如何构建推荐系统
Posted smartloli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何构建推荐系统相关的知识,希望对你有一定的参考价值。
1.概述
最近有被咨询到一些关于推荐系统的问题,今天笔者将为大家分享一些关于如何构建一个推荐系统。
2.内容
2.1 什么是推荐系统?
推荐系统是一种信息过滤系统,它旨在预测用户对某项商品的评价。然后,此预测的评分用于向用户推荐商品。预测评分较高的商品将推荐给用户,这个推荐系统用于推荐范围广泛的项目。比如,它可以用于推荐电影、产品、视频、视频、音乐、新闻、书籍、衣服、游戏、酒店、餐饮、路线等等。几乎所有的大公司都使用它来增强业务,丰富用户的体验,例如腾讯、优酷、爱奇艺这类推荐视频,淘宝、京东推荐商品,微信、QQ推荐好友等。
2.2 USER-ITEM矩阵
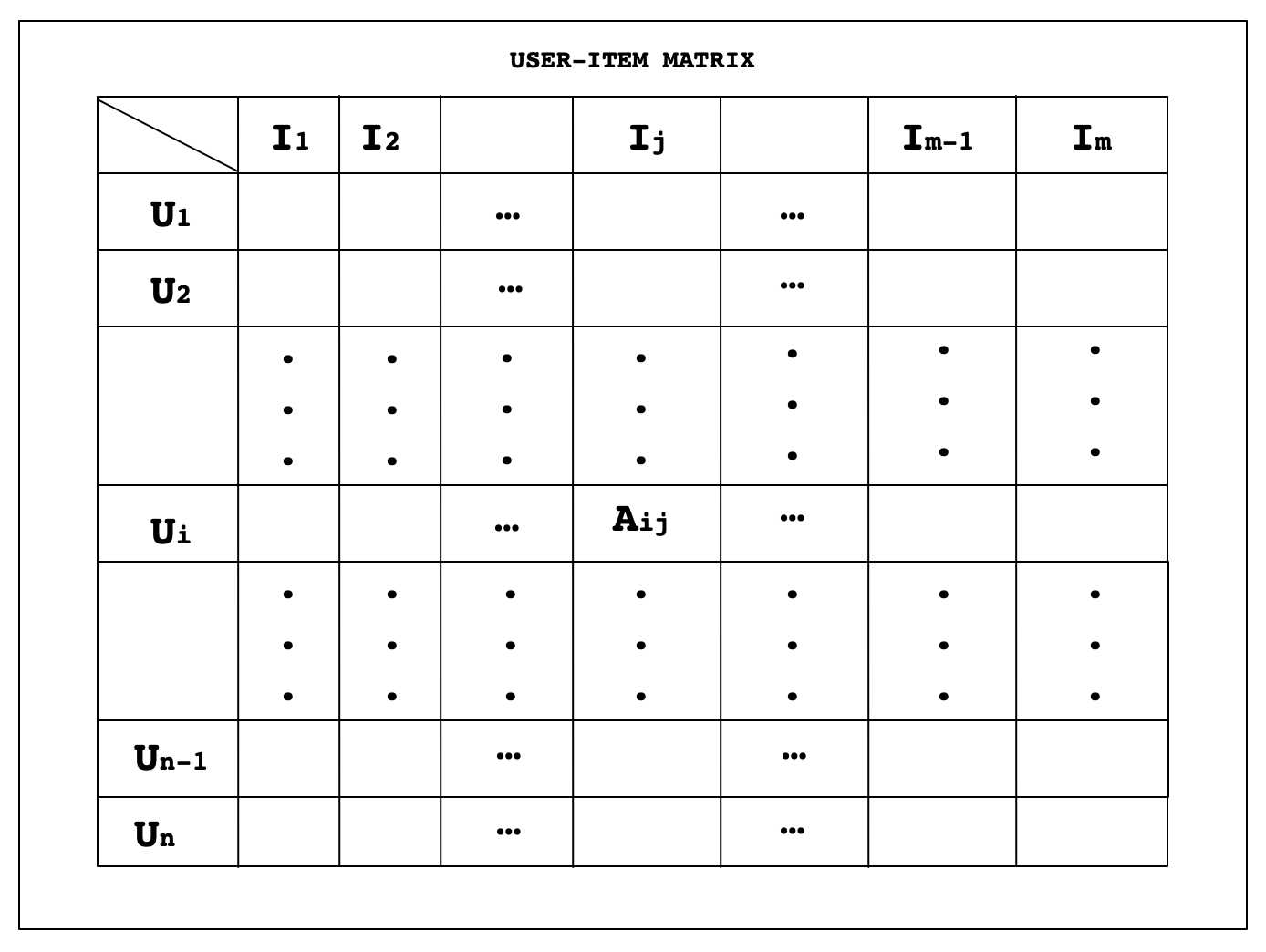
在上图中的USER-ITEM矩阵中,每一行代表一个用户,每一列代表一个物品,每一个单元格代表一个用户对一个物品的评分。总共有N个用户和M和物品。这里Aij是用户Ui对物品Ij的评分,Aij级别范围这里定义为1到5。如果一个矩阵表示一个用户Ui是否观察了一个物品Ij,同样也可以使用二进制来表示,例如这里Aij要么是0,要么是1。
USER-ITEM矩阵是非常稀疏的矩阵,这意味着此矩阵中的许多单元格都是空的。因为,单个用户无法对所有的物品进行评分。在现实情况中,一个用户给总物品数的评分不到1%。因此,这个矩阵中大约99%的单元都是空的。这些空单元格可以使用NaN表示,而不是数字。假如,N是100万,M是1万,那么N*M=106*104=1010就是一个非常大的数字。现在一个普通用户给5个物品打分,那么平均给出的评级总数将是5*100万=5*106评级。矩阵稀疏度计算公式如下:
矩阵稀疏度 = 空单元数 / 总单元数
将案例中的值带入公式计算,矩阵稀疏度 = (1010-5*106) / 1010 = 0.9995
这意味着99.95%的单元格都是空的,这实际上是极端稀疏的。而推荐系统的任务是,假设一个用户Ui喜欢物品I1、I5、I7。然后我们必须向用户Ui推荐一个他/她最可能喜欢的Ij物品。
2.3 推荐系统类型
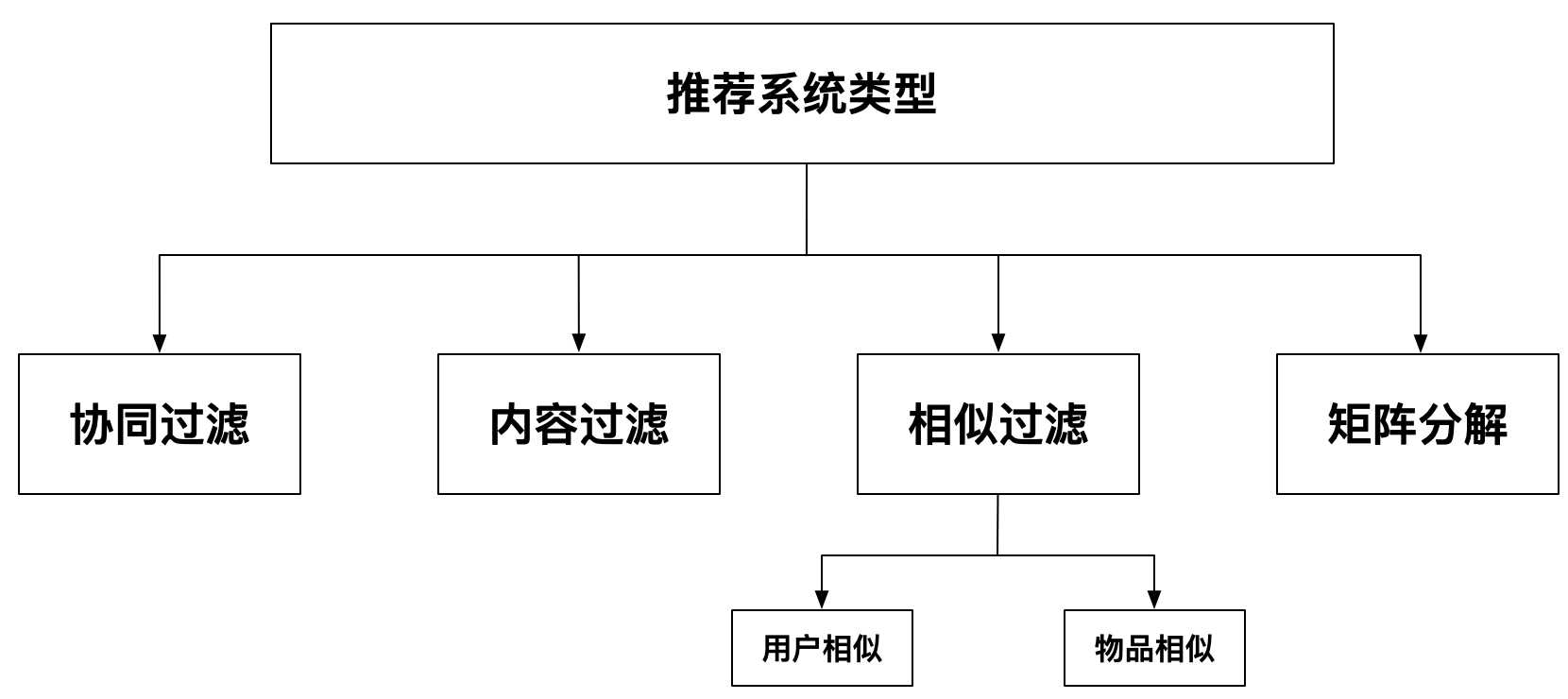
下面我们通过一些例子来理解推荐系统的类型。
2.3.1 协同过滤
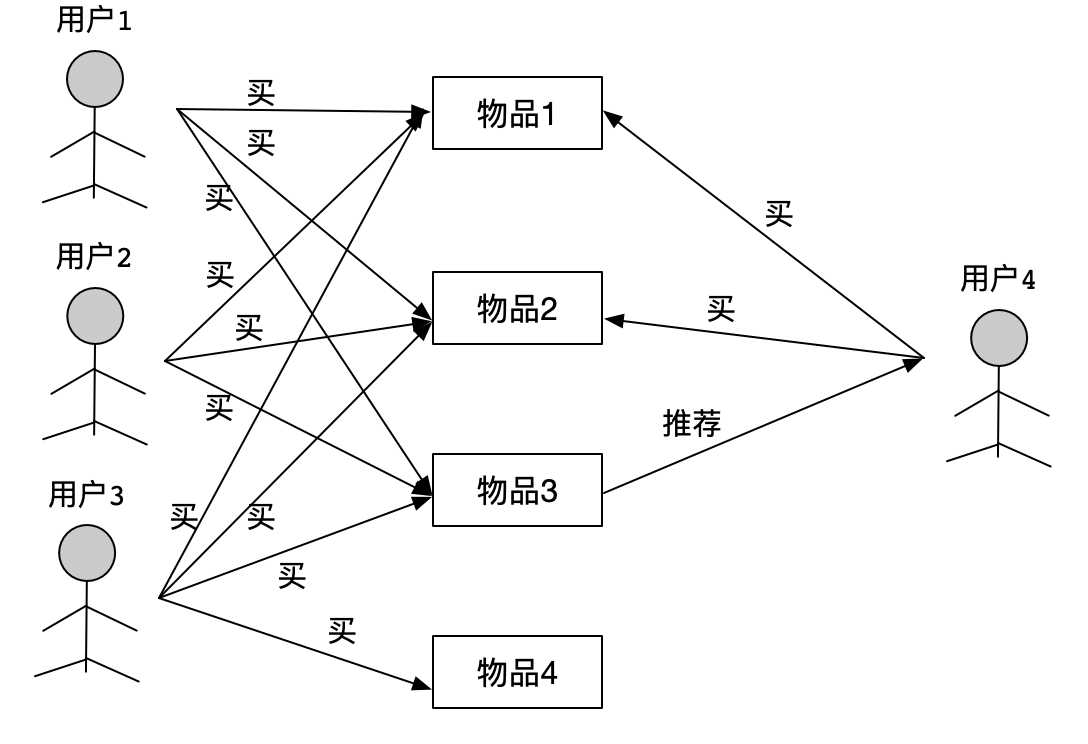
假设有4个用户和4个物品如上图所示,4个用户都购买了物品1和物品2。用户1、用户2、用户3也购买了物品3,但是用户4还没有看到物品3.因此,物品3可以推荐给用户4,现在只有用户3购买了物品4,因此,我们不能向用户4推荐物品4,因为只有用户4购买了物品4,而其他用户没有购买物品4,这就是协作过滤的工作原理。
注意:
在这里,用户1、用户2、用户3,这三个用户过去都统一购买了物品3,因此在未来用户4可能会喜欢物品3,这是用户1、用户2、和用户3过去对物品3的统一喜好
2.3.2 内容过滤
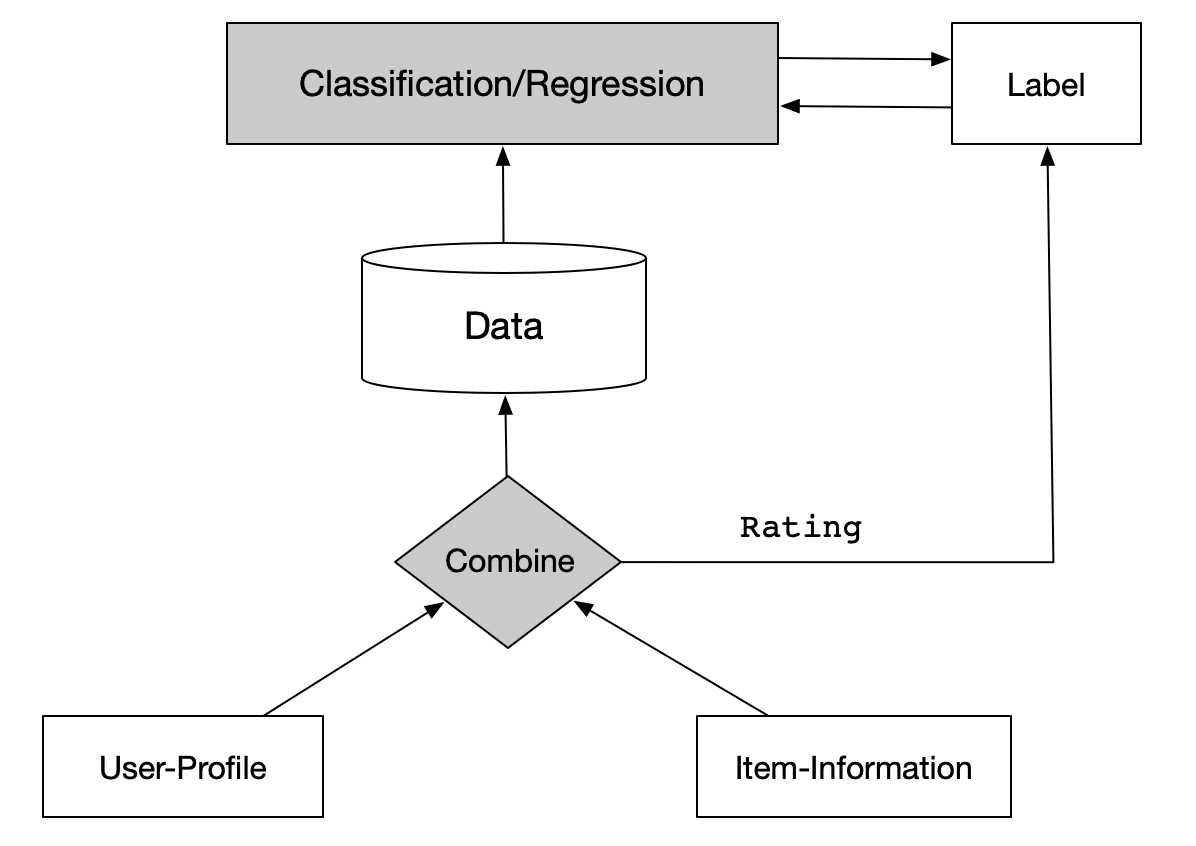
基于内容的过滤在方法上与经典的机器学习技术相似。它需要一种表示物品Ij和用户Ui的方法。在这里,我们需要收集关于物品Ij和用户Ui的信息,然后我们需要创建物品Ij和用户Ui的特性。最后,我们将这些特征结合起来,并将它们输入到机器学习模型中进行训练。这里Label是用户Ui对物品Ij给出的评分。
一旦我们有了上面提到的关于物品和用户的信息,我们就可以创建一个物品向量,其中应该包含关于上面提到的物品信息。然后,我们可以类似的创建一个用户向量,该向量应该包含关于上述用户的信息,我们可以为每个用户Ui和物品Ij生成特性。最后结合这些特性,建立适合于机器学习模型的大数据集。
注意:
在这里,刚刚解释了一种创建基于内容的过滤特性的近似方法。这些功能应经过精心设计,以便在不相互依赖的情况下直接影响评分(标签)。最后尽可能创建独立的功能,同时它们应该非常依赖于评分(标签),这意味着它们应该直接影响评分(标签)。
2.3.3 相似过滤
2.3.3.1 用户相似
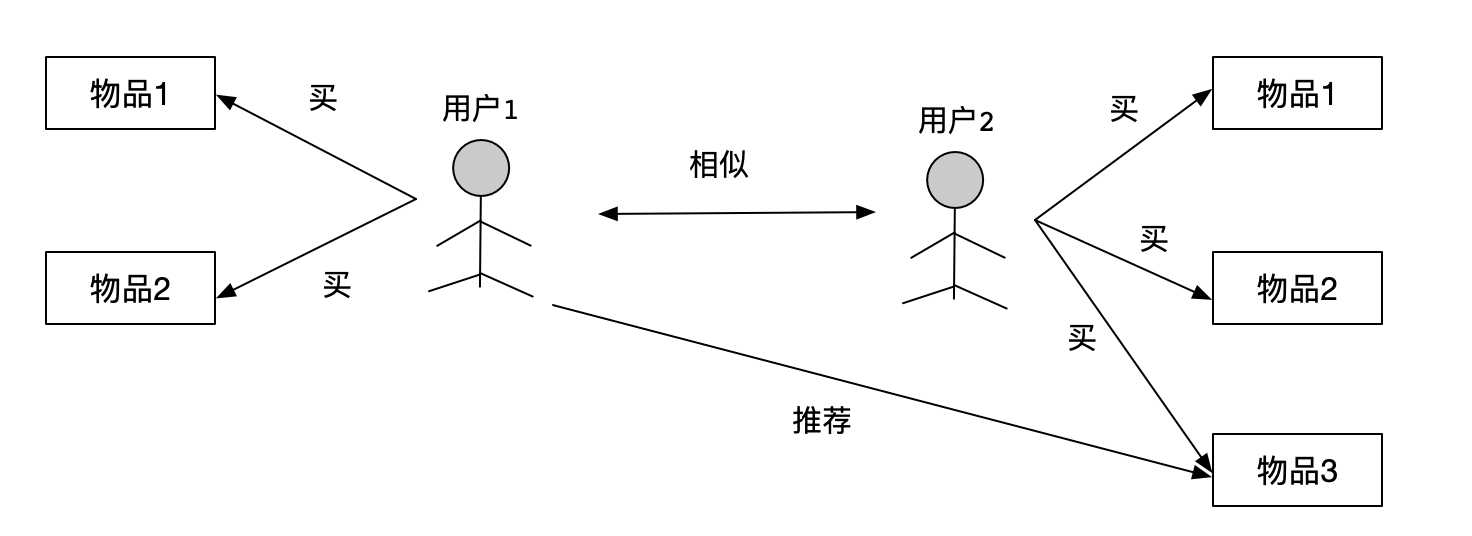
上图是一个非常简单的基于用户相似的推荐。实现步骤如下:
第一步:构建用户与用户之间的相似矩阵
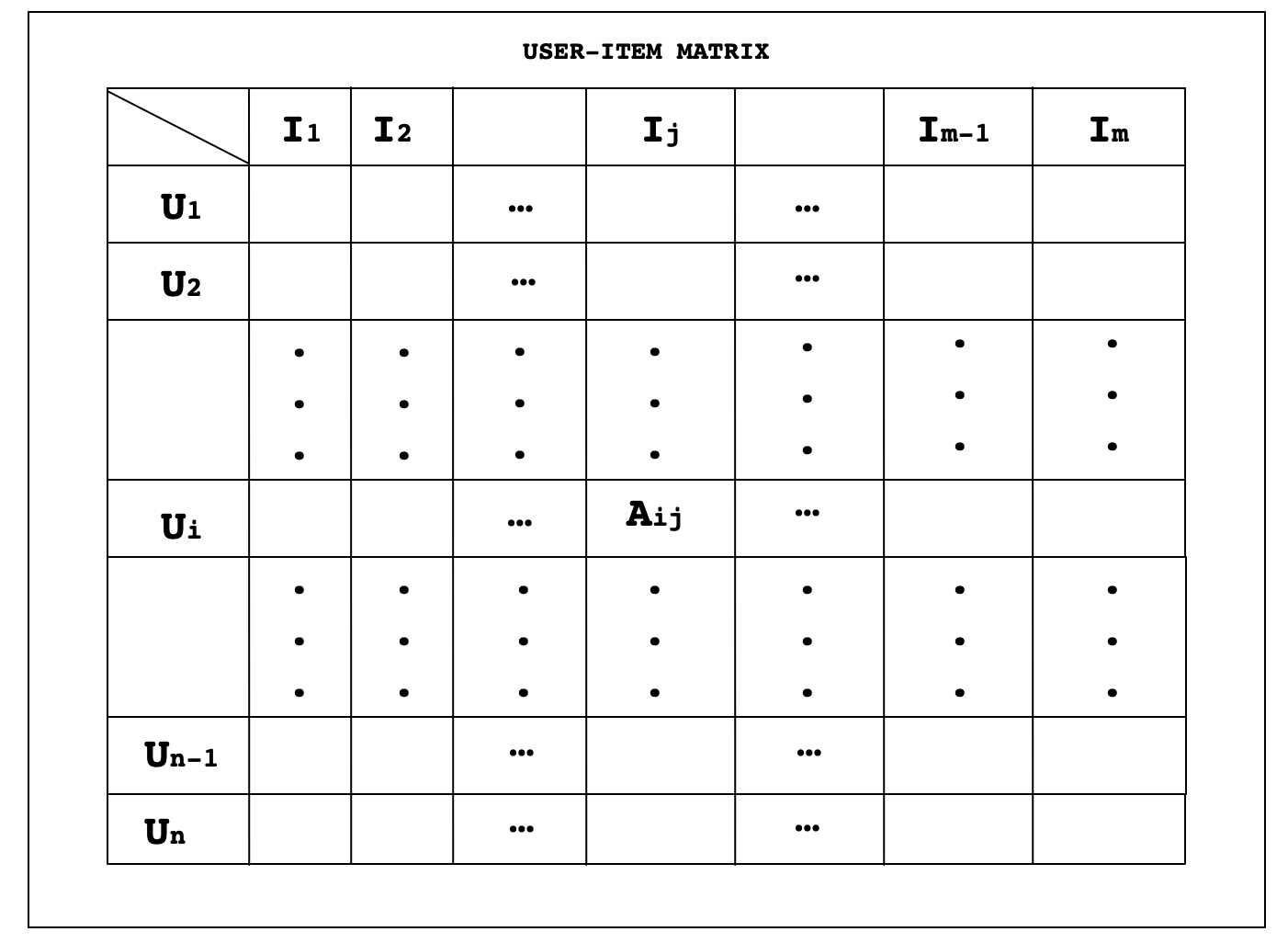
如上图,每一行代表一个用户,其中包含一个用户对所有物品给出的评分。例如,对应于用户Ui的行是大小为m的向量。因此,上述矩阵的每一行都是一个列向量(默认情况下,每个向量都是列向量),大小为m。现在,我们可以构造一个用户之间的相似矩阵,它将是一个大小为n*n的平方对称矩阵,在这里,我们可以使用余弦相似度计算两个用户之间的相似度。
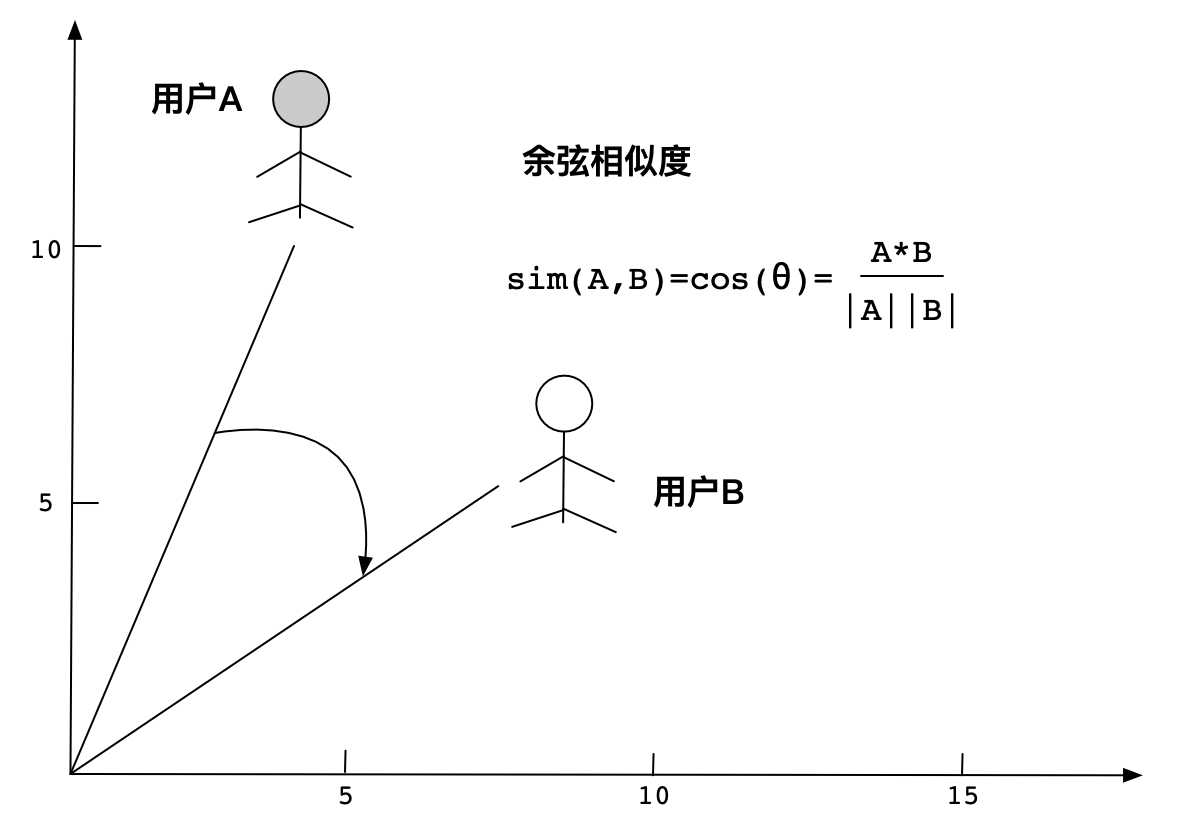
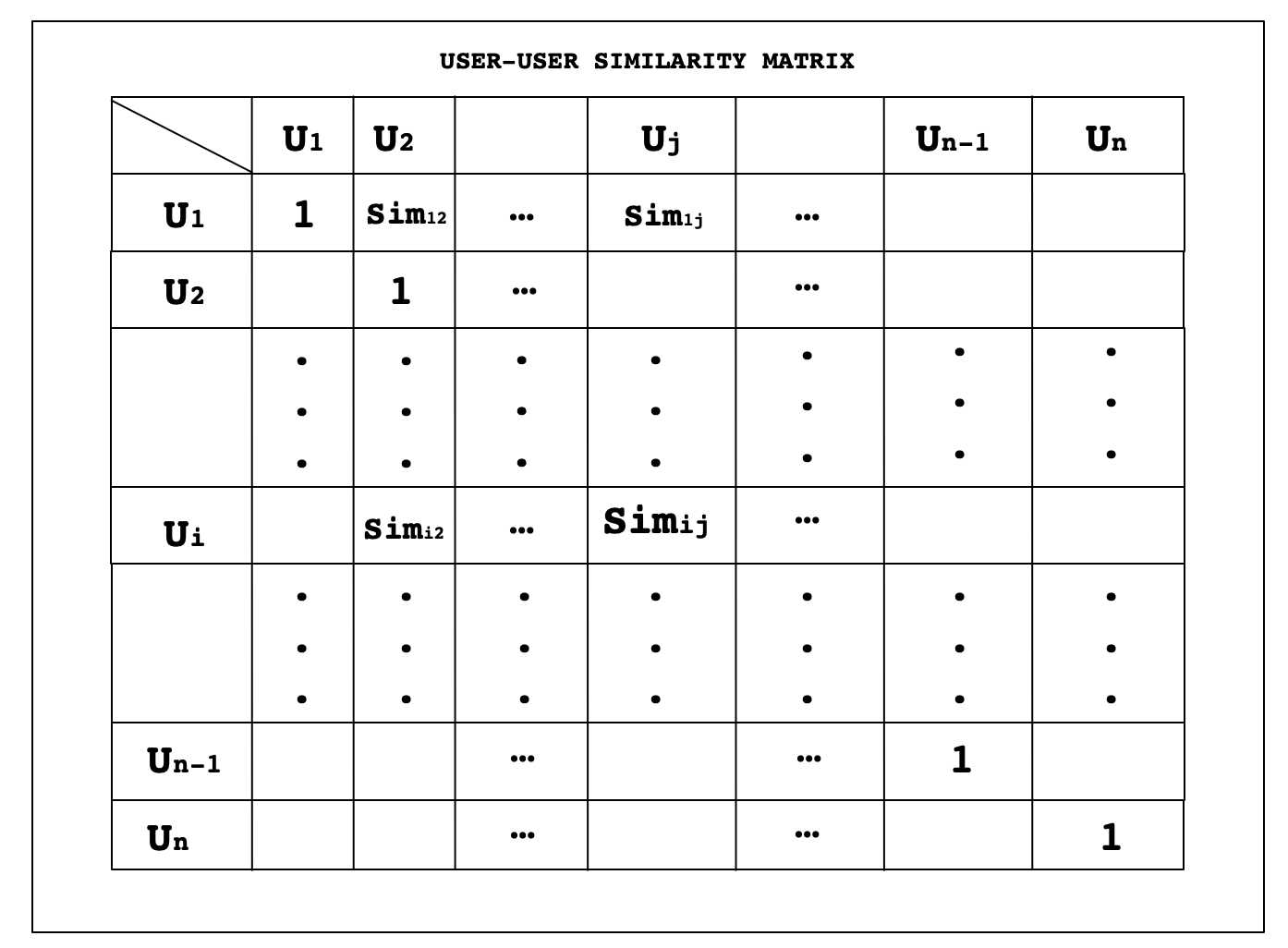
在这里,两个用户将是相似的基础上,他们给出了相似的评分。如果任何两个用户是相似的,那么这意味着他们都对物品给出了非常相似的评分,因为这里的用户向量只不过是USER-ITEM矩阵的一行,而该行又包含了用户对物品给出的评分。因为余弦相似度可以从0到1,并且1表示最高相似度,所以所有对角线元素都将是1,因为用户与用户之间的相似度最高。这里Sim12是用户U1和用户U2的相似性得分。以此类推,Simij是用户Ui和用户Uj的相似性得分。
第二步:找到相似用户
第三步:选择相似用户喜欢的物品
第四步:推荐物品
2.3.3.2 物品相似
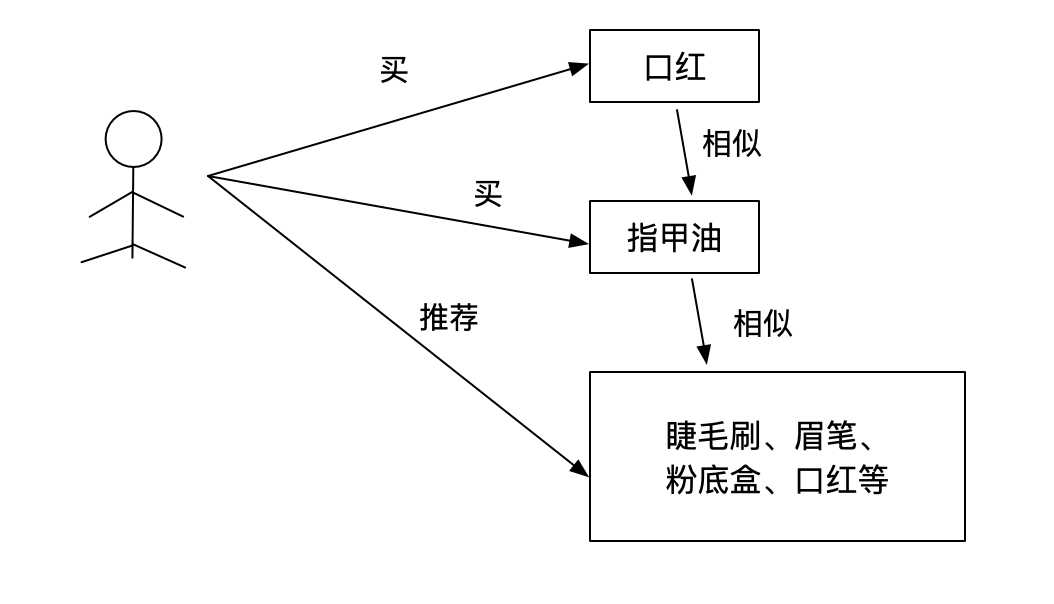
第一步:创建物品之间的相似矩阵
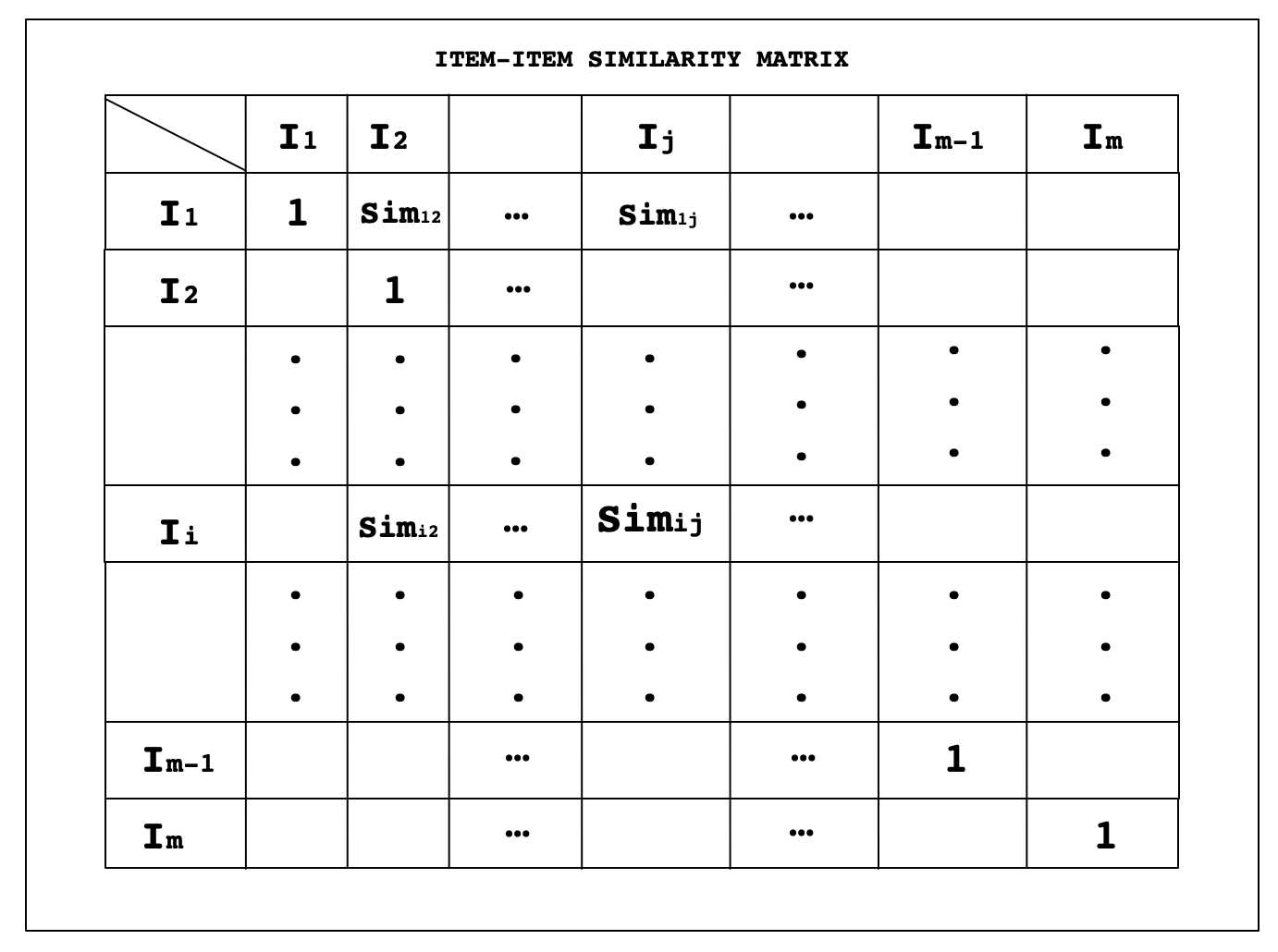
在这里,两个物品将在所有用户对两个物品给出相似评分的基础上相似。如果任何两个物品是相似的,那么这意味着所有用户对它们都给出了非常相似的评分,因为这里的物品向量只是USER-ITEM矩阵的列,而USER-ITEM矩阵的列又包含用户对物品的评分。因为余弦相似度可以从0到1,并且1表示最高相似度,所以所有对角线元素都将是1,因为具有相同项的相似度最高。这里Sim12是用户I1和用户I2的相似性得分。以此类推,Simij是用户Ii和用户Ij的相似性得分。
第二步:找出相似的物品然后推荐
2.3.4 矩阵分解
关于矩阵分解是比较有意思的,这里我们可以来看看一个计算公式:
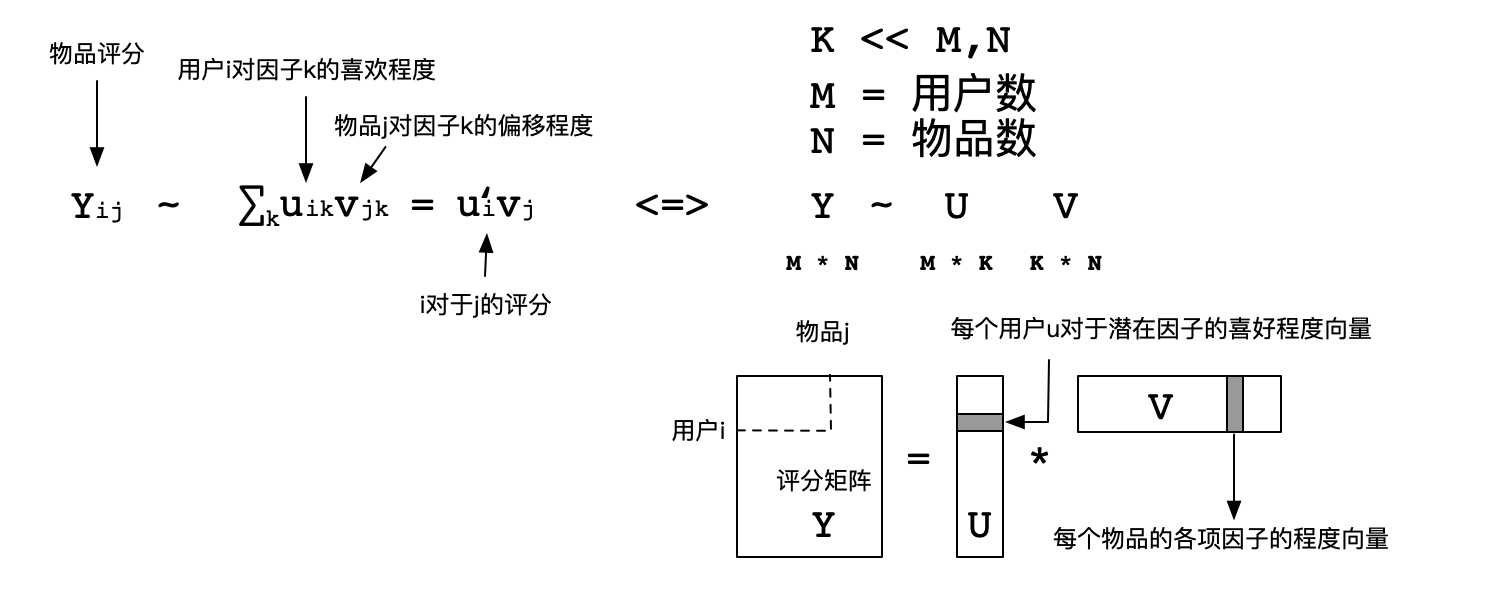
这里以日常生活中的电影来作为例子。例如,每个用户看电影的时候都有偏好,这些偏好可以直观的理解成:喜剧、动作、爱情、动漫等。特性矩阵(用户)表示的就是用户对这些因素的喜欢程度。同样,每一部电影也可以用这些因素描述,因此物品矩阵表示的就是每一部电影这些因素的含量,也就是电影的类型。这样子两个矩阵相乘就会得到用户对这个电影的喜欢程度。
3.总结
推荐系统的类型,简要概述如下:
- 协同过滤:简单来说,就是利用某兴趣相投,拥有功能经验的群体喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的评分,并记录下来以达到过滤的目的,进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的记录也是相当重要。
- 内容过滤:通过在抓取每个物品的一系列特征来构建物品档案,以及用户购买的商品特征来构建基于内容的用户档案。用户档案和商品档案都以使用信息提取技术或信息过滤技术,提取的关键词集合来表示。鉴于两个档案都以权重向量的形式来表,则相似度分别则可以使用如余弦近似度方程等启发式方程来计算得到。其他的技术如分类模型,构建一个统计方法或者数据挖掘方法,来判断文档内容和用户是否相关。
- 相似过滤:找到和目标用户兴趣相似的用户集合,以及找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户(基于用户相似)。计算物品之间的相似度,以及根据物品的相似度和用户的历史行为给用户生成推荐列表(基于物品相似)。
- 矩阵分解:简单来说,就是每一个用户和每一个物品都会有自己的一些特性,用矩阵分解的方法可以从评分矩阵中分解出用户(如特性矩阵、物品矩阵)。这样做的好处其一是得到了用户的偏好和每一件物品的特性,其二是分解了矩阵的维度。
4.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。
以上是关于如何构建推荐系统的主要内容,如果未能解决你的问题,请参考以下文章