设计模式中巧记I/O
Posted luckycoder
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了设计模式中巧记I/O相关的知识,希望对你有一定的参考价值。
一、I/O
1. I/O操作中的设计模式
概要
- 以设计模式角度,自顶向下理解I/O源码结构
- 理解字节与字符的关系
1.1 装饰者模式(输入流为例)
- 背景:通过继承扩展对象耦合度高,使用装饰者扩展可以在不改变现有结构的情况下,动态地给对象增加额外功能,耦合度底且灵活,一个具体对象可以有多个装饰者
- 字节流
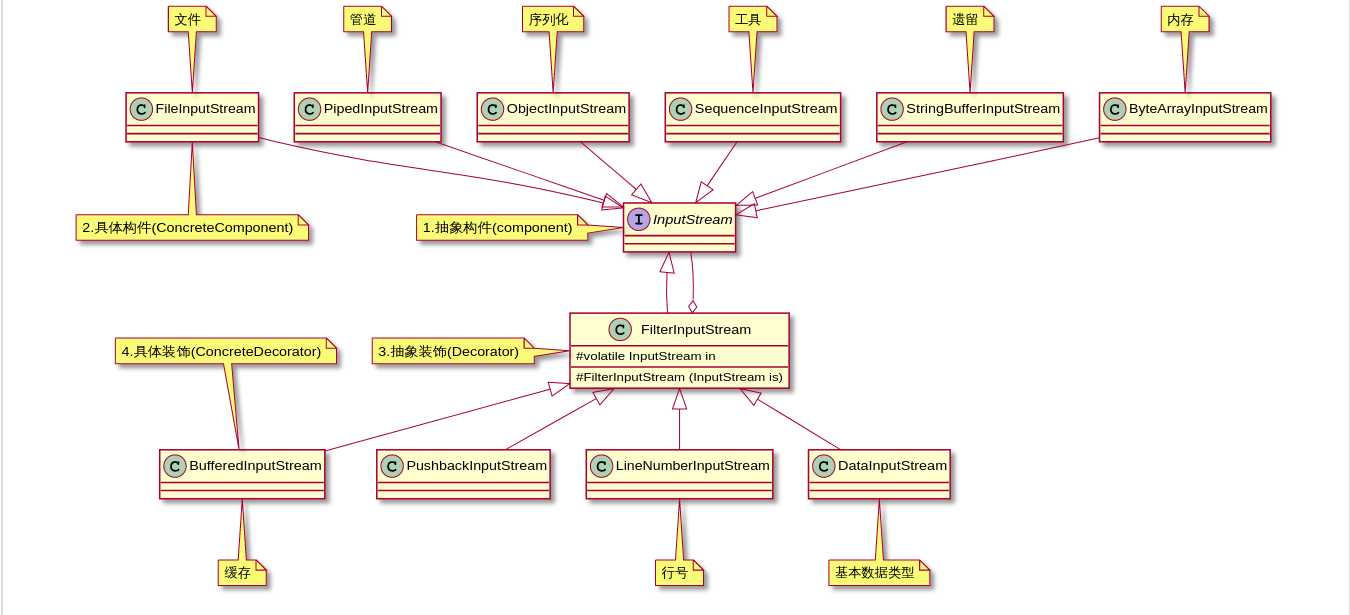
抽象构件:第二行,InputStream接口,定义字节流的基本操作抽象装饰者:第三行,与抽象构建接口是组合关系,动态的传入具体构件。第四行通过扩展抽象构件子类,为具体构件添加新的功能具体构件:第一行,实现抽象构件操作,具体装饰者为每一个具体的构件添加新的职责具体装饰者:第四行,有新职责的具体构建
- 装饰者模式为字节流带来的增强
-
- 使用
InputStream时,是以一个字节一个字节形式读或写,而BufferedInputStream与BufferedOutputStream为字节流提供了缓冲区,读数据时一次性读取一块数据放到缓冲区中,当缓存区读取完后,输入流会再次填充缓冲区,直到输入流被读取完,缓冲区可以减少IO操作。
- 使用
-
DataInputStream,从字节流中灵活的读取并重建Java的基本类型与String类型数据
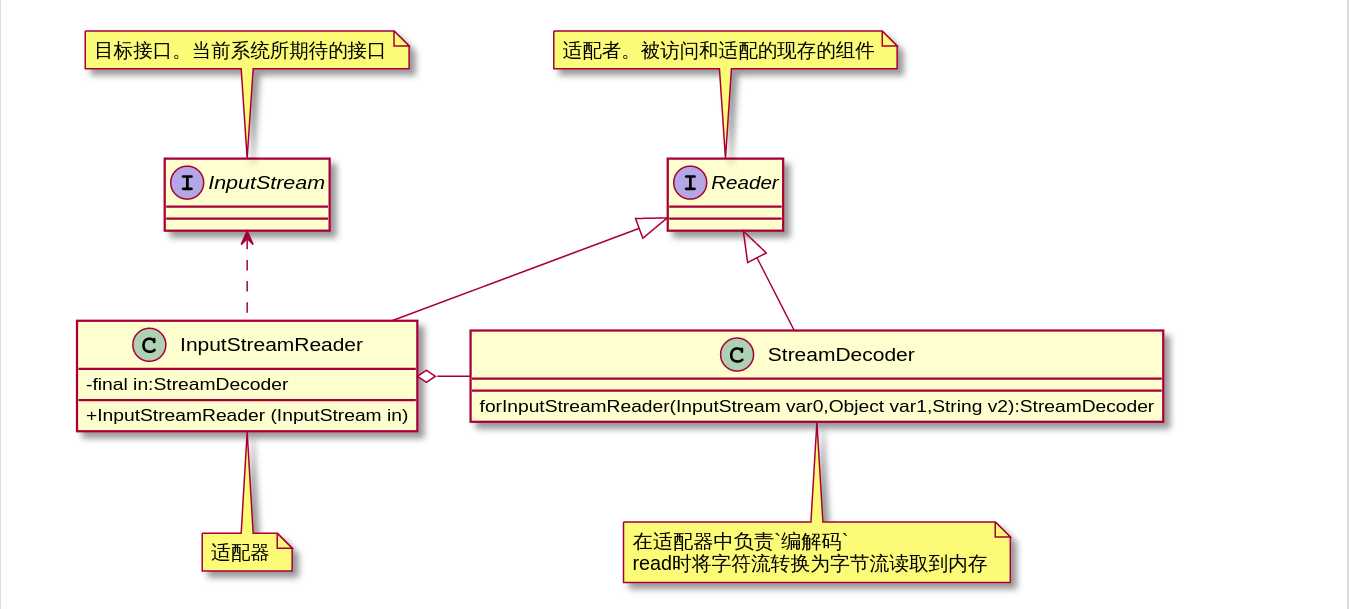
1.2 适配器模式(输入流为例)
- 背景:需要开发的业务功能在组件库中已经存在,但与新的接口规范不兼容,重新开发成本太高,所以使用适配器模式能解决这些问题
- 已有字符流读写接口
Reader与Writer,新的需求是字节流访问数据源,然后由字符流处理
- 为什么使用自符流
-
- 根本原因:内存中数据操作是以字节为单位(给机器看的);一般持久化到磁盘不同的编码对应不同的字符(给人类看的),也可以以字节形式持久化到硬盘,供软件与硬件阅读。
-
- 字节流操作单元为字节(8byte)。InputStream中的read()方法,是以
一个字节为单位读取,读到末尾返回-1、它的重载方法read(byte[])内部是通过for循环调用read()实现一次读入一个字节数组,按字节的read()方法的会有频繁IO操作,普通IO模型也会阻塞线程,直到返回一个字节数据或-1,效率太低
- 字节流操作单元为字节(8byte)。InputStream中的read()方法,是以
-
- 字符流操作单元为Unicode码点(16byte),使用缓存读写。将数据持久化到磁盘 ,使用字节写入会乱码,因为不同语言(汉语、英语等)都有自己对应的编码表,例如英文一个字母可以用一个字节表示,但汉语需要用两个字节,甚至一些特殊符号需要更多字节(Unicode的辅助字符),一个字节一个字节写入很大可能会乱码。所以字符符流会先根据对应的码表将内容写入缓冲区,缓冲区满了持久化到磁盘。使用字符流有两个好处
-
- 利用缓存读写,避免内存与操作系统频繁IO操作,提高效率
-
- 写入时指定编码表可以有效避免乱码问题
-
适配器模式中字符流与字节流
-
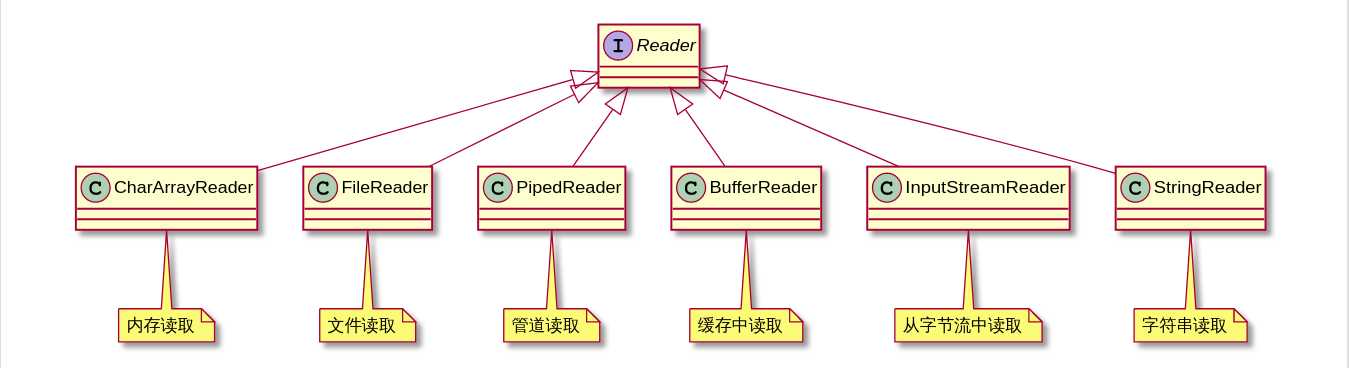
字符流
-
Reader
-
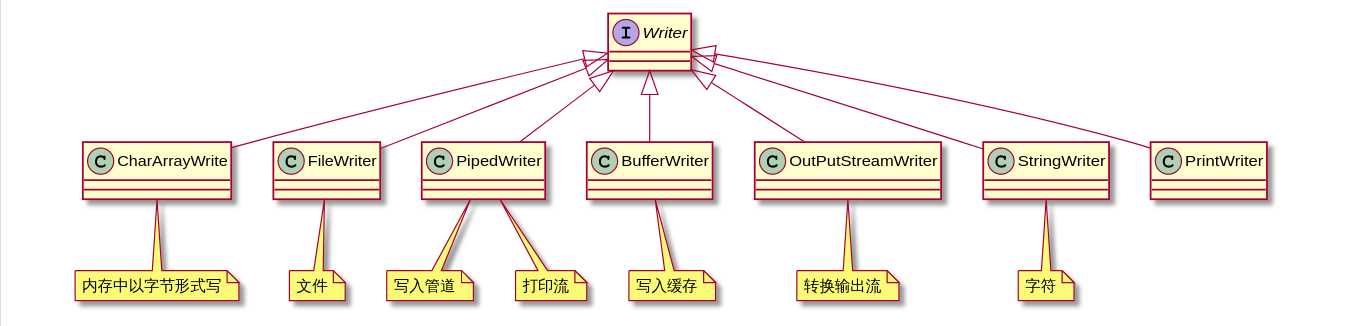
Writer
-PS:个人笔记,望读者勘误。本文只例举了字节输入流与字符输入流两种,若读者理解了可以结合源码看输出流中设计模式
以上是关于设计模式中巧记I/O的主要内容,如果未能解决你的问题,请参考以下文章