从Tushare获取历史行情数据
Posted whitebear
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从Tushare获取历史行情数据相关的知识,希望对你有一定的参考价值。
从Tushare获取历史行情数据,分为两种,一种是后复权(daily_hfq)数据,一种是不复权(daily)数据,获取到的数据存储在MongoDB数据库中,每个集合(collection)中,数据字段包含如下:

抓取指数历史行情
流程图如下
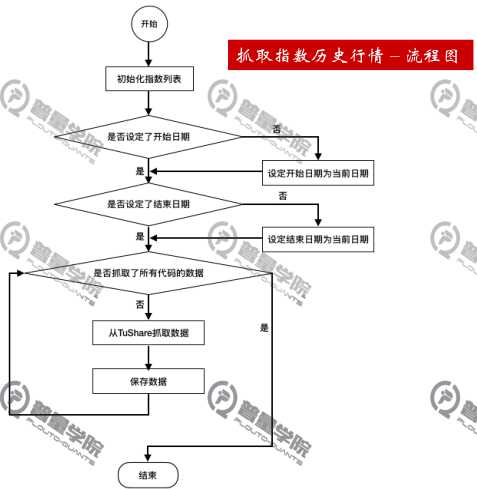
首先准备好数据库的连接,可查看python对MongoDB数据库的操作,这里在database文件中创建了对MongoDB数据的连接及指定存储的数据库
datebase.py文件
from pymongo import MongoClient
#指定数据库的连接,quant_01是数据库名
DB_CONN = MongoClient(‘mongodb://127.0.0.1:27017‘)[‘quant_01‘]
在daily_crawler.py文件中完成初始化、数据的获取、储存等操作。
import tushare as ts
from database import DB_CONN
from datetime import datetime
from pymongo import UpdateOne
class DailyCrawler:
def __init__(self):
#创建daily数据集(集合)
self.daily = DB_CONN[‘daily‘]
#创建daily_hfq数据集(集合)
self.daily_hfq = DB_CONN[‘daily_hfq‘]
获取指数历史行情数据(index= true)
def crawl_index(self,begin_date = None,end_date=None):
"""
抓取指数的日k数据
指数行情的主要作用:
1、用来生成交易日历
2、回测时作为收益的对比基准
:param begin_date:开始日期
:param end_date:结束日期
"""
#指定抓取的指数列表,可以增加和改变列表中的值
index_codes = [‘000001‘,‘000300‘,‘399001‘,‘399006‘,‘399006‘]
#当前日期
now = datetime.now().strftime(‘%Y-%m-%d‘)
#如果没有指定开始日期,则默认当前日期
if begin_date is None:
begin_date = now
#如果没有指定结束日期,则默认当前日期
if end_date is None:
end_date = now
#按指数的代码循环,抓取所有指数信息
for code in index_codes:
#抓取一个指数在一个时间区间的数据
df_daily = ts.get_k_data(code,index=True,start=begin_date,end=end_date)
#保存数据
self.save_data(code,df_daily,self.daily,{‘index‘:True})
获取股票历史数据(index=False)
流程图如下:
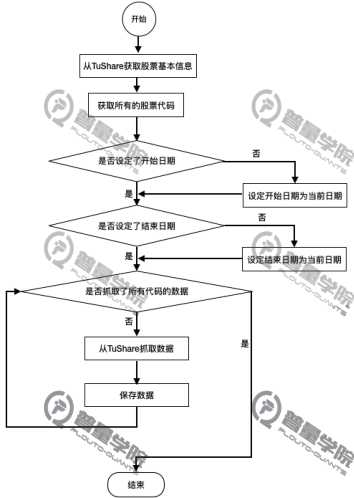
获取所有股票行情数据
调用tushare中get_stock_basics()获取所有股票的基本信息,然后将基本信息的索引列表转化为股票代码列表,就得到了所有股票代码
再调用get_k_data()获取不复权、后复权历史价格数据
def crawl(self,begin_date=None,end_date=None):
‘‘‘
抓取股票的日k数据,主要包括不复权和后复权两种
:param begin_date:开始日期
:param end_date:结束日期
‘‘‘
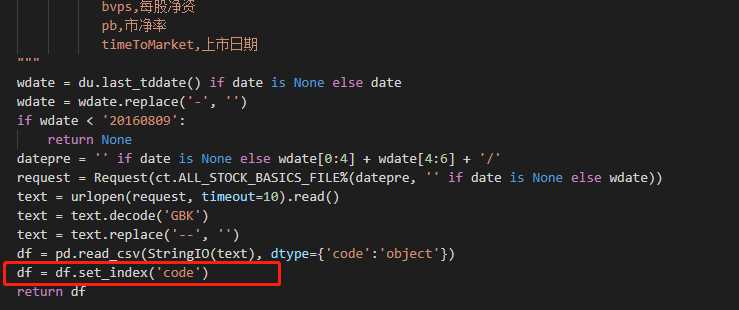
#通过tushare的基本信息API,获取股票的基本信息
stock_df = ts.get_stock_basics()
#将基本信息的索引列表转换为股票代码列表
codes = list(stock_df.index)
#当前日期
now = datetime.now().strftime("%Y-%M-%D")
#如果没有指定开始/结束日期,则默认为当前日期
if begin_date is None:
begin_date = now
if end_date is None:
end_date = now
for code in codes:
#不复权价格
df_daily = ts.get_k_data(code,start=begin_date,end=end_date,autype=None)
self.save_data(code,df_daily,self.daily,{‘index‘:False})
#后复权价格
df_daily_hfq = ts.get_k_data(code,start=begin_date,end=end_date,autype=‘hfq‘)
self.save_data(code,df_daily_hfq,self.daily_hfq,{‘index‘:False})
这里曾经很好奇,为何(color{purple}{stock_df.index})就可以获得股票代码呢?
在get_stock_basics()实现源码中,作者将(color{purple}{code})设为了index,因此该语句才能有效的获取股票代码
保存数据
流程图:
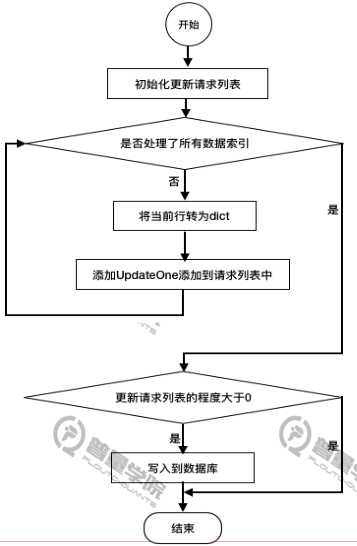
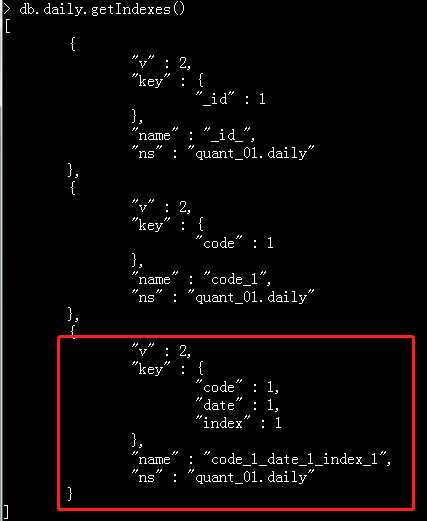
随着数据量的增加,写入速度会变慢,因此需要创建索引,这里对code、date、index三个字段加上索引
创建索引的命令式如下:
db.daily.createIndex({‘code‘:1,‘date‘:1,‘index‘:1})
可通过db.daily.getIndexes()查看索引
保存数据代码:
def save_data(self,code,df_daily,collection,extra_fields =None):
‘‘‘
将从网上抓取的数据保存在本地MongoDB中
:param code:股票代码
:param df_daily:包含日线数据的DataFrame
:param collection:储存的数据集
:param extra_fields:除k线数据中保存的字段,需要额外保存的字段
‘‘‘
#数据更新的请求列表
update_requests = []
#将DataFrame中的行情数据,生成更新数据的请求
for df_index in df_daily.index:
#将DataFrame中的一行数据转换成dict类型:
doc = dict(df_daily.loc[df_index])
#设置股票代码
doc[‘code‘] = code
#如果指定了其他字段,则更行dict
if extra_fields is not None:
doc.update(extra_fields)
#生成一条数据库的更新请求
#注意:
#需要在code、date、index三个字段上增加索引,否则随着数据量的增加,写入速度会变慢
#创建索引的命令式:
#db.daily.createIndex({‘code‘:1,‘date‘:1,‘index‘:1})
update_requests.append(
UpdateOne(
{‘code‘:doc[‘code‘],‘date‘:doc[‘date‘],‘index‘:doc[‘index‘]},
{‘$set‘:doc},
upsert = True
)
)
#如果写入的请求列表不为空,则都保存在数据库中
if len(update_requests)>0:
#批量写入到数据库中,批量写入可以降低网络IO,提高速度
update_result = collection.bulk_write(update_requests,ordered=False)
print(‘保存日线数据,代码:%s ,插入:%4d 条,更新:%4d 条‘%(code,update_result.upserted_count,update_result.modified_count),flush=True)
程序入口
if __name__ == "__main__":
dc = DailyCrawler()
dc.crawl_index(‘2015-01-01‘, ‘2015-01-06‘)
dc.crawl(‘2015-01-01‘, ‘2015-01-06‘)
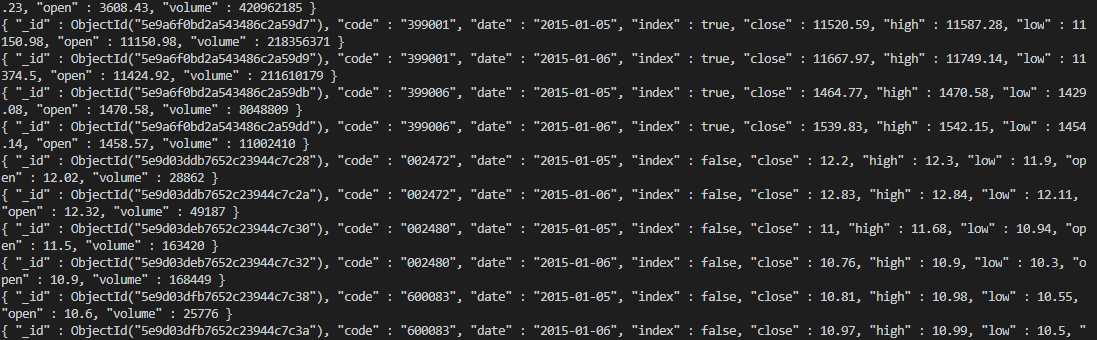
运行效果:
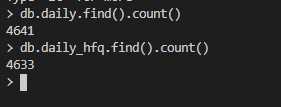
查看有多少条数据:
以上是关于从Tushare获取历史行情数据的主要内容,如果未能解决你的问题,请参考以下文章