图的应用——最小生成树
Posted wangzheming35
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图的应用——最小生成树相关的知识,希望对你有一定的参考价值。
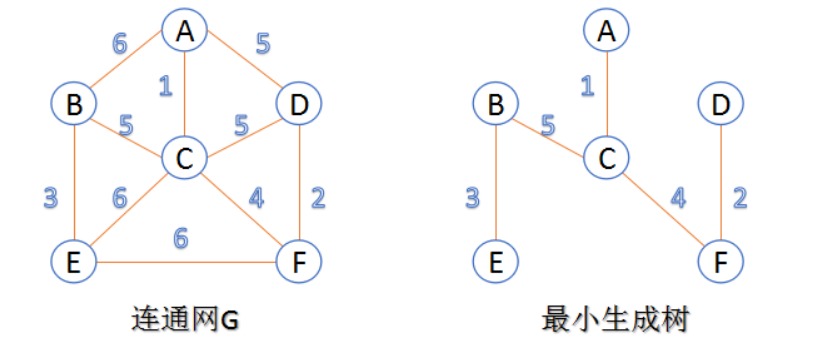
一、最小生成树
先明白生成树的概念:对连通图进行遍历,过程中所经过的边和顶点的组合可看做是一棵普通树,通常称为生成树。
那么,在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树(MST)。
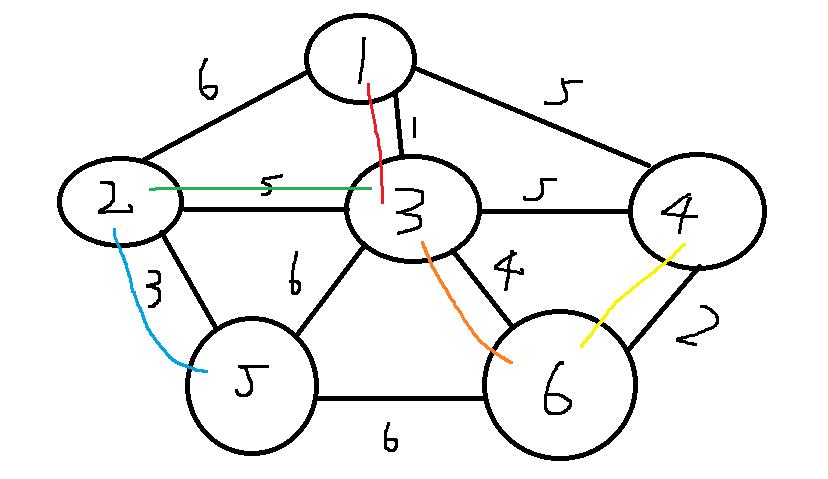
如下图所表示:
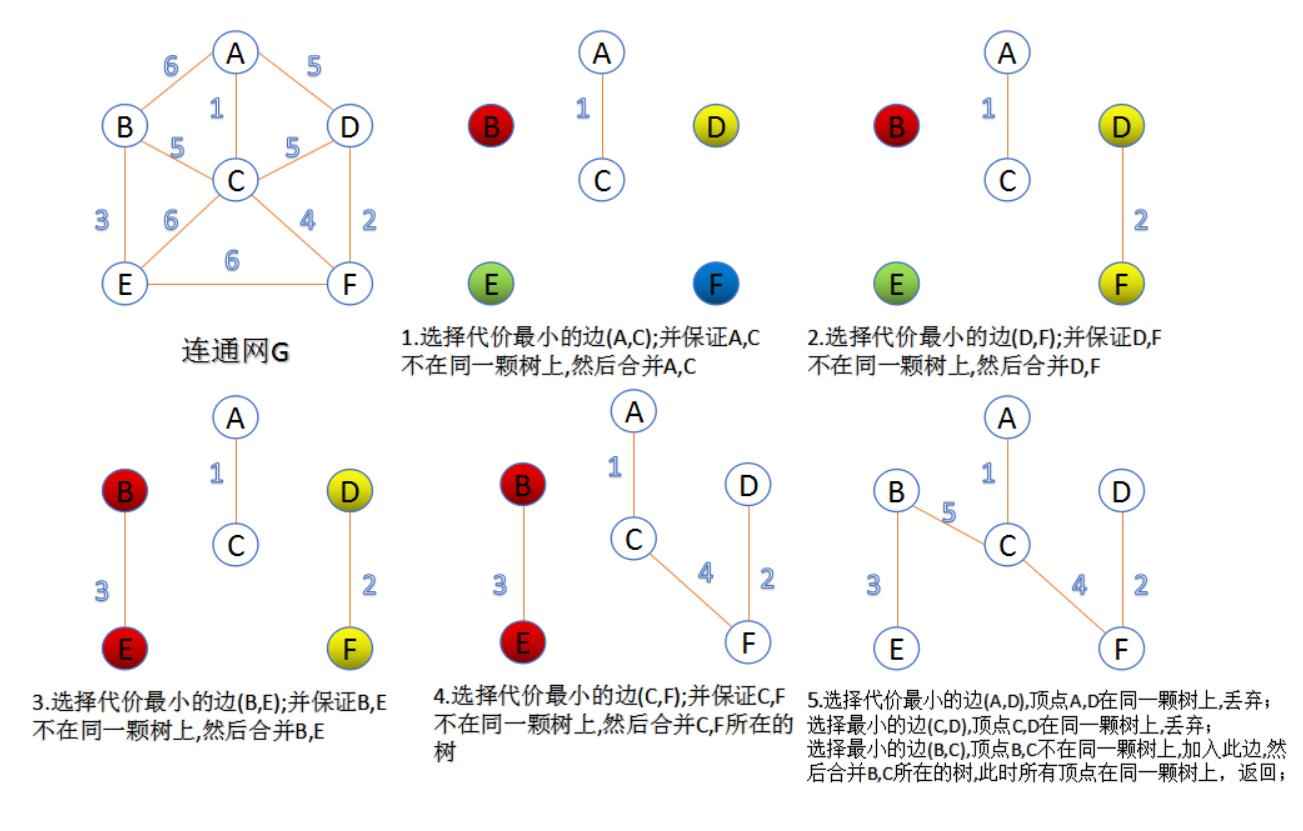
二、克鲁斯卡尔算法(Kruskal算法)求最小生成树
Kruskal算法特点:将边归并,故名“加边法”,适于求稀疏网的最小生成树。
实例看步骤:
运用Java代码实现:
import java.util.ArrayList;
import java.util.Collections;
public class Kruskal {
public static void main(String[] args) {
int[][] edges = {
{0, 1, 6},
{0, 2, 1},
{0, 3, 5},
{2, 1, 5},
{2, 3, 5},
{2, 4, 5},
{2, 5, 4},
{1, 4, 3},
{4, 5, 6},
{5, 3, 2}
};
int n = 6; //结点个数
int[][] mstEdges = kruskal(n, edges);
int totalCost = 0;
System.out.println("Edges of MST: [node1, node2, cost]");
//输出构树的边集
for (int i = 0; i < mstEdges.length; i++) {
int[] edge = mstEdges[i];
for (int j = 0; j < edge.length; j++) {
System.out.print(edge[j] + " ");
}
totalCost += edge[2];
System.out.println();
}
System.out.println("Total cost of MST: " + totalCost); //求最小生成树权数
}
public static int[][] kruskal(int n, int[][] edges) {
/**
* @Description: 克鲁斯卡尔算法求最小生成树
* @Param: [n, edges] ==> [结点个数, 边集]
* @return: int[] 构成最小生成树的边集
* @Author: 借鉴CSDN作者Aiven
*/
int[] pres = new int[n]; //并查集
int[] ranks = new int[n]; //结点的秩
// 初始化:pres一开始设置每个元素的上一级是自己,ranks一开始设置每个元素的秩为0
for (int i = 0; i < n; i++) {
pres[i] = i;
ranks[i] = 0;
}
//用自己定义的MyEdge类里面的compareTo排序,按边权排序
ArrayList<MyEdge> edgesList = new ArrayList<>();
for (int i = 0; i < edges.length; i++) {
edgesList.add(new MyEdge(edges[i]));
}
// 边集从小到大排序
Collections.sort(edgesList);
int[][] mstEdges = new int[n - 1][3];
int count = 0;
for (int i = 0; i < edgesList.size(); i++) {
int[] arr = edgesList.get(i).array;
int a = arr[0], b = arr[1], c = arr[2];
if (find(a, pres) != find(b, pres)) {
unionSet(a, b, pres, ranks);
mstEdges[count] = arr;
count++;
}
if (count == n) {
break;
}
}
return mstEdges;
}
//并:合并两个集合,按秩合并
public static void unionSet(int n1, int n2, int[] pres, int[] ranks) {
int root1 = find(n1, pres);
int root2 = find(n2, pres);
//当两个元素不是同一组的时候才合并
if (root1 != root2) {
if (ranks[root1] < ranks[root2]) {
pres[root1] = root2;
} else {
pres[root2] = root1;
if (ranks[root1] == ranks[root2])
ranks[root1]++;
}
}
}
//查:查找元素的首级
public static int find(int x, int[] pres) {
int root = x;
while (pres[root] != root)
root = pres[root];
//路径压缩
int p = x;
while (pres[p] != p) {
int t = pres[p];
pres[p] = root;
p = t;
}
return root;
}
}
// 边的排序类
class MyEdge implements Comparable {
int[] array;
MyEdge(int[] array) {
this.array = array;
}
@Override
public int compareTo(Object o) {
o = (MyEdge) o;
int[] arr = ((MyEdge) o).array;
if (array[2] > arr[2]) {
return 1;
} else if (array[2] == arr[2]) {
return 0;
} else {
return -1;
}
}
}
// output:
//
// Edges of MST: [node1, node2, cost]
// 0 2 1
// 5 3 2
// 1 4 3
// 2 5 4
// 2 1 5
// 0 0 0
// Total cost of MST: 15
程序图解:
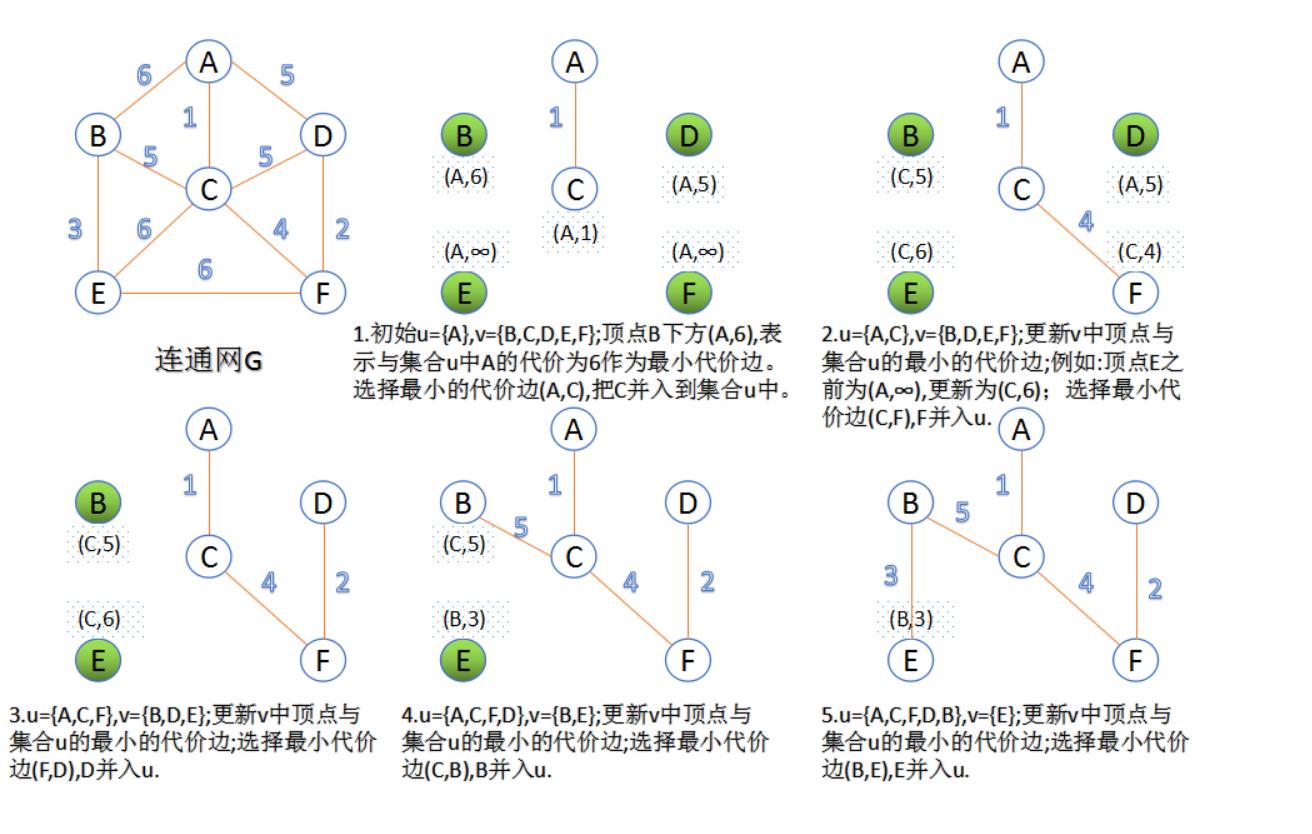
三、普里姆算法(Prim算法)求最小生成树
Prime算法特点:将顶点归并,故名“加点法”,与变数无关,适于稠密图。
实例看步骤:
运用Java代码实现:
/**
* 最小生成树的prim算法
* @author 借鉴博客园作者liuy
*/
public class Prim {
public static void prim(int num, float[][] weight) { //num为顶点数,weight为权
float[] lowcost = new float[num + 1]; //到新集合的最小权
int[] closest = new int[num + 1]; //代表与s集合相连的最小权边的点
boolean[] s = new boolean[num + 1]; //s[i] == true代表i点在s集合中
s[1] = true; //将第一个点放入s集合
for(int i = 2; i <= num; i++) { //初始化辅助数组
lowcost[i] = weight[1][i];
closest[i] = 1;
s[i] = false;
}
for(int i = 1; i < num; i++) {
float min = Float.MAX_VALUE;
int j = 1;
for(int k = 2; k <= num; k++) {
if((lowcost[k] < min) && (!s[k])) {//根据最小权加入新点
min = lowcost[k];
j = k;
}
}
//新加入点的j和与j相连的点
System.out.println("加入点" + j + ". " + j + "---" + closest[j]);
s[j] = true;//加入新点j
for(int k = 2; k <= num; k++) {
if((weight[j][k] < lowcost[k]) && !s[k]) {//根据新加入的点j,求得最小权
lowcost[k] = weight[j][k];
closest[k] = j;
}
}
}
}
public static void main(String[] args) {
float m = Float.MAX_VALUE;
//该图的矩阵
float[][] weight = {{0, 0, 0, 0, 0, 0, 0},
{0, m, 6, 1, 5, m, m},
{0, 6, m, 5, m, 3, m},
{0, 1, 5, m, 5, 6, 4},
{0, 5, m, 5, m, m, 2},
{0, m, 3, 6, m, m, 6},
{0, m, m, 4, 2, 6, m}};
prim(weight.length - 1, weight);
}
}
// output:
//
//加入点3. 3---1
//加入点6. 6---3
//加入点4. 4---6
//加入点2. 2---3
//加入点5. 5---2
//自行算出权值15
程序图解:
四、C语言核心代码
代码学习于王道数据机构,仅供参考。
1、Kruskal
#define MaxSize 100
typedef struct {
int a,b; //边的两个顶点
int weight; //边的权值
}Edge; //边结构体
int Find(int *parent,int x){
while(parent[x]>=0) x=parent[x]; //循环向上寻找下标为x顶点的根
return x; //while循环结束时找到了根的下标
}
Edge edges[MaxEdge]; //边数组
int parent[MaxVex]; //父亲顶点数组(并查集)
void MiniSpanTree_Kruskal(MGraph G){
int i , n , m;
sort(edges); //按权值由小到大对边排列
for(i=0 ; i<G.vexnum ; i++)parent[i]=-1; //初始化:各个顶点单独形成一个集合
for(i=0 ; i<G.arcnum ; i++){ //扫描每条边
n=Find(parent,edges[i].a); //n是这条边的第一个顶点的根顶点所在下标
m=Find(parent,edges[i].b); //m是这条边第二个顶点的根顶点所在下标
if(n!=m){ //根顶点不相同 这条边不会构成环
parent[n]=m; //并操作
//作为生成树的一条边打印出来
printf(“(%d->%d) ”,edges[i].a,edges[i].b);
}
}
}
Kruskal算法操作分为对边的权值排序部分和一个单重for循环,它们是并列关系,由于排序耗费时间大于单重循环,所以克鲁斯卡尔算法的主要时间耗费在排序上。排序和图中边的数量有关系,所以适合稀疏图。
2、Prim
void MiniSpanTree_Prim(MGraph G){
int min,i,j,k;
int adjvex[MAXVEX]; //保存邻接顶点下标的数组
int lowcost[MAXVEX]; //记录当前生成树到剩余顶点的最小权值
lowcost[0]=0; //将0号顶点(以0号顶点作为第一个顶点)加入生成树
adjvex[0]=0; //由于刚开始生成树只有一个顶点 不存在边 干脆都设为0
for(i=1;i<G.vexnum;i++){ //除下标为0以外的所有顶点
lowcost[i]=G.arc[0][i]; //将与下标为0的顶点有边的权值存入Lowcost数组
adjvex[i]=0; //这些顶点的adjvex数组全部初始化为0
}
//算法核心
for(i=1;i<G.vexnum;i++){//只需要循环N-1次,N为顶点数
min=65535; //tip:因为要找最小值,不妨先设取一个最大的值来比较
j=0;k=0;
//找出lowcost最小的 最小权值给min,下标给k
while(j<G.vexnum){ //从1号顶点开始找
if(lowcost[j]!=0 && lowcost[j]<min){
//不在生成树中的顶点而且权值更小的
min=lowcost[j]; //更新更小的值
k=j; //找到了新的点下标给k
}
j++; //再看下一个顶点
}
printf(“(%d->%d)”,adjvex[k],k); //打印权值最小的边
lowcost[k]=0; //将这个顶点加入生成树
//生成树加入了新的顶点 从下标为1的顶点开始更新lowcost数组值
for(j=0;j<G.vexnum;j++){
if(lowcost[j]!=0 && G.arc[k][j]<lowcost[j]){
//如果新加入树的顶点k使得权值变小
lowcost[j]=G.arc[k][j]; //更新更小的权值
adjvex[j]=k;
//修改这条边邻接的顶点 也就是表示这条边是 从选出的顶点k指过来的 方便打印
}
}
}
}
双重循环,外层循环次数为n-1,内层并列的两个循环次数都是n。故普利姆算法时间复杂度为O(n2)而且时间复杂度只和n有关,所以适合稠密图。
以上是关于图的应用——最小生成树的主要内容,如果未能解决你的问题,请参考以下文章