好分区, 然后把数据发送到环形缓冲区; reduce的并行数量以及输出文件的个数, 由分区数决定.
默认分区是根据key的hashCode对ReduceTasks个数取模得到.

自定义步骤
1.自定义类继承Partitioner, 重写getPartion方法

2. 在Job驱动中, 设置自定义Partitioner

3. 自定义Partititon后, 要根据自定义的Partioner的逻辑设置相应数量的ReducerTask
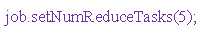
Reduce数量与分区数量的匹配
- 如果reduce数量大于分区数, 则会产生空白输出文件part-r-000xx
- 如果reduce数量小于分区数, 则会一部分数据无处安放, 会抛异常
- 如果reduce数量=1, 最终输出一个文件
注意: 分区号必须从零开始, 逐一累加.
以上是关于MapReduce之自定义Partitioner的主要内容,如果未能解决你的问题,请参考以下文章