第一爬成功,纪念一下
Posted scrap
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一爬成功,纪念一下相关的知识,希望对你有一定的参考价值。
看了B站很多免费视频,按照老师的方法试着写了一下,总共耗时3天,当中写入excel文件,出现各种问题,各种错误,查阅了网上各种资源,消耗了两天时间,小白就是小白,基本功不扎实,写代码时碰到问题只能网上到处翻。不过学习python纯属于个人业余爱好,不作为谋生活的工具,能顺利完成这个项目,还是有一点成就感的。我语法什么的只是了解一些,基础不牢固,是直接做项目,以问题为导向,碰到问题,就去查相关的资料,感觉这样挺浪费时间和精力的,还是要系统的学习,奠定坚实的基础才是正道。
总结如下:
- 需求分析
- 网站:http://125.35.6.84:81/xk/
- 按照老师的要求,需要爬取对应企业的详细页的全部信息
- 爬取前4页的企业信息数据并保存
- 导入excle中存储(自己想做的)
- 网站分析
- chrame 浏览器 F12
- 按照老师讲的,网页数据加载有静态加载和动态加载之分,网页源码中能找到想要的数据,就是静态加载数据,反之就是动态加载。刷新网页,如果网址没有变化就是AJAX,在XHR中找发送数据,动态加载采用chrome自带抓包工具。
- 该网站首页是发送数据是采用post,在Headers中可以看到真正的地址和发送方式及发送数据Form Data
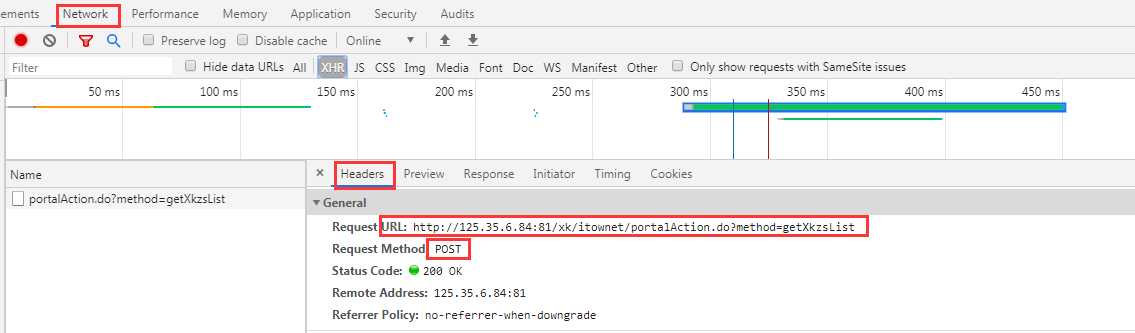
-
点击一个链接进入详细信息页面,查看源码,是采用ajax动态加载

-
- 点击response可看到应答数据为

response数据格式化后可以看出,是一个字典类型的数据,我们想要的数据在‘list[]’列表内
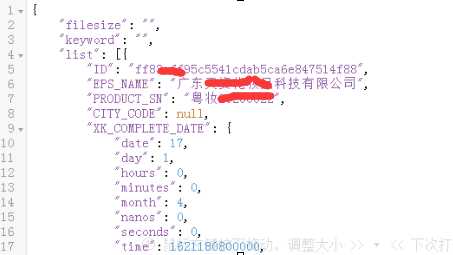
-
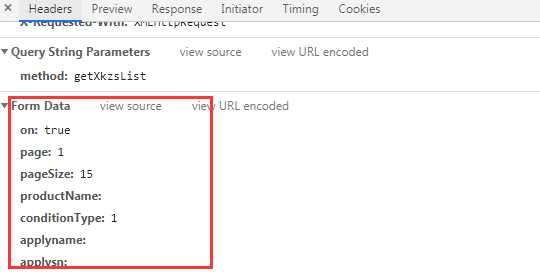
发送数据Formdata为

-
- 应答数据为json数据

格式化后为详细信息,是一个字典数据
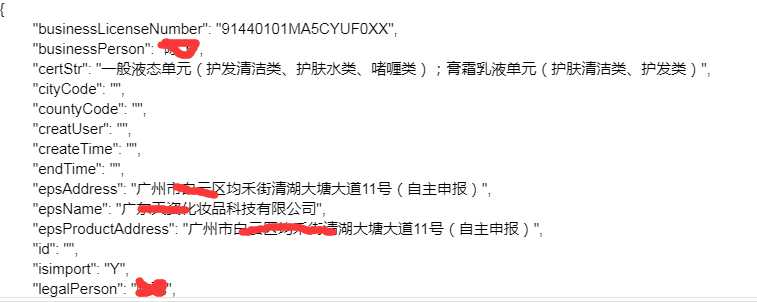
- 爬取首页
url = ‘http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList‘#定义地址
headers = {
‘user-agent‘: ‘****‘
}#定义头,头信息删除了
data = {
‘on‘: ‘true‘,
‘page‘: ‘1‘,
‘pageSize‘: ‘15‘,
‘productName‘: ‘‘,
‘conditionType‘: ‘1‘,
‘applyname‘: ‘‘,
‘applysn‘: ‘‘,
}#发送数据
response = requests.post(url=url, headers=headers, data=data)#post响应
page_data = response.json()#json解析
- 爬取详细页
1 for content in page_data[‘list‘]: 2 id_no.append(content[‘ID‘]) 3 url1 = ‘http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById‘ 4 for idx in id_no: 5 data1 = { 6 ‘id‘: idx 7 } 8 res = requests.post(url1, headers=headers, data=data1) 9 if res.headers[‘Content-Type‘] == ‘application/json;charset=UTF-8‘: 10 page_next = res.json() 11 # print(page_next) 12 content_all.append(page_next) 13 time.sleep(1)#因为采集多页信息时,发现服务器无响应,所以用了一个时间延迟,居然成功了
- 输出excel
为了输出excel,整整折腾了三天时间,查找了各种网络上的资源,用过pandas的DataFrame的to_excel,但是没用成功,可能是在循环遍历字典时赋值方法不对。最后还是转化为列表,采用xlwt的write()方法进行写入
1 wb = xlwt.Workbook(encoding=‘utf-8‘) 2 ws = wb.add_sheet(‘sheet1‘) 3 title = list(content_all[0].keys()) 4 for j in range(len(title)): 5 ws.write(0, j, title[j]) 6 for i in range(len(content_all)): 7 m = 0 8 for k in content_all[i].values(): 9 ws.write(i+1, m, k) 10 m += 1 11 wb.save(‘alldata.xls‘)


后记
纯粹是个人爱好,自娱自乐,有不对的和可以优化的地方,请多指导、帮助进步。
以上是关于第一爬成功,纪念一下的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫+数据分析:爬一爬那个很懂车的网站,分析一下现阶段哪款车值得我们去冲