爬取知乎热搜
Posted lansihan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取知乎热搜相关的知识,希望对你有一定的参考价值。
一、主题式网络爬虫设计方案
1.主题式网络爬虫名称:微博热搜
2.爬取内容:爬取热搜名称、热度和排名
3.爬虫设计方案概述:先查找源代码,找到关键内容的索引标签,进行分析,提取需要的数据。然后对数据进行清洗和处理,以及可视化处理
4.难点:回归方程不熟练,知识点掌握不全。
二、主题页面的结构特征分析
1.爬取的网页https://s.weibo.com/top/summary?cate=realtimehot
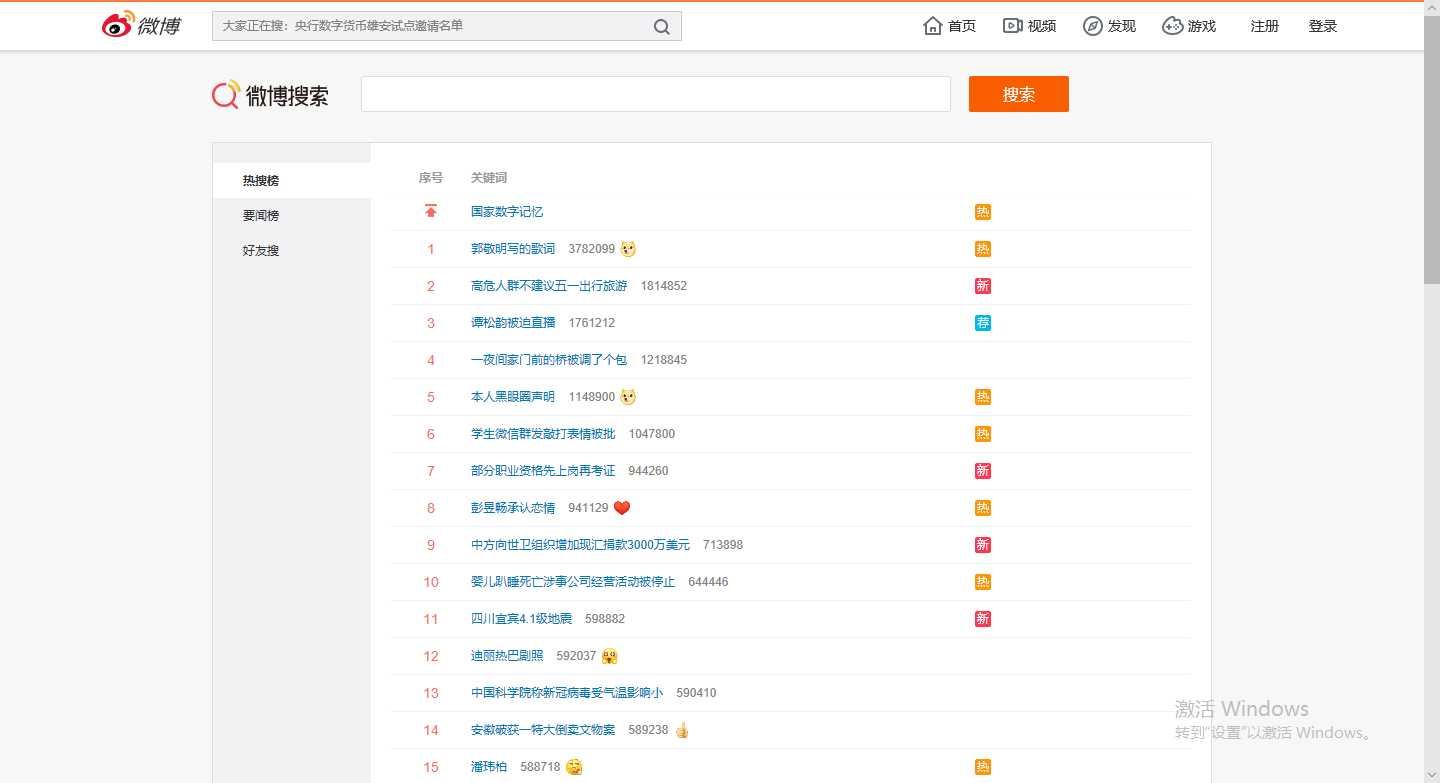
2.查看源代码
三、网络爬虫程序设计
1.数据爬取与采集
from bs4 import BeautifulSoup
from urllib.request import urlopen
import re
url="https://s.weibo.com/top/summary?cate=realtimehot"
html=urlopen(url).read().decode(‘utf-8‘)
soup=BeautifulSoup(html,features=‘lxml‘)
information=soup.find_all(‘tr‘)
information=information[2:]
rank=[]
news=[]
zan_num=[]
for each in information:
rank_temp=each.find(‘td‘,{‘class‘:‘td-01 ranktop‘})#获取排名
if each.find(‘a‘,{‘target‘:‘_blank‘}) is None: #获取新闻
news.append(each.find(‘a‘)[‘word‘])
else:
news.append(each.find(‘a‘,{‘target‘:‘_blank‘}).get_text())
num=each.find(‘span‘)#获取新闻
rank.append(rank_temp.get_text())
zan_num.append(num.get_text())
("{0:<10} {1:{3}<30} {2:{3}>11}".format(‘rank‘,‘name‘,‘num‘, chr(12288)))
for i in range(len(rank)):
print("{0:<10} {1:{3}<30} {2:{3}>11}".format(rank[i],news[i],zan_num[i],chr(12288)))
import pandas as pd
data = pd.DataFrame()
data[‘rank‘] = rank
data[‘name‘] = news
data[‘number‘] = zan_num
data.to_excel(‘weibohot.xlsx‘, index=False)
爬取的数据
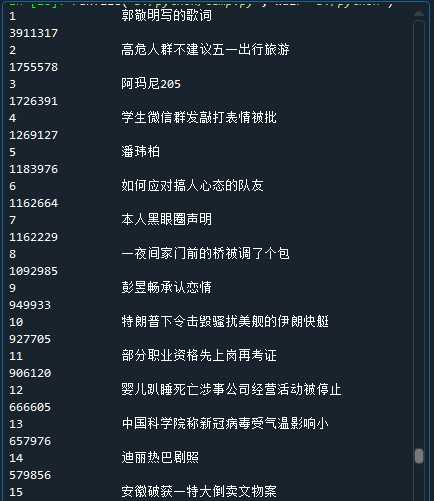
将热搜前五存入excel

2.对数据进行清洗和处理
import numpy as np
import pandas as pd
weibohot=pd.DataFrame(pd.read_excel(‘weibohot.xlsx‘))
weibohot.duplicated()
weibohot.drop_duplicates()
weibohot.isnull()
weibohot.notnull()
import pandas as pd
weibohot=pd.DataFrame(pd.read_excel(‘weibohot.xlsx‘))
weibohot.duplicated()
weibohot.drop_duplicates()
weibohot.isnull()
weibohot.notnull()
3.数据分析与可视化
柱形图
from weibohot import Bar bar = Bar("微博热搜", ) bar.add("热度", ["郭敬明写的歌词", "高危人群不建议五一出行旅游", "阿玛尼205", "学生微信群发敲打表情被批", "潘玮柏"], [3911317,1755578,1726391,1269127,1183976]) bar.show_config() bar.render()
动态散点图
from pyecharts import EffectScatter v1 = ["郭敬明写的歌词", "高危人群不建议五一出行旅游", "阿玛尼205", "学生微信群发敲打表情被批", "潘玮柏"] v2 = [3911317,1755578,1726391,1269127,1183976] es = EffectScatter("动态散点图示例") es.add("effectScatter", v1, v2) es.render()
将以上各部分的代码汇总,附上完整程序代码
from bs4 import BeautifulSoup from urllib.request import urlopen import re url="https://s.weibo.com/top/summary?cate=realtimehot" html=urlopen(url).read().decode(‘utf-8‘) soup=BeautifulSoup(html,features=‘lxml‘) information=soup.find_all(‘tr‘) information=information[2:] rank=[] news=[] zan_num=[] for each in information: rank_temp=each.find(‘td‘,{‘class‘:‘td-01 ranktop‘})#获取排名 if each.find(‘a‘,{‘target‘:‘_blank‘}) is None: #获取新闻 news.append(each.find(‘a‘)[‘word‘]) else: news.append(each.find(‘a‘,{‘target‘:‘_blank‘}).get_text()) num=each.find(‘span‘)#获取新闻 rank.append(rank_temp.get_text()) zan_num.append(num.get_text()) ("{0:<10} {1:{3}<30} {2:{3}>11}".format(‘rank‘,‘name‘,‘num‘, chr(12288))) for i in range(len(rank)): print("{0:<10} {1:{3}<30} {2:{3}>11}".format(rank[i],news[i],zan_num[i],chr(12288))) import pandas as pd data = pd.DataFrame() data[‘rank‘] = rank data[‘name‘] = news data[‘number‘] = zan_num data.to_excel(‘weibohot.xlsx‘, index=False) import numpy as np import pandas as pd weibohot=pd.DataFrame(pd.read_excel(‘weibohot.xlsx‘)) weibohot.duplicated() weibohot.drop_duplicates() weibohot.isnull() weibohot.notnull()
from weibohot import Bar
bar = Bar("微博热搜", )
bar.add("热度", ["郭敬明写的歌词", "高危人群不建议五一出行旅游", "阿玛尼205", "学生微信群发敲打表情被批", "潘玮柏"], [3911317,1755578,1726391,1269127,1183976])
bar.show_config()
bar.render()
from pyecharts import EffectScatter
v1 = ["郭敬明写的歌词", "高危人群不建议五一出行旅游", "阿玛尼205", "学生微信群发敲打表情被批", "潘玮柏"]
v2 = [3911317,1755578,1726391,1269127,1183976]
es = EffectScatter("动态散点图示例")
es.add("effectScatter", v1, v2)
es.render()
四、结论
1.经过对主题数据的分析与可视化,可以得到哪些结论?
疫情期间过后人们对日常娱乐的关注量有回升至之前。
2.对本次程序设计任务完成的情况做一个简单的小结。
对知识点掌握不全,编写时有困难。爬虫是一个非常实用的工具。
以上是关于爬取知乎热搜的主要内容,如果未能解决你的问题,请参考以下文章