MapReduce之自定义Combiner
Posted bitbitbyte
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce之自定义Combiner相关的知识,希望对你有一定的参考价值。
概述
Combinar继承了`Reducer`, 可选过程, 在map端的实现分组(是在map端运行的reduce), 减小网络IO传输;
使用Combiner需要满足的条件
- Combiner不能影响最终计算结果
例如求平均值就不能使用Combiner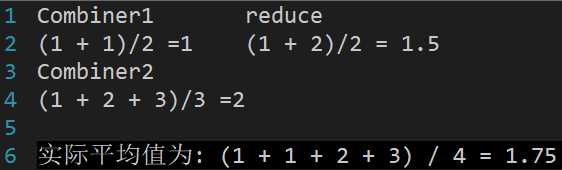
- 输出k-v类型必须与map输出一致
自定义过程
1. 继承Reducer, 重写Reduce方法
x
1
Public class MyReducer extends Reucer<Text, IntWritable, Text, IntWritable>{2
3
@Override4
protected void reduce(Text key, Iterable<IntWritable> values,Context context)5
}2. 在Job驱动类设置
1
1
job.setCombinerClass(WordcountCombiner.class);以上是关于MapReduce之自定义Combiner的主要内容,如果未能解决你的问题,请参考以下文章