论文阅读 | Employing the Correspondence of Relations and Connectives to Identify Implicit Discourse Rela
Posted bernieloveslife
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读 | Employing the Correspondence of Relations and Connectives to Identify Implicit Discourse Rela相关的知识,希望对你有一定的参考价值。
论文地址 :https://www.aclweb.org/anthology/P19-1411
作者 : Linh The Nguyen, Linh Van Ngo, Khoat Than, Thien Huu Nguyen
机构 : Hanoi University of Science and Technology, University of Orego
研究的问题:
主要关注的是语篇分析的问题。语篇分析是研究文档中的语篇单位,以及单位之间互相的联系,来提高文档的连贯性。本文是在隐性语篇关系识别(implicit discourse relation recognition,IDRR)这个任务上展开实验,目的是识别文档中相邻语篇跨度之间的关系。这里举了一个例子。
Argument 1: Never mind.
Argument 2: You already know the answer
对于这两个文本跨度(text span),称为参数,IDRR模型应该将参数2识别为参数1的原因。
这个任务本身比较困难,但如果有连接词(but、so)来连接这两个参数的话,这个任务就比较容易处理的。
当前这方面典型的方法是同时预测输入参数的语篇关系和隐含的连接词,两个预测任务的模型参数是共享的,以便于知识迁移。然而在IDRR的多任务学习模型中,没有能够充分利用隐含连接词和语篇关系之间的相关性。
本文的方法是将隐含连接词和语篇关系嵌入到同一空间,通过映射在两者之间传递知识。
研究方法:
多任务学习框架:
设A_1和A_2是两个输入参数(也就是文本序列),任务目标就是预测两者之间的关系r,用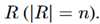 表示所有可能的n种关系。隐含的连接词定义为c,用
表示所有可能的n种关系。隐含的连接词定义为c,用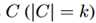 表示所有的k种连接词。
表示所有的k种连接词。
首先将A_1和A_2通过编码器M得到它们它们的向量表示V,V=M(A_1,A_2)。然后将向量V输入到两个前馈网络F_r和F_c中,分别生成关系r和连接c的表示向量V_r和V_c。之后将V_r和关系嵌入矩阵E_r相乘,V_c和隐连接词嵌入矩阵E_c相乘,得到概率分数,通过softmax得到结果。
训练目标是最小化负对数似然:
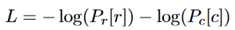
在编码器M的具体实现上,使用的是Bai and Zhao(2018)提出的编码器,具体是将词通过word2vec和ELMO和subword表示组成输入,通过CNN得到表示向量。
知识传递:
对于每个连接词c_i,E_c[c_i]是其向量表示,令R_i是与其对应的关系集合R的子集,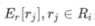 是其中每个元素的向量表示。
是其中每个元素的向量表示。
训练目标的损失函数如下:
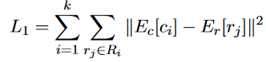
这里的k是向量的L2模数。
然而这个方程有退化解,也就是对应于某个关系的连接词的表示和关系表示有相同的向量表示。为了避免这一情况,增加下面的约束:
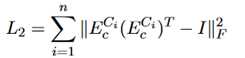
这里的I是单位矩阵。
此外,由于IDRR中的语篇关系倾向于表示不同的内容,增加下面的约束来促进关系表示的多样性。
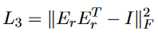
最终的目标函数是上述函数的加权组合:
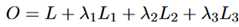
实验部分:
在PDTB2.0数据集上展开评估,它是IDRR中常用的一个大数据集。实验结果如下:
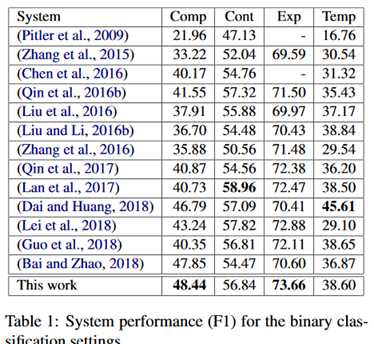
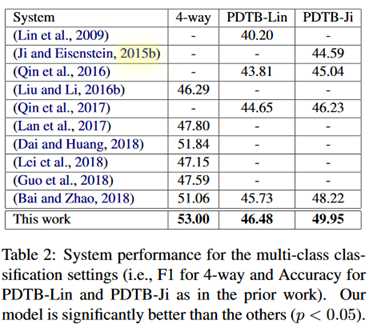
两张表中可以看到,相比于Bai and Zhao的工作提升比较明显,之所以和这个比因为本文的编码器和这个工作是相同的,比较起来比较直接。
评价:
模型在目标函数的设计上有许多创新的地方,针对特定的问题设计相应的损失函数,比如L2和L3的加入,使得结果中对应的向量尽可能是正交的,对应到语义上,不同的连接词和关系倾向于表达不同的语义和功能。并且作者做了补充实验讨论L1、L2、L3各自的作用,结果显示仅使用L时的结果与baseline基本相同,体现出连接词和关系的嵌入矩阵对于结果的提升相当有限。缺点在于这几个损失函数是针对PDTB数据集设计的,没有在其他数据集上的表现,泛化能力有待考证。
以上是关于论文阅读 | Employing the Correspondence of Relations and Connectives to Identify Implicit Discourse Rela的主要内容,如果未能解决你的问题,请参考以下文章